Clear Sky Science · it
Incremento della sparsità del segnale sorgente basato sull’algoritmo di trasformazione per estrazione sincronica del massimo locale per la stima di matrici miste in UBSS
Districare segnali nascosti
Molte delle tecnologie su cui facciamo affidamento—reti wireless, radar, scanner medici e persino microfoni intelligenti—devono individuare segnali deboli che sono mescolati in modo irrecuperabile. Immaginate di cercare di seguire più conversazioni contemporaneamente in un bar affollato usando solo due orecchie. Questo articolo presenta un nuovo modo per «districare» segnali sovrapposti quando i sensori sono meno delle sorgenti, una condizione notoriamente difficile. Affinando il modo in cui osserviamo i segnali nel tempo e nella frequenza e migliorando come i computer raggruppano i dati correlati, gli autori dimostrano di poter separare i miscugli in modo più accurato e affidabile, anche in condizioni rumorose e reali. 
Perché i segnali misti sono così difficili da separare
In molti sistemi, diversi segnali indipendenti viaggiano attraverso lo stesso canale e vengono rilevati da un numero ridotto di ricevitori. Questa situazione, chiamata separazione cieca delle sorgenti sottodeterminata, significa che ci sono più segnali incogniti che misure. I metodi classici per la separazione dei segnali generalmente assumono il contrario, quindi qui falliscono. Un trucco moderno fondamentale è sfruttare la sparsità: in una rappresentazione adeguata, ogni sorgente è attiva solo in pochi istanti o frequenze. Se, nella maggior parte dei momenti, domina al massimo una sorgente, la nuvola di dati osservati forma naturalmente cluster le cui direzioni codificano come ogni sorgente si è mescolata nei ricevitori. Trovare con precisione questi cluster, tuttavia, dipende dall’avere una rappresentazione in cui l’energia di ciascuna sorgente è concentrata nettamente piuttosto che diffusa.
Affinare l’immagine di un segnale
Per mettere in luce la sparsità, gli ingegneri spesso trasformano i segnali in un quadro tempo–frequenza che mostra quali toni sono presenti in quali istanti. La semplice trasformata di Fourier a finestra mobile lo fa scorrendo una finestra nel tempo e calcolando molti piccoli spettri, ma sfuma l’energia e non può dare simultaneamente una tempistica nitida e una precisa definizione della frequenza. Varianti più avanzate come la synchrosqueezing e la synchroextracting cercano di convogliare l’energia diffusa verso la cresta che segue la frequenza istantanea di un segnale. Questi metodi migliorano il focus, ma restano vulnerabili al rumore: quando perturbazioni casuali vengono compresse lungo le stesse creste del segnale, il risultato può essere una banda luminosa ma sfocata che nasconde dettagli fini.
Trovare i picchi locali per aumentare la sparsità
Sulla base di queste idee, gli autori introducono la Trasformata di Estrazione Sincronica del Massimo Locale, o LMSET. Invece di convogliare tutta l’energia vicina verso una cresta di frequenza, LMSET scansiona il piano tempo–frequenza e, per ogni istante, si aggancia ai picchi locali lungo l’asse delle frequenze. Vengono mantenuti e riallocati solo i coefficienti attorno a questi massimi locali, mentre il resto viene soppresso. Questo semplice cambiamento produce una rappresentazione in cui l’energia di ciascun componente è concentrata in curve sottili e pulite con molti meno punti sparsi. Attraverso simulazioni con segnali di prova multicomponente, LMSET genera la più bassa entropia di Rényi, una misura standard di concentrazione, sovraperformando i metodi convenzionali e all’avanguardia su un ampio intervallo di livelli di rumore. In parole semplici, LMSET dà un’immagine più chiara di dove vive ciascun segnale nel tempo e nella frequenza.
Raggruppamento più intelligente per apprendere la mescolatura nascosta
Un’immagine più nitida è solo metà della battaglia; il passo successivo è raggruppare i punti risultanti per stimare la matrice di mescolamento sconosciuta che descrive come ogni sorgente contribuisce a ciascun ricevitore. Molti approcci si basano sul fuzzy C-means, un metodo di clustering popolare che spesso rimane intrappolato in soluzioni scadenti perché è molto sensibile alla stima iniziale e ai punti anomali. Per superare queste debolezze, gli autori accoppiano LMSET con uno schema di clustering nuovo e più robusto. Usano prima un algoritmo di ricerca basato su PID, ispirato alla teoria del controllo, per esplorare l’intero spazio delle possibili posizioni dei centri dei cluster ed evitare posizioni di partenza sfavorevoli. Introducono poi un meccanismo di pesi booleani per attenuare l’influenza degli outlier e impiegano una strategia basata sull’entropia informativa che riduce la sensibilità alle condizioni iniziali. Insieme, questi passaggi permettono al clustering di agganciarsi alle vere direzioni delle sorgenti nascoste in modo più consistente.
