Clear Sky Science · it
KM-DBSCAN: un framework migliorato basato su densità e centroidi per il rilevamento dei confini e la riduzione dei dati verso la Green AI
Perché rendere l'AI più piccola può renderla più ecologica
L'intelligenza artificiale ha un costo nascosto: l'elettricità. Addestrare modelli di machine learning moderni spesso significa elaborare milioni di punti dati su hardware energivoro, il che a sua volta produce emissioni di carbonio. Questo articolo presenta KM-DBSCAN, un nuovo modo per ridurre i dataset prima dell'addestramento senza scartare le informazioni di cui i modelli hanno realmente bisogno. Conservando solo i dati più informativi, il metodo accelera l'apprendimento, riduce il consumo energetico e continua a fornire previsioni accurate in compiti che vanno dal riconoscimento delle cifre scritte a mano alla rilevazione precoce del cancro della pelle.
Troppi dati, troppa energia
Per anni la convinzione dominante nell'AI è stata che più dati portino quasi sempre a modelli migliori. Pur migliorando l'accuratezza, questo comporta anche tempi di addestramento più lunghi, macchine più grandi e bollette elettriche più alte. I ricercatori hanno iniziato a distinguere tra la "Red AI", che persegue l'accuratezza a ogni costo, e la "Green AI", che tenta di bilanciare prestazioni e impatto ambientale. Una strada promettente verso un'AI più verde è la riduzione dei dati: invece di alimentare un modello con ogni esempio disponibile, identificare un insieme molto più piccolo di casi che definisca comunque bene il problema, in particolare i casi borderline difficili che determinano le decisioni di un classificatore.
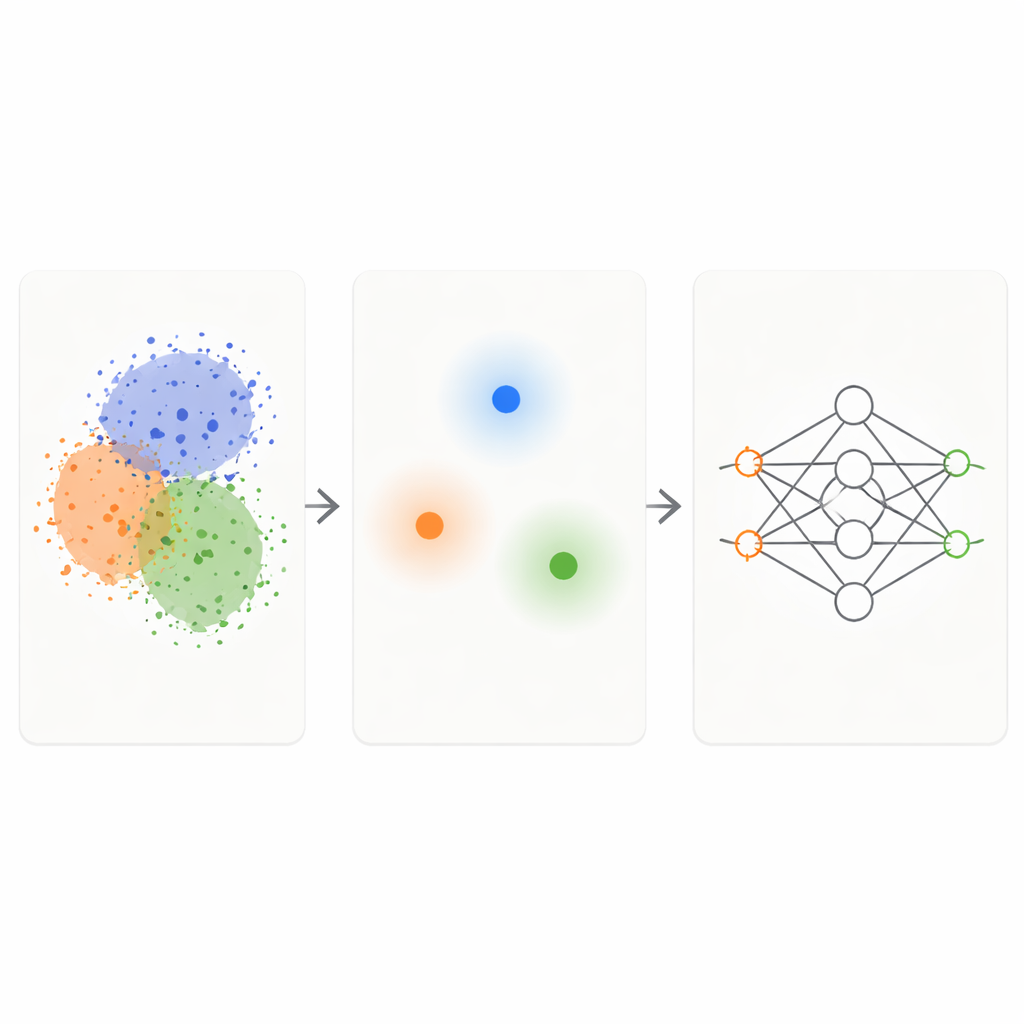
Unire due idee semplici in un filtro intelligente
Il framework KM-DBSCAN combina due tecniche di clustering ben note per agire come un filtro intelligente sui dati grezzi. Prima, un metodo veloce chiamato K-Means raggruppa i punti in cluster compatti e sostituisce ogni gruppo con un centro rappresentativo, o centroide. Questo riduce il problema da migliaia o milioni di punti a poche centinaia di rappresentanti. Successivamente, un metodo basato sulla densità (DBSCAN) viene eseguito su quei centroidi per individuare quali regioni si trovano ai confini tra cluster e quali sono interni densi e omogenei o rumore isolato. Lavorando a livello di centroidi, DBSCAN diventa molto più veloce e meno sensibile a scelte di parametri critiche rispetto a quando viene applicato direttamente a tutti i punti dati.

