Clear Sky Science · it
Apprendimento automatico per prevedere gli stadi di CKD in pazienti con malattia policistica renale autosomica dominante: uno studio di coorte su scala nazionale in Giappone
Perché questo è importante per la salute quotidiana
La malattia renale spesso progredisce silenziosamente e, quando compaiono i sintomi, il danno può essere difficile da invertire. Per le persone nate con la malattia policistica renale autosomica dominante (ADPKD) – una condizione in cui sacche piene di fluido soppiantano gradualmente il tessuto renale normale – sapere quanto velocemente i reni potrebbero guastarsi può influenzare decisioni di vita importanti. Questo studio esplora se le moderne tecniche informatiche, note come apprendimento automatico, possono utilizzare i dati delle normali visite mediche per prevedere come la funzione renale di una persona cambierà nei tre anni successivi, senza fare affidamento su costosi test genetici o esami di imaging avanzati.
Una malattia comune con futuri incerti
L’ADPKD è uno dei disturbi renali ereditari più frequenti e una delle principali cause di malattia renale cronica (CKD). Molte persone colpite arrivano infine a necessitare di dialisi o trapianto, ma il ritmo del peggioramento varia ampiamente. Alcuni progrediscono lentamente e mantengono una funzione renale accettabile fino a età avanzata; altri raggiungono l’insufficienza renale già tra i 40 e i 50 anni. I medici vorrebbero classificare i pazienti in gruppi di rischio precocemente, in modo da adattare terapia e monitoraggio. Gli strumenti predittivi esistenti spesso dipendono da test genetici dettagliati o da risonanze magnetiche complete dei reni, che non sono disponibili di routine in molti sistemi sanitari, incluso il programma di assicurazione nazionale del Giappone. Questo vuoto ha spinto gli autori a cercare un modo più semplice e ampiamente utilizzabile per stimare lo stadio futuro della CKD.
Trasformare un registro nazionale in uno strumento predittivo
I ricercatori si sono basati su un registro giapponese a scala nazionale che raccoglie informazioni su persone con malattie di difficile trattamento che ricevono sostegno governativo. Hanno concentrato l’attenzione su 2.737 adulti con ADPKD che si sono registrati per la prima volta tra il 2015 e il 2021. Per ogni persona il team ha raccolto i dati dalla domanda iniziale – inclusi risultati degli esami del sangue, riscontri delle urine, misure corporee di base, pressione arteriosa e dimensioni renali riportate dal medico – e poi ha valutato lo stadio di CKD di quella persona tre anni dopo. Lo stadio di CKD, che si basa principalmente su quanto i reni filtrano il sangue, funge sia da indicatore della gravità della malattia sia da criterio chiave per l’assistenza finanziaria in Giappone.
Come i computer hanno imparato dai dati dei pazienti
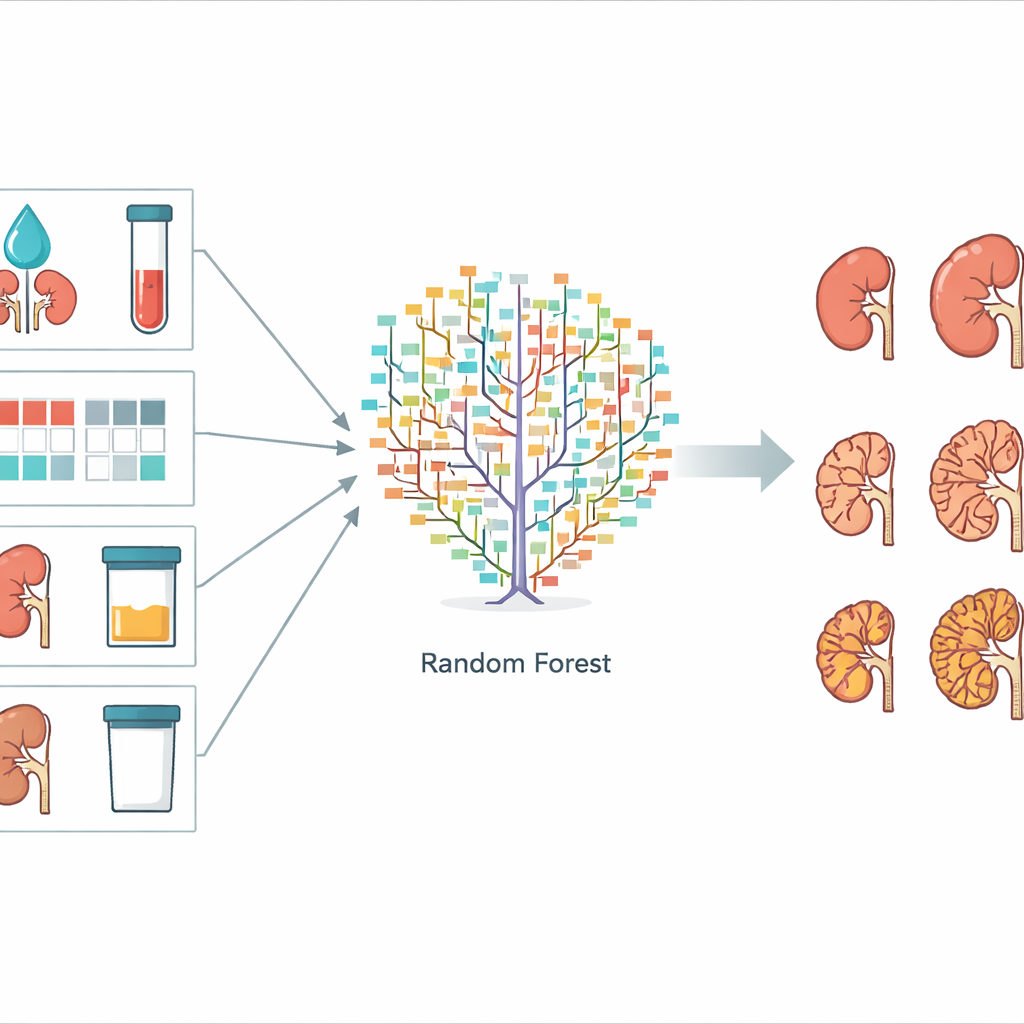
Per costruire il loro sistema predittivo, gli scienziati hanno testato tre metodi comuni di apprendimento automatico: random forest, support vector machine e naïve Bayes. Tutti e tre apprendono dagli esempi piuttosto che da formule fisse. Il set di dati è stato diviso in una parte di addestramento, usata per ottimizzare ogni modello, e una parte di test, usata per verificare quanto bene i modelli finali si comportassero su casi non visti. I computer hanno cercato di prevedere quale tra diversi stadi di CKD ogni paziente avrebbe raggiunto dopo tre anni. Il metodo random forest, che combina molti semplici “alberi” decisionali in un comitato di voto, ha mostrato le migliori prestazioni, prevedendo correttamente lo stadio in circa il 73% dei pazienti del test. La support vector machine, che presuppone principalmente relazioni di tipo lineare tra fattori e risultato, ha fatto peggio, mentre il semplice modello naïve Bayes si è collocato a metà strada.
Cosa è risultato più importante per la previsione
Il team ha anche valutato quali elementi informativi fossero più utili al modello random forest. Lo hanno misurato mescolando un fattore alla volta e osservando quanto peggiorassero le previsioni. Cinque caratteristiche sono risultate particolarmente importanti: la velocità di filtrazione stimata dei reni (eGFR), il livello di creatinina nel sangue (un altro indicatore della funzione renale), una “mappa termica” colorata della CKD che combina filtrazione e riscontri di proteine nelle urine, la quantità di proteine nelle urine e il volume totale di entrambi i reni. Si tratta di tutte misure che possono essere raccolte durante normali visite cliniche, senza file di imaging specializzati o sequenziamento genico. Altri elementi, come il numero esatto di cisti viste nelle scansioni, hanno contribuito poco, suggerendo che non sono essenziali per uno strumento predittivo pratico.
Cosa significa per pazienti e medici
Per le persone con ADPKD, lo studio suggerisce che un modello informatico accuratamente addestrato, alimentato con esami di laboratorio standard e riepiloghi di imaging di base, può fornire una previsione ragionevolmente accurata della salute renale a tre anni. Poiché il modello con le migliori prestazioni può cogliere relazioni complesse e non lineari tra i fattori, potrebbe essere più adatto rispetto alle tradizionali tabelle di rischio per questa malattia cronica e variabile. Pur essendo limitato ai pazienti giapponesi e senza poter provare rapporti di causa‑effetto, il lavoro indica la strada verso strumenti utilizzabili in clinica che aiutino a identificare chi è probabile che peggiori rapidamente e chi potrebbe avere un decorso più lento. In termini chiari, l’articolo conclude che l’apprendimento automatico – in particolare l’approccio random forest – può trasformare i dati medici di uso quotidiano in anteprime personalizzate del futuro renale, supportando cure più personalizzate e una migliore pianificazione per i pazienti con ADPKD.
Citazione: Shimada, Y., Kataoka, H., Nishio, S. et al. Machine learning for predicting CKD stages in patients with autosomal dominant polycystic kidney disease: a nationwide cohort study in Japan. Sci Rep 16, 8771 (2026). https://doi.org/10.1038/s41598-026-39885-7
Parole chiave: malattia policistica renale, malattia renale cronica, apprendimento automatico, predizione del rischio, medicina personalizzata