Clear Sky Science · it
Generazione de novo e screening in silico di candidati peptidici anti-diabetici tramite un framework deep learning–attention con fusione di caratteristiche fisico-chimiche
Perché progettare peptidi in modo più intelligente è importante per il diabete
Il diabete colpisce centinaia di milioni di persone nel mondo e i farmaci attuali non funzionano perfettamente per tutti. Molti trattamenti perdono efficacia nel tempo o causano effetti collaterali. Un’opzione promettente è una classe di piccole proteine chiamate peptidi anti-diabetici, che possono modulare la glicemia con elevata precisione. La sfida è che scoprire nuovi farmaci peptidici in laboratorio è lento e costoso. Questo studio presenta una pipeline guidata dal calcolatore in grado di inventare e vagliare un gran numero di potenziali peptidi anti-diabetici, indirizzando i ricercatori verso i candidati più promettenti da testare nel mondo reale.
Dai peptidi noti per il diabete a dati iniziali puliti
I ricercatori hanno iniziato assemblando una collezione di alta qualità di peptidi che sono stati sperimentalmente dimostrati influenzare la glicemia, principalmente tramite l’influenza su ormoni come il GLP-1 o su enzimi come la DPP-IV. Questi hanno costituito gli esempi “positivi”. Hanno poi costruito un set “negativo” corrispondente di peptidi senza attività anti-diabetica riportata, scelti con cura in modo che lunghezza, composizione e chimica di base somigliassero ai positivi. Per evitare di ingannare il modello con quasi-duplicati, hanno usato strumenti di similarità di sequenza per assicurarsi che peptidi strettamente correlati non apparissero mai sia nel training sia nei gruppi di test. Questa suddivisione consapevole dell’omologia ha garantito che il sistema venisse valutato sulla capacità di riconoscere schemi genuinamente nuovi piuttosto che memorizzare quelli vecchi.
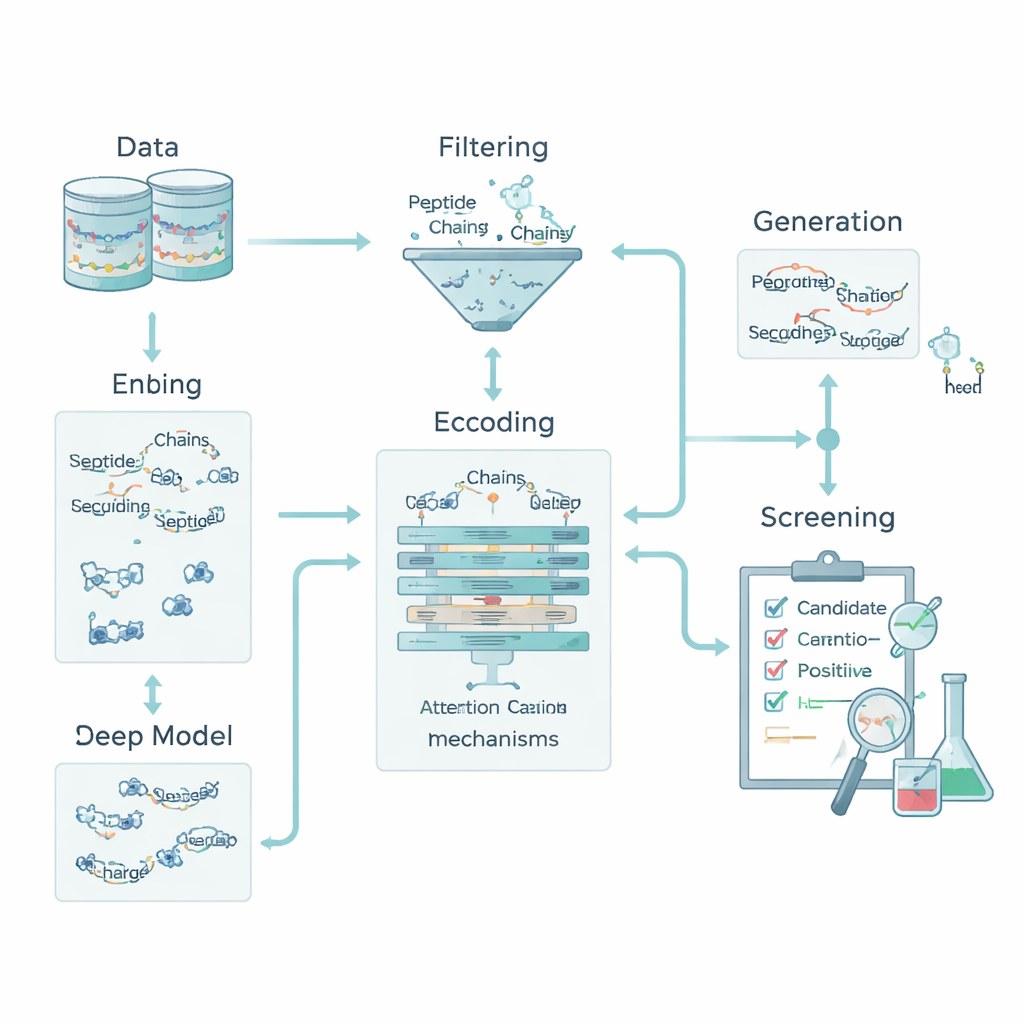
Codificare la chimica perché le macchine possano leggere i peptidi
