Clear Sky Science · it
Portare la convalida incrociata nel mondo reale per valutare la trasferibilità dei modelli satellitari della vegetazione
Perché osservare l’erba dallo spazio conta
Le praterie nutrono il bestiame, sostengono la fauna selvatica e immagazzinano carbonio: molti allevatori e conservazionisti si affidano oggi ai satelliti per valutare quanta biomassa vegetale sia presente sul terreno. Nuove mappe promettono viste quasi in tempo reale delle condizioni dei pascoli, ma la loro accuratezza in anni anomali — come siccità intense o stagioni molto piovose — viene spesso data per scontata. Questo studio pone una domanda semplice ma cruciale: quanto resistono i modelli informatici alla base di queste mappe satellitari quando il mondo reale non assomiglia ai dati su cui sono stati addestrati?
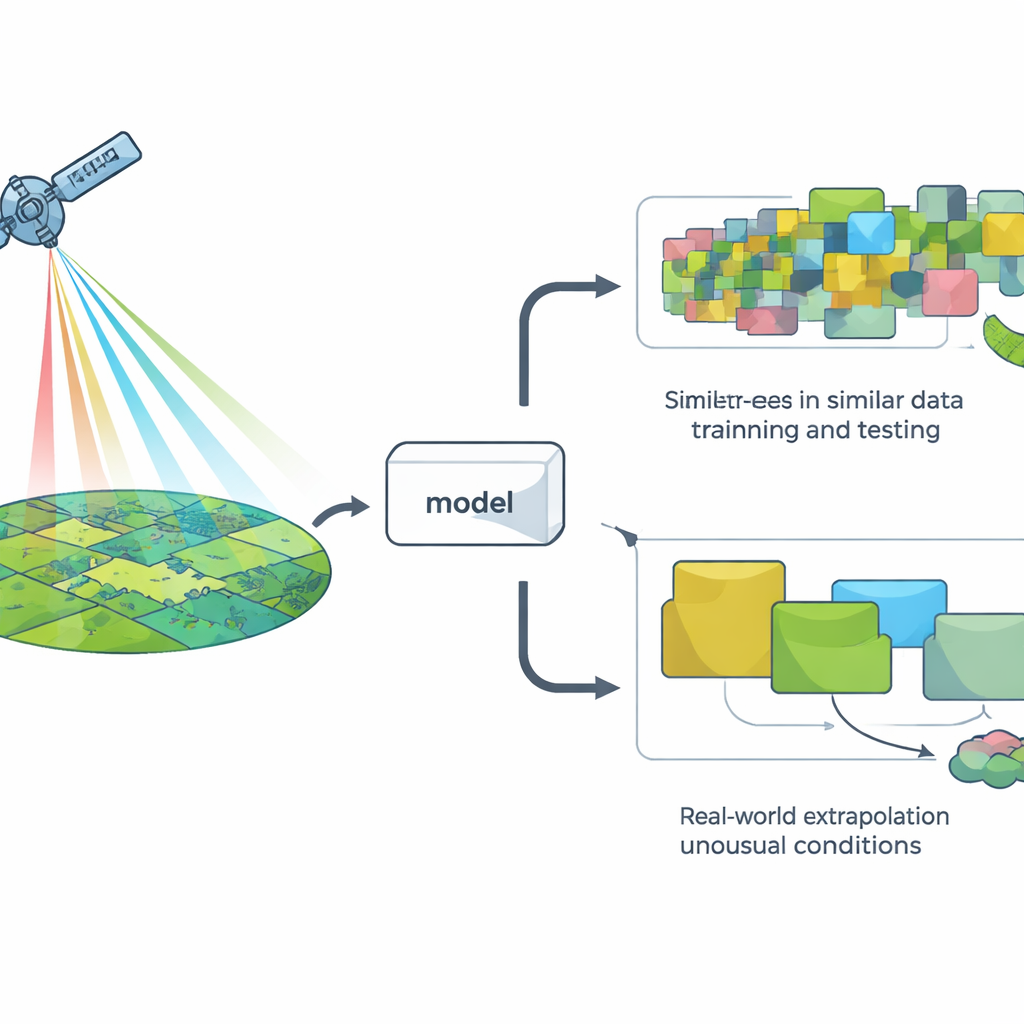
Valutare i modelli nel modo facile rispetto al modo difficile
Per giudicare un modello, i ricercatori usano solitamente un metodo chiamato convalida incrociata: nascondono alcuni dati, addestrano il modello sul resto e verificano quanto bene predice i punti nascosti. La versione più comune suddivide i dati casualmente, cosa che funziona per molti problemi ma presuppone silenziosamente che tutte le osservazioni siano indipendenti. Nei paesaggi questa ipotesi spesso non regge: luoghi vicini e anni adiacenti tendono a somigliare tra loro osservati dallo spazio. Di conseguenza, le suddivisioni casuali possono far sembrare che un modello affronti situazioni “nuove” quando in realtà sta soprattutto vedendo altro dello stesso tipo.
Mettere i modelli satellitari alla prova nel mondo reale
Gli autori hanno raccolto quasi 10.000 misure di campo della biomassa erbacea in piedi — in pratica quanta materia vegetale sfruttabile era presente — da una steppa a erba corta in Colorado, raccolte in 10 anni. Hanno associato queste misure a immagini satellitari dettagliate e poi addestrato sette diversi tipi di modelli computazionali, che vanno da approcci semplici lineari a complessi sistemi ad albero decisionale. Invece di usare solo suddivisioni casuali, hanno testato cinque modalità di esclusione dei dati: per parcelle scelte a caso, per lotti di pascolo, per tipo di sito ecologico, per anno e per gruppi di pixel che risultavano spettralmente distinti. Questi ultimi due approcci, in particolare il raggruppamento per anno e per cluster spettrali, hanno costretto i modelli a predire condizioni che fossero realmente diverse da quelle già viste.
Quando il futuro non somiglia al passato
Nel complesso, le prestazioni dei modelli sono diminuite nettamente man mano che i test diventavano più impegnativi. Con la suddivisione casuale, modelli complessi come le foreste casuali sembravano impressionanti, spiegando circa tre quarti della variabilità della biomassa. Ma quando è stato chiesto loro di prevedere per un anno completamente non visto — un compito realistico per il monitoraggio quasi in tempo reale — la loro accuratezza è calata, e modelli relativamente semplici basati su poche variabili satellitari combinate hanno fatto altrettanto o meglio. Nel test più estremo, dove i dati sono stati raggruppati per essere il più diversi possibile l’uno dall’altro, l’accuratezza dei modelli complessi è crollata, mentre i modelli semplici migliori hanno mantenuto prestazioni moderate e più prevedibili. Lo studio ha inoltre mostrato che i modelli complessi erano molto sensibili alla presenza nel training di condizioni rare, come siccità severe, talvolta comportandosi molto male in quegli scenari ad alto rischio.
Stabili cavalli da lavoro battono sprinter appariscenti
Oltre all’accuratezza pura, il gruppo ha esaminato quanto fosse coerente ciascun modello quando veniva riaddestrato con diversi sottoinsiemi di anni. I metodi più semplici, in particolare la regressione PLS (partial least squares), tendevano a individuare ripetutamente gli stessi segnali satellitari chiave, richiedevano poche scelte di ottimizzazione e producevano risultati più stabili nel tempo. Gli approcci più complessi spesso cambiavano gli input su cui si basavano, necessitavano di molte impostazioni di tuning diverse e mostravano grandi oscillazioni di prestazione da un addestramento all’altro. Per i gestori del territorio che devono aggiornare le mappe ogni anno con nuovi dati, questo tipo di stabilità può essere importante quanto l’accuratezza massima in un anno favorevole.
Cosa significa usare le mappe satellitari sul campo
Per chi dipende dalle mappe satellitari della vegetazione per decidere quando e dove far pascolare il bestiame, reagire alla siccità o monitorare la salute degli ecosistemi, questo studio porta un messaggio chiaro. Le abitudini di test comuni che mescolano i dati a caso possono fornire un quadro eccessivamente ottimistico di come un modello si comporterà quando il clima oscillerà verso estremi o quando sarà applicato in nuovi contesti. Quando i modelli vengono valutati in modi che imitano il loro uso nel mondo reale — prevedendo per anni nuovi, per contesti ecologici diversi o per condizioni raramente osservate — metodi più semplici e ben comportati possono superare quelli sofisticati e offrire indicazioni più affidabili. In pratica, ciò significa che gli sviluppatori dovrebbero riportare le prestazioni dei loro modelli sotto diversi test più severi e realistici, e gli utenti dovrebbero cercare prodotti la cui accuratezza sia stata verificata nelle situazioni difficili che è più probabile che incontrino.
Citazione: Kearney, S.P., Augustine, D.J., Porensky, L.M. et al. Bringing cross-validation into the real world to evaluate transferability of satellite-based vegetation models. Sci Rep 16, 9383 (2026). https://doi.org/10.1038/s41598-026-39866-w
Parole chiave: mappatura della vegetazione da satellite, convalida incrociata, biomassa delle praterie, modelli di apprendimento automatico, monitoraggio della siccità