Clear Sky Science · it
R-GAT: classificazione di documenti sul cancro sfruttando una rete residua basata su grafi per scenari con dati limitati
Perché è importante classificare gli articoli sul cancro
Ogni giorno gli scienziati pubblicano centinaia di nuovi studi sul cancro, dalla diagnosi precoce ai farmaci promettenti. Gran parte di questi lavori compare prima come brevi riassunti chiamati abstract. Medici, ricercatori e decisori politici non possono leggerli tutti, e perdere un articolo importante potrebbe rallentare i progressi. Questo studio affronta una domanda semplice ma potente: è possibile costruire un sistema informatico veloce e leggero che classifichi automaticamente gli abstract relativi al cancro per tipo di tumore, anche quando sono disponibili solo quantità modeste di dati etichettati e risorse di calcolo?
Un modo più intelligente di leggere la ricerca sul cancro
Gli autori si concentrano su quattro tipi di abstract presenti nel database PubMed: quelli su tumore alla tiroide, tumore del colon, tumore al polmone e argomenti biomedicali più generali. Hanno creato una raccolta accuratamente verificata di 1.875 abstract recenti, distribuiti in modo approssimativamente uguale tra questi quattro gruppi. Questo bilanciamento aiuta a evitare bias verso un singolo tipo di tumore. Prima della modellizzazione i testi sono stati puliti: le parole sono state suddivise in token, l’ortografia controllata, le forme correlate unite e i termini non informativi rimossi. Gli abstract puliti sono stati poi convertiti in forma numerica usando diversi metodi standard così da poter confrontare in modo equo diversi tipi di modelli.
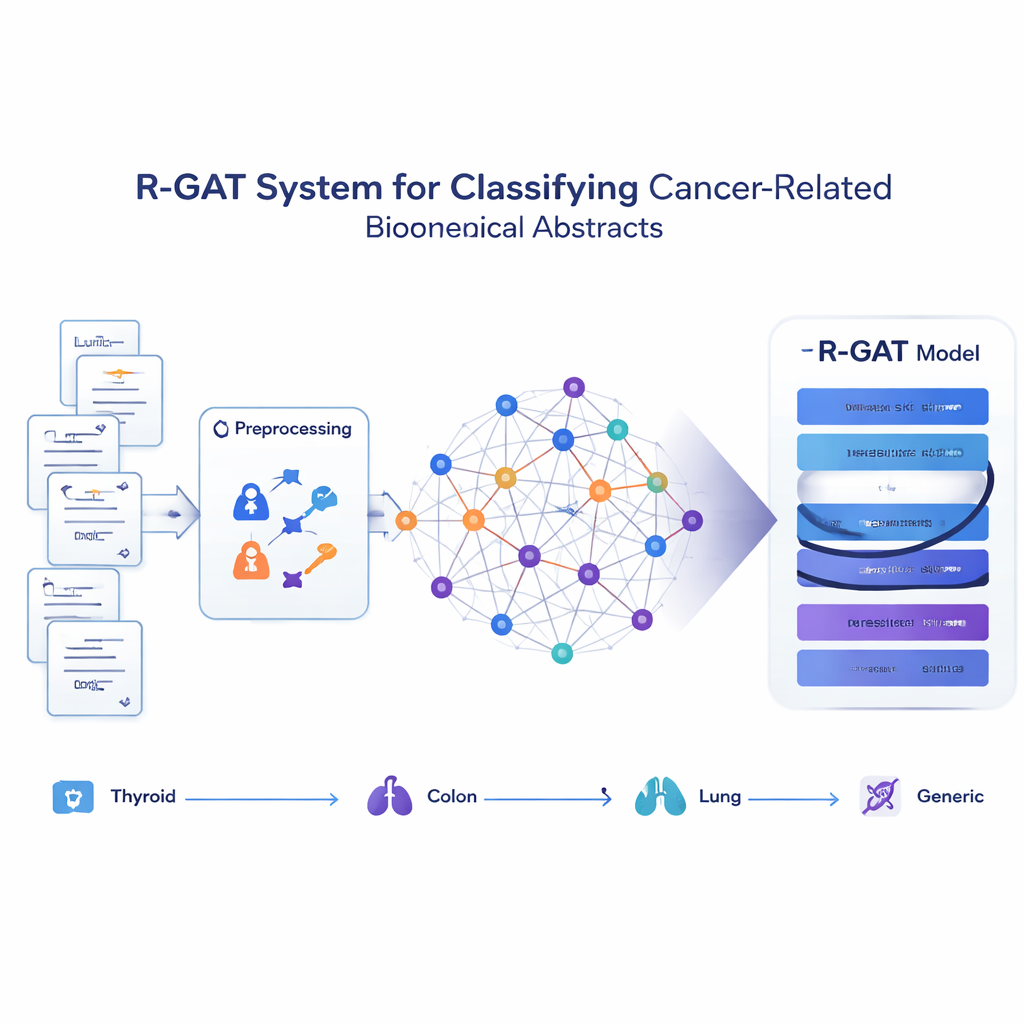
Trasformare gli articoli in una rete di idee