Cosa rivelano i test
Gli autori testano l’intera pipeline—LMSET più il clustering migliorato—su miscugli di segnali di comunicazione digitalmente modulati, inclusi QAM, QPSK e FSK, in ambienti sia silenziosi sia rumorosi. Confrontano le matrici di mescolamento stimate con quelle reali usando l’errore angolare e l’errore quadratico medio normalizzato. In tutti i casi, l’uso di LMSET invece di una trasformata tradizionale riduce gli errori, perché i punti dati formano cluster più stretti e distinti. Tra i metodi di clustering, il fuzzy C-means robusto ottimizzato via PID proposto ottiene le minori deviazioni angolari medie e i migliori punteggi di errore. Nel complesso, il metodo combinato migliora la precisione della stima della matrice di mescolamento di quasi il 20 percento rispetto agli approcci convenzionali, mantenendo prestazioni solide anche quando i livelli di rumore sono elevati. 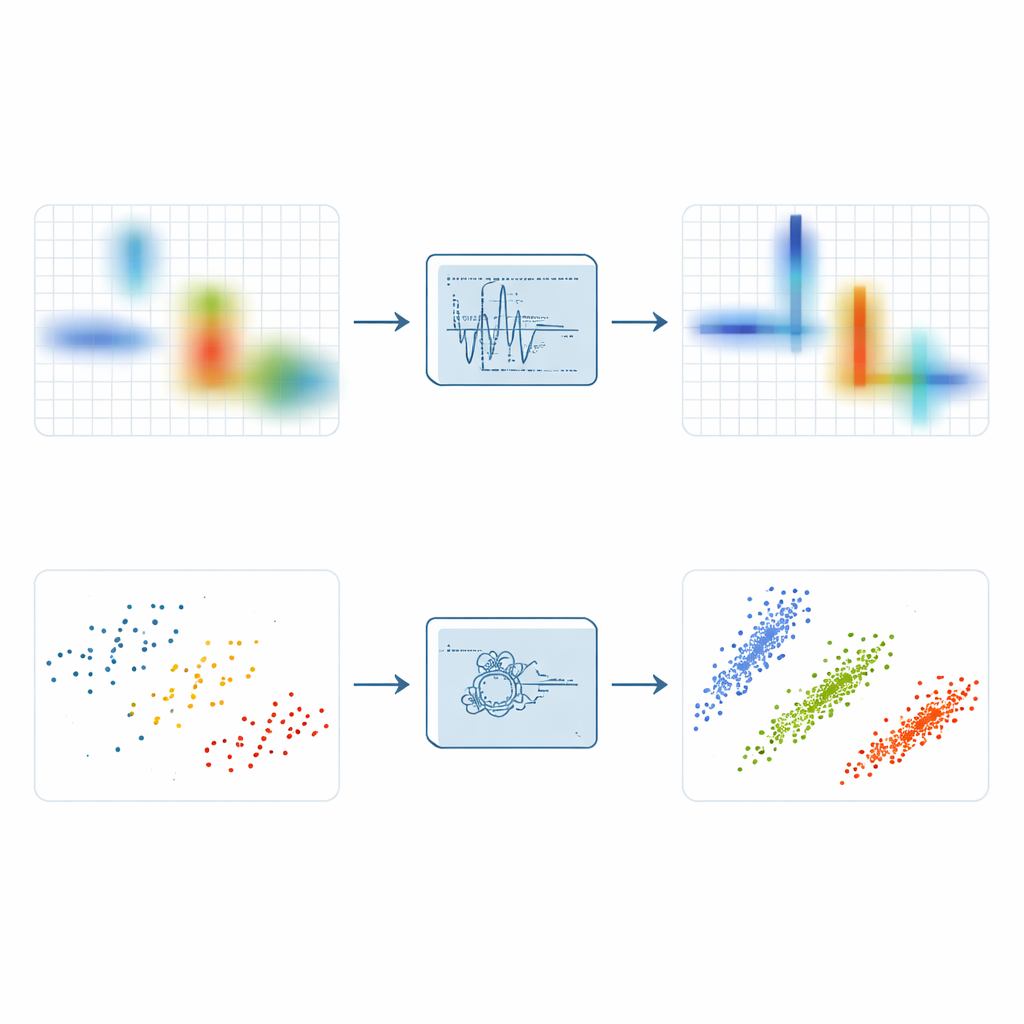
Perché questo conta oltre la teoria
Per i non specialisti, la conclusione principale è che gli autori hanno trovato un modo migliore per osservare e raggruppare segnali intrecciati in modo che ogni flusso originale possa essere recuperato più pulitamente. Focalizzandosi sui picchi locali nel paesaggio tempo–frequenza e abbinando questa visione a una strategia di clustering più accurata, il loro metodo rende il problema del bar—molte voci, poche orecchie—un po’ più risolvibile. Questo progresso potrebbe avvantaggiare applicazioni che vanno dai collegamenti satellitari che devono separare trasmissioni sovrapposte, ai sistemi medici che devono isolare deboli segnali biologici sepolti nel rumore, offrendo informazioni più chiare a partire dalle stesse misure limitate.
Citazione: Li, X., Li, Z., Yao, R. et al. Source signal sparsity enhancement based on local maximum synchronous extraction transform algorithm for mixed matrix estimation in UBSS. Sci Rep 16, 9378 (2026). https://doi.org/10.1038/s41598-026-40055-y
Parole chiave: separazione cieca delle sorgenti, sparsità del segnale, analisi tempo–frequenza, algoritmi di clustering, comunicazioni wireless