Clear Sky Science · it
EchoNet++: un dataset multilingue di commento audio per partite di calcio
Perché i suoni del calcio contano
Chiunque abbia seguito una grande partita sa che il boato della folla e l’andamento della voce del cronista sono parte integrante del dramma quanto i gol stessi. Eppure quasi tutta la tecnologia sportiva moderna si concentra ancora su ciò che vedono le telecamere, non su ciò che ascoltano i microfoni. Questo articolo presenta EchoNet ed EchoNet++, un sistema e un dataset combinati che trasformano il caos sonoro delle trasmissioni calcistiche professionali di molti paesi in testo pulito e ricercabile, analizzabile dai computer. Ciò rende possibile studiare tattiche, emozioni e narrazione attraverso campionati e lingue su una scala che nessun team umano di traduttori potrebbe eguagliare.
Da uno stadio rumoroso a un segnale pulito
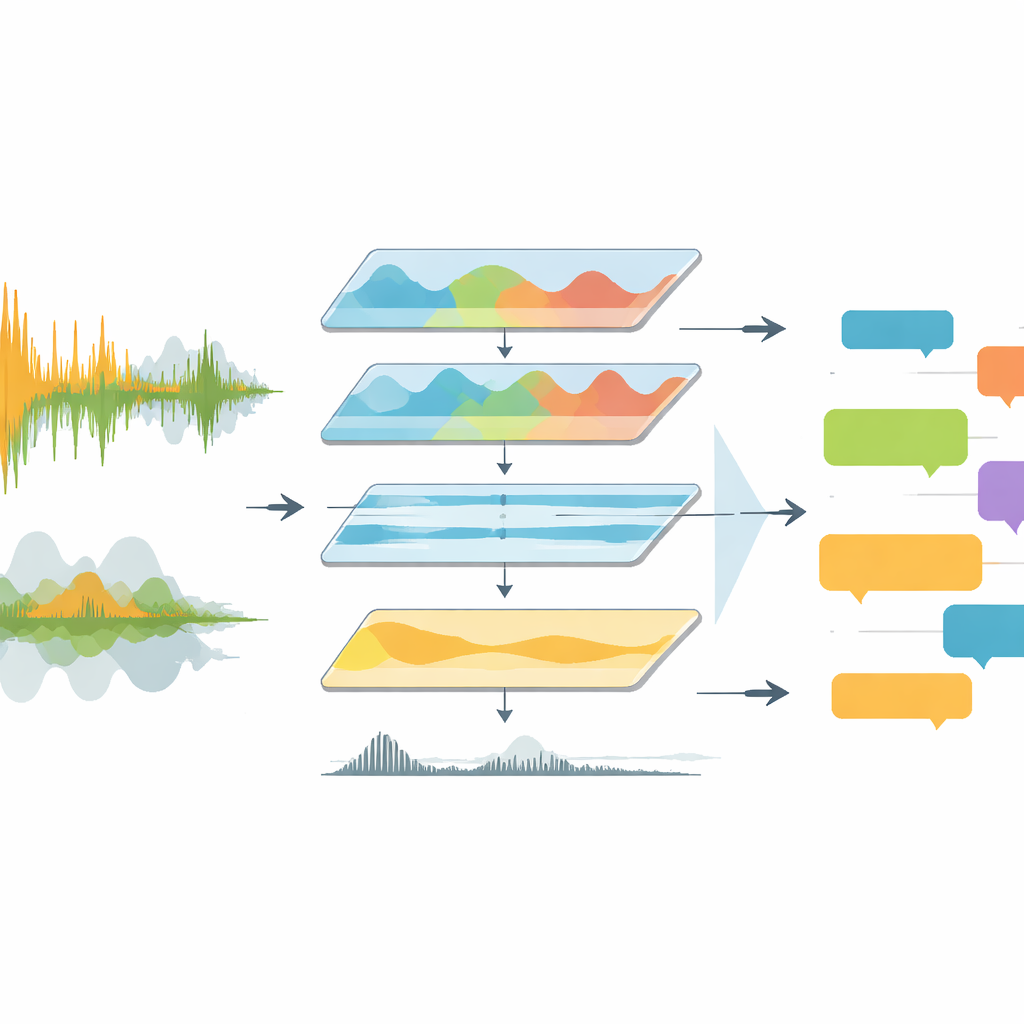
Le partite trasmesse in televisione sono acusticamente caotiche. I cronisti parlano sovrapponendosi ai cori dei tifosi, alla musica dello stadio e a improvvise esplosioni di entusiasmo. Gli strumenti precedenti spesso immettevano questo rumore grezzo direttamente nei software di riconoscimento vocale, che faticavano con voci sovrapposte, lingue mutevoli e qualità audio scarsa. EchoNet affronta il problema come una pipeline ingegneristica anziché come un singolo modello sofisticato. Si parte estraendo la traccia audio dai video integrali della partita e convertendola in un formato standard e di alta qualità. Il sistema poi passa al dominio delle frequenze, concentrandosi sulla gamma in cui si colloca la voce umana e sopprimendo i rimbombi dei bassi e gli artefatti stridenti. Uno strumento di deep learning chiamato Demucs separa ulteriormente i suoni simili alla voce dal resto, lasciando una traccia molto più chiara per le fasi successive.

Insegnare alle macchine a distinguere voci e rumore
Una volta che il suono è stato ripulito, EchoNet deve stabilire quando qualcuno sta effettivamente parlando e se quella voce appartiene a un cronista o alla folla. A questo scopo gli autori utilizzano un rilevatore neurale di attività vocale che scansiona l’audio in finestre brevi e etichetta ogni momento come parlato o non parlato. I frammenti di parlato rilevati vengono quindi esaminati più attentamente. I segmenti che mostrano il ritmo e la struttura coerenti del linguaggio parlato vengono etichettati come commento, mentre quelli che assomigliano a esplosioni di energia caotica vengono etichettati come spettatori. Questa separazione è importante: le frasi del cronista veicolano significato tattico e narrativo, mentre le reazioni della folla segnalano principalmente picchi emotivi come i gol o i quasi gol. Separando queste fonti, il sistema può trattarle in modo diverso nelle analisi successive.
Trasformare molte lingue in una sola narrazione
EchoNet invia ogni segmento di commento a diverse versioni del modello di riconoscimento vocale automatico Whisper, comprese varianti standard e ottimizzate per la velocità. Questi modelli sono addestrati su centinaia di migliaia di ore di audio multilingue, rendendoli adatti ai principali campionati europei, dove le emittenti alternano inglese, tedesco, spagnolo, italiano, francese e altre lingue. Il sistema registra il tempo, la lingua e la trascrizione di ogni segmento in file JSON strutturati legati ai tempi delle frazioni di gioco. Per le clip non in inglese, EchoNet prima trascrive nella lingua originale e poi invia il testo a un motore di traduzione per ottenere versioni in inglese. Questo design in due fasi mantiene separati gli errori di trascrizione e traduzione, il che aiuta i ricercatori a diagnosticare i guasti e a confrontare il comportamento specifico per lingua.
Misurare quanto funziona bene
Poiché una pipeline è forte solo quanto il suo anello più debole, gli autori valutano EchoNet da più angolazioni. Introducono un nuovo punteggio di “Report Accuracy” che converte i tradizionali tassi di errore sulle parole in una percentuale più intuitiva di contenuto praticamente corretto. Su tre dataset — incluso il loro nuovo EchoNet++ composto da 20 partite complete — il preprocessing con EchoNet riduce costantemente gli errori di trascrizione e aumenta la Report Accuracy di diversi punti per ogni modello Whisper testato. Anche le misure di qualità del segnale, che stimano quanto comprensibile apparirebbe il parlato a un ascoltatore umano, migliorano nettamente dopo filtraggio, riduzione del rumore e normalizzazione. Studi di ablation, in cui componenti individuali come il filtro passa-banda o il rilevatore vocale vengono rimossi, mostrano che ogni fase contribuisce in modo significativo sia alla chiarezza sia alla correttezza.
Cosa significa per tifosi e analisti
In termini pratici, EchoNet ed EchoNet++ offrono un modo affidabile per trasformare ore di commento multilingue e rumoroso in testo pulito, sincronizzato nel tempo, e indicatori di folla. Con questa base, gli sviluppatori possono rilevare automaticamente eventi chiave dal tono e dalle parole del cronista, mettere in corrispondenza quei momenti con picchi nella reazione del pubblico e creare riassunti dettagliati o reel di highlight senza registrazioni manuali. Fondamentale, dataset e codice sono rilasciati per uso di ricerca, offrendo alla comunità una piattaforma condivisa e riproducibile per studiare il calcio attraverso il suono. Per tifosi e analisti, questo lavoro spinge la copertura sportiva verso un futuro in cui la colonna sonora della partita diventa tanto ricercabile e analizzabile quanto il video stesso.
Citazione: Majeed, F., Nazir, M., Agus, M. et al. EchoNet++: A multilingual soccer match audio commentary dataset. Sci Rep 16, 8884 (2026). https://doi.org/10.1038/s41598-026-39884-8
Parole chiave: analisi del calcio, audio sportivo, riconoscimento vocale, commento multilingue, analisi delle trasmissioni