Conservare solo i casi difficili e informativi
Una volta che KM-DBSCAN ha identificato dove diversi gruppi si toccano o si sovrappongono, mantiene solo i punti dati che si trovano vicino a questi confini e scarta sia i punti in profondità all'interno dei cluster sia gli outlier evidenti. I punti interni sono in gran parte ridondanti: sembrano tutti simili e trasmettono al modello lo stesso messaggio sulla loro classe. I punti di confine, al contrario, indicano al modello esattamente dove finisce una classe e ne inizia un'altra. Su dataset sintetici di prova, questa strategia riproduce gli stessi confini decisionali che un classificatore apprende dai dati completi, anche quando la maggior parte dei punti viene rimossa. Su dataset del mondo reale come Banana, USPS digits, il dataset Adult sul reddito, dati di incidenti stradali, varietà di fagioli secchi e immagini cutanee di melanoma, i set ridotti preservano la struttura chiave del problema pur essendo un ordine di grandezza più piccoli.
Velocità, risparmio di carbonio e applicazioni reali
Gli autori hanno testato KM-DBSCAN come front-end per diversi modelli popolari, inclusi support vector machine, perceptron multistrato e reti neurali convoluzionali. In molti casi, l'addestramento sui dati ridotti è risultatto decine fino a migliaia di volte più veloce mantenendo quasi la stessa accuratezza—e talvolta migliorandola leggermente. Per esempio, nel riconoscimento delle cifre scritte a mano, il metodo ha ridotto il set di addestramento all'1,4% della sua dimensione originale ottenendo comunque un lieve aumento di accuratezza, rendendo l'addestramento 284 volte più rapido. In un compito di previsione del reddito con classi sbilanciate, ha ottenuto un'accelerazione di 6907 volte usando solo circa il 3% dei dati con una perdita minima di accuratezza. In un esperimento di rilevamento del melanoma, una rete neurale profonda ha raggiunto oltre il 90% di accuratezza addestrando su meno di un terzo del dataset originale di immagini cutanee, con emissioni di carbonio ridotte di oltre il 70%.
Cosa significa per l'AI di tutti i giorni
Per i non specialisti, il messaggio chiave è che una selezione più intelligente può battere il puro volume. KM-DBSCAN dimostra che scegliere con cura quali esempi vede un modello—concentrandosi sui casi di confine più informativi—può tagliare i tempi di calcolo e il consumo energetico pur mantenendo previsioni affidabili. Questo approccio si inserisce bene nella spinta più ampia verso la Green AI, dove la qualità dei dati e la progettazione attenta delle pipeline di addestramento contano tanto quanto la dimensione grezza del modello. Se adottato su larga scala, un filtraggio consapevole dei dati potrebbe rendere più sostenibili applicazioni che vanno dall'analisi di immagini mediche ai sistemi di sicurezza stradale, portando potenti strumenti di AI alla portata di organizzazioni che non dispongono di risorse di calcolo massive.
Citazione: AboElsaad, M.Y., Farouk, M. & Khater, H.A. KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI. Sci Rep 16, 10349 (2026). https://doi.org/10.1038/s41598-026-40062-z
Parole chiave: green AI, riduzione dei dati, clustering, efficienza del machine learning, rilevamento del melanoma