Clear Sky Science · it
Attuazione della sorveglianza genomica di SARS-CoV-2 durante la pandemia di COVID-19 tramite una collaborazione accademico–sanitaria nel sud‑est del Michigan
Perché tracciare le varianti vicino a casa è importante
Durante la pandemia di COVID-19, la maggior parte di noi ha sentito parlare di nuove varianti attraverso i titoli nazionali. Ma il virus non si è diffuso allo stesso modo ovunque. Questo articolo descrive come scienziati, ospedali e funzionari della sanità pubblica nel sud‑est del Michigan hanno costruito un sistema locale per osservare l’evoluzione del coronavirus in tempo reale. Leggendo il codice genetico del virus da migliaia di campioni di pazienti, sono stati in grado di vedere quali varianti si stavano diffondendo, dove si stabilivano e quali comunità erano maggiormente colpite—informazioni che possono guidare risposte più rapide e mirate in futuri focolai.
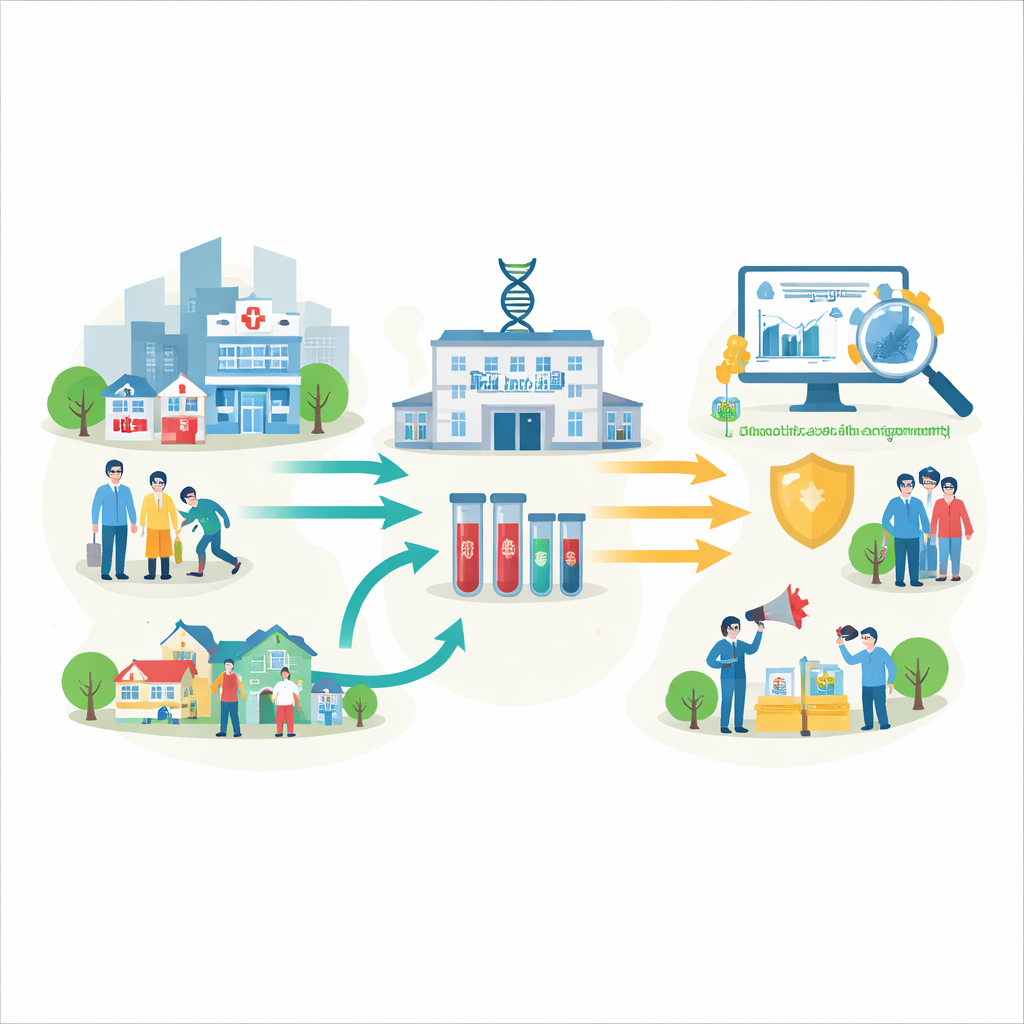
Costruire un sistema di allerta precoce di quartiere
Il team ha unito Wayne State University, il Dipartimento della Salute di Detroit, Henry Ford Health, una flotta di unità mobili sanitarie e il dipartimento sanitario statale. L’obiettivo condiviso era creare un “sistema di allerta precoce” regionale per il COVID-19 basato sulle impronte genetiche del virus. Ospedali, cliniche pubbliche e furgoni mobili hanno raccolto tamponi nasali da persone risultate positive. Questi campioni sono stati codificati a barre, conservati in modo sicuro in una biobanca centrale e poi inviati a un laboratorio universitario attrezzato per gestire un grande numero di test. Accordi sui dati accurati e protezioni della privacy hanno reso possibile associare ogni sequenza virale a informazioni di base sul paziente e sul suo quartiere senza rivelarne l’identità.