Per un computer, un peptide è solo una stringa di lettere che rappresentano gli amminoacidi. Per collegare quelle lettere alla biologia, il team ha trasformato ogni amminoacido in cinque tratti chimici di base: quanto è idrofobico, la sua carica elettrica, la tendenza a formare legami a idrogeno, la sua massa e se possiede un anello aromatico. Questo ha trasformato ogni peptide in una piccola “immagine” che cattura sia l’ordine sia la chimica. A ciò hanno aggiunto descrittori a livello di intero peptide come carica complessiva, idrofobicità media e indice di Boman, che è correlato alla tendenza di un peptide a legarsi ad altre proteine. Insieme, queste caratteristiche permettono al modello di considerare sia i pattern locali — brevi motivi di amminoacidi — sia le proprietà globali che influenzano il comportamento del peptide nell’organismo.
Un motore deep learning che spiega le sue scelte
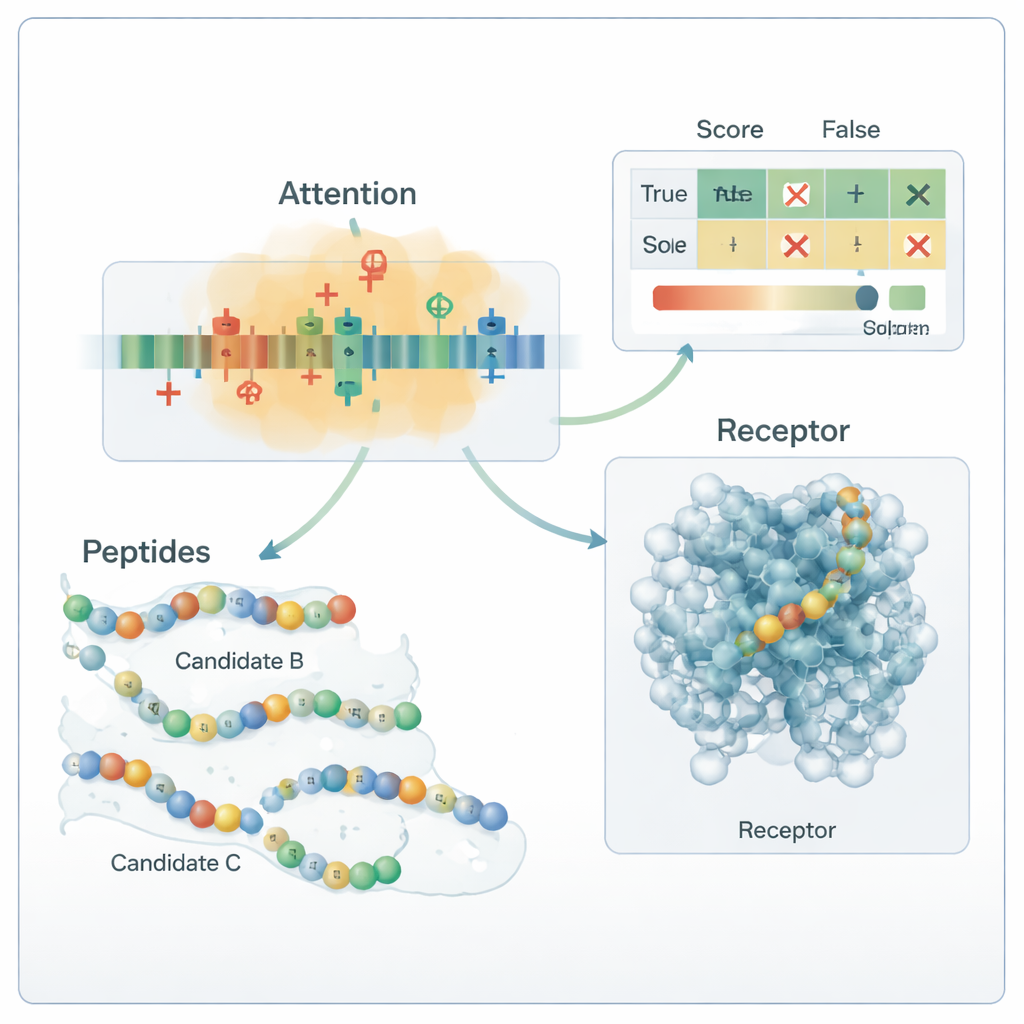
Il cuore della pipeline è un modello di deep learning ibrido. Una rete neurale convoluzionale (CNN) scansiona il peptide, cercando brevi motivi che tendono ad apparire nei peptidi attivi, molto simile ai filtri di un sistema di riconoscimento delle immagini. Su questo, uno strato di attention impara quali posizioni nella sequenza sono più importanti, catturando relazioni a lungo raggio tra residui distanti. L’output di questo motore di sequenza viene fuso con i descrittori chimici globali e passato a diversi classificatori di machine learning standard — support vector machine, alberi decisionali, k-nearest neighbors e gradient-boosted trees. Un metodo di ottimizzazione specializzato, chiamato OptimizedTPE, regola automaticamente i loro parametri, bilanciando accuratezza e rischio di overfitting. Il meccanismo di attention fornisce anche “mappe di importanza” a livello di residuo, aiutando gli scienziati a vedere quali parti di ciascun peptide guidano le decisioni del modello.
Inventare nuovi candidati evitando la contaminazione dei dati
