Clear Sky Science · it
Riconoscimento del luogo robusto a variazioni di illuminazione usando pseudo-LiDAR da immagini omnidirezionali
Robot che non si perdono mai al buio
Immaginate un robot in grado di riconoscere la propria posizione in un edificio, sia che sia mezzogiorno con il sole che entra dalle finestre, sia che sia tardi di sera con solo poche lampade accese. Questo articolo presenta un nuovo modo per fornire ai robot questo tipo di senso del luogo affidabile usando soltanto una singola fotocamera relativamente economica. Convertendo