Invece di trattare ogni abstract come una stringa isolata di parole, il metodo proposto, chiamato R-GAT (Residual Graph Attention Network), considera l’intera raccolta come una rete. In questa rete, ogni abstract è un nodo e le connessioni rappresentano quanto due abstract siano simili nel contenuto. Se due articoli trattano argomenti strettamente correlati, il collegamento tra loro è forte; altrimenti è debole o assente. Questo permette al modello di valutare un abstract nel contesto dei suoi vicini, imitando il modo in cui un lettore umano potrebbe comprendere meglio uno studio conoscendo il lavoro correlato.
Come il nuovo modello apprende dai vicini
R-GAT si basa su due idee chiave dell’intelligenza artificiale moderna: attention e connessioni residue. L’attenzione consente al modello di focalizzarsi maggiormente sugli abstract vicini più rilevanti nella rete, invece di trattare tutti i vicini allo stesso modo. Più “head” di attenzione cercano contemporaneamente diversi tipi di pattern. Le connessioni residue funzionano come scorciatoie che trasferiscono informazioni attraverso gli strati più profondi della rete, aiutando il modello a non perdere segnali importanti durante l’apprendimento. Dopo aver processato il grafo attraverso diversi strati di attenzione e queste vie di collegamento, il sistema condensa l’informazione dell’intera rete in un riassunto compatto che viene poi passato a un classificatore finale che predice a quale delle quattro categorie appartiene ogni abstract.
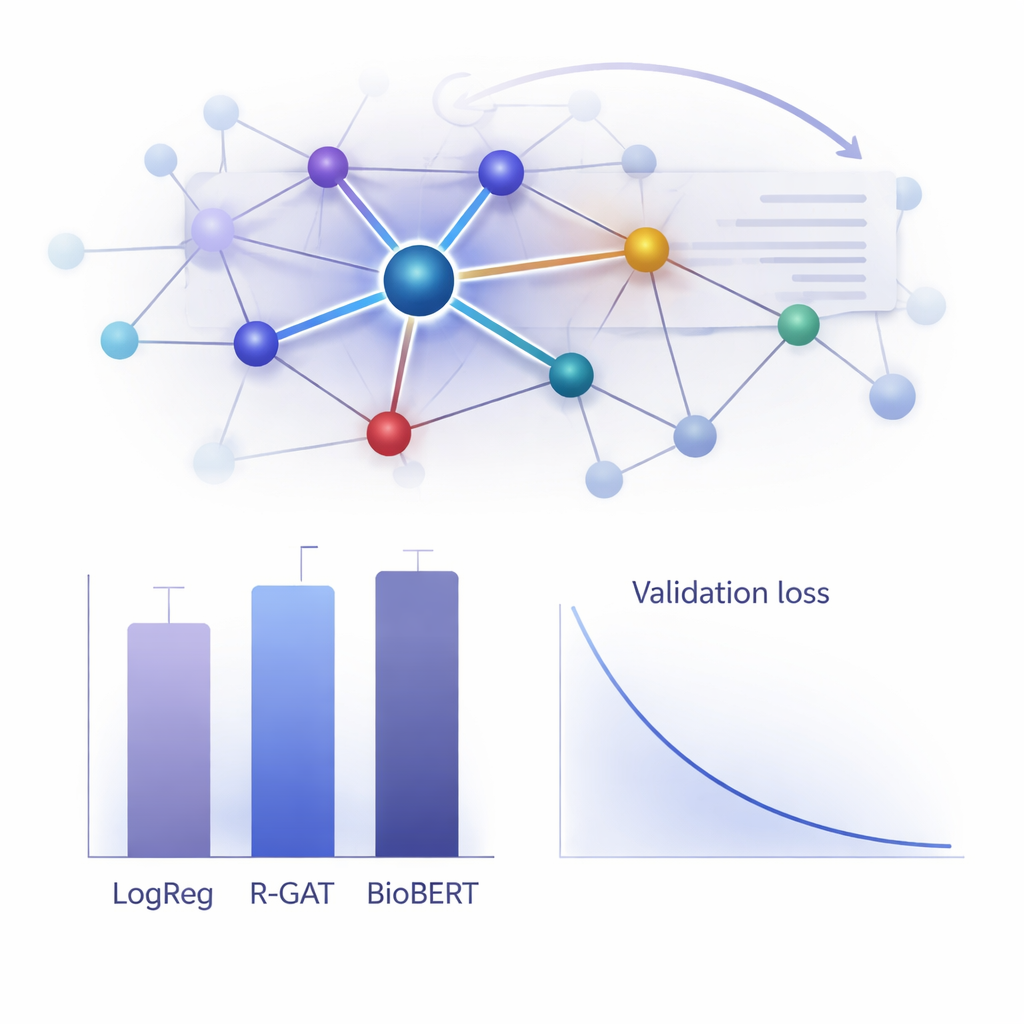
Quanto funziona nella pratica?
Per valutare il valore di R-GAT, gli autori lo hanno confrontato con un’ampia gamma di alternative, dai modelli lineari classici ai sistemi transformer all’avanguardia come BioBERT, popolari ma onerosi in termini computazionali. Sorprendentemente, un semplice modello di regressione logistica basato su feature di conteggio delle parole ha ottenuto il punteggio grezzo più alto su questo specifico dataset, e anche BioBERT ha mostrato ottime prestazioni—ma entrambi presentano limiti, tra cui dipendenza da scelte di feature specifiche o la necessità di risorse di calcolo sostanziali. R-GAT ha raggiunto un macro F1-score di circa 0,96, vicino ai migliori modelli, mostrando al contempo risultati molto stabili tra diverse suddivisioni train–test. Test accurati in cui sono state rimosse l’attenzione o le connessioni residue hanno evidenziato cali di prestazione, confermando che entrambe le componenti sono fondamentali per la robustezza del modello quando i dati sono limitati.
Cosa significa per la ricerca sul cancro in futuro
Per un lettore non esperto, la conclusione è semplice: R-GAT è uno strumento pratico che aiuta a ordinare gli articoli di ricerca sul cancro per tipo di tumore con alta e consistente accuratezza, senza richiedere dataset enormi o hardware costoso. Non sostituisce i più potenti modelli linguistici sul mercato, ma offre una via di mezzo affidabile—particolarmente utile per ospedali, gruppi di ricerca o team di sanità pubblica che necessitano di risultati riproducibili e affidabili con vincoli di dati e budget. Pubblicando sia il loro modello sia il dataset curato in modo aperto, gli autori forniscono anche un benchmark condiviso che altri possono usare per sviluppare e testare sistemi migliorati. Sul lungo periodo, strumenti di questo tipo potrebbero rendere molto più facile per gli esperti rimanere aggiornati sulla letteratura sul cancro e trasformare nuove scoperte in cure migliori.
Citazione: Hossain, E., Nuzhat, T., Masum, S. et al. R-GAT: cancer document classification leveraging graph-based residual network for scenarios with limited data. Sci Rep 16, 6582 (2026). https://doi.org/10.1038/s41598-026-39894-6
Parole chiave: informatica del cancro, text mining biomedicale, classificazione di documenti, reti neurali su grafi, apprendimento con dati limitati