Per superare il numero esiguo di peptidi anti-diabetici noti, il team ha aggiunto una fase di generazione che alimenta solo il processo di addestramento. Hanno usato una combinazione di strategie — mutazione guidata, ricombinazione di motivi e un autoencoder variazionale — per proporre nuove sequenze che somigliano, ma non copiano, peptidi attivi noti. Questi candidati sono stati poi filtrati da rigide “porte descrittoriali” che impongono carica, dimensione e propensione al legame realistici, oltre a strumenti esterni che valutano la similarità con peptidi bioattivi conosciuti. Solo le sequenze che superano questi filtri e restano chiaramente distinte da tutti i peptidi di test vengono mantenute come positivi debolmente etichettati per l’addestramento; nessuna viene mai usata per valutare il modello. Questo approccio ha ampliato il set di addestramento preservando un banco di prova pulito e imparziale.
Quanto bene funziona il sistema e cosa significa
Quando è stato messo alla prova con un pannello completamente indipendente di 180 peptidi studiati sperimentalmente raccolti dalla letteratura recente, il framework ha etichettato correttamente circa 99 sequenze su 100, con precisione e richiamo vicino a 0,99. In termini pratici, questo significa che raramente manca un vero peptide anti-diabetico e raramente segnala come promettente un peptide inattivo. L’analisi delle mappe di attention e dei test di mutazione ha mostrato che il modello ha imparato regole chimicamente sensate: fa ampio uso di residui carichi positivamente e di certi residui idrofobici noti per essere importanti nel legare bersagli legati al diabete. Simulazioni di docking molecolare hanno inoltre suggerito che alcuni dei peptidi appena generati possono stabilire contatti plausibili con il recettore umano GLP-1. Pur richiedendo ancora conferma in laboratorio, lo studio dimostra un modo riproducibile e biologicamente fondato per esplorare l’enorme spazio dei possibili farmaci peptidici e per dare priorità ai pochi che sono più probabilmente utili nella gestione del diabete.
Citazione: Asl, Z.R., Rezaee, K., Ansari, M. et al. De novo generation and in silico screening of anti-diabetic peptide candidates via a deep learning–attention framework with physicochemical feature fusion. Sci Rep 16, 6580 (2026). https://doi.org/10.1038/s41598-026-39985-4
Parole chiave: peptidi anti-diabetici, deep learning, scoperta di farmaci, progettazione di peptidi, recettore GLP-1