Dal tampone alla mappa genetica
In laboratorio, i tecnici nelle cappe di sicurezza hanno trattato termicamente i campioni, estratto il materiale genetico virale e confermato l’infezione usando un test PCR standard. Lo stesso materiale è poi passato attraverso macchine ad alto rendimento che hanno letto l’intero codice genetico del SARS‑CoV‑2 di ciascun paziente. Computer potenti hanno confrontato queste sequenze con genomi di riferimento e hanno utilizzato software specializzati per assegnare ogni virus a un gruppo di varianti noto. Questa pipeline ha trasformato i tamponi grezzi in dati genetici organizzati—mostrando quali versioni del virus circolavano, quando sono apparse e come sono cambiate nel tempo.
Dove e in chi il virus ha colpito di più
Tra l’inizio del 2022 e la metà del 2024, il programma ha raccolto oltre 7.500 campioni e ha sequenziato con successo più di 6.200 di essi, per lo più provenienti da pazienti del sistema sanitario Henry Ford. Questi casi provenivano da quasi 300 CAP in tutto il sud‑est del Michigan. Omicron è stata di gran lunga la variante dominante, rappresentando circa due terzi delle infezioni sequenziate, e il quadro delle varianti corrispondeva da vicino a quanto osservato nei dati statali. Gli anziani erano più presenti nel dataset e più soggetti a decesso, riflettendo il loro maggiore rischio di forme severe. Le infezioni erano leggermente più comuni nelle donne, mentre i decessi risultavano leggermente più frequenti negli uomini. Quando i ricercatori hanno confrontato i modelli razziali e di quartiere, hanno trovato che i residenti neri avevano tassi più elevati di infezione e di morte rispetto ai residenti bianchi—tuttavia, una volta considerate infezione, età e variante, è stato il disagio del quartiere, non la sola razza, a spiegare meglio il maggior rischio di morte.

Osservare come il virus cambia nel tempo e nello spazio
Poiché ogni virus portava una marca temporale e una localizzazione, il team ha potuto tracciare mappe e linee temporali della pandemia nella loro regione. Hanno osservato onde iniziali dominate da lignaggi più vecchi, seguite da un breve picco della variante Delta e poi un lungo periodo in cui Omicron e i suoi derivati hanno preso il sopravvento. Omicron ha mostrato la diffusione geografica più ampia, raggiungendo anche le parti settentrionali dello stato, ma i tassi di infezione più elevati si sono concentrati nella zona metropolitana di Detroit e dintorni. Confrontando i loro dati con banche dati nazionali e globali, hanno riscontrato una forte corrispondenza nelle tendenze complessive delle varianti ma anche segnali chiari di particolarità locali e lacune di campionamento, sottolineando perché la sorveglianza regionale aggiunge valore oltre i totali nazionali.
Cosa significa questo modello per il futuro
In termini semplici, questo articolo dimostra che una città e le comunità circostanti possono costruire il proprio “radar genetico” per monitorare un virus, anche durante una crisi in rapida evoluzione. Il programma del sud‑est del Michigan ha collegato ospedali, cliniche mobili e agenzie di sanità pubblica in un sistema operativo che poteva vedere l’arrivo di varianti pericolose, seguirne la diffusione e collegarle a esiti reali come ricovero e morte. Sebbene gli autori riconoscano dei limiti—come il campionamento non uniforme e il focus su un singolo sistema sanitario—sostengono che il quadro di base è sostenibile e adattabile. Con un adeguato supporto, partnership simili potrebbero essere utilizzate per monitorare l’influenza, RSV, Mpox o il prossimo patogeno sconosciuto, offrendo ai leader locali una visione precoce e più chiara dei problemi prima che diventino un’emergenza su vasta scala.
Citazione: Raychouni, R., Zhang, X., Bauer, S.J. et al. Implementation of SARS-CoV-2 genomic surveillance during the COVID-19 pandemic through an academic–public health collaboration in southeast Michigan. Sci Rep 16, 8680 (2026). https://doi.org/10.1038/s41598-026-39974-7
Parole chiave: varianti di SARS-CoV-2, sorveglianza genomica, epidemiologia del COVID-19, dati di sanità pubblica, Detroit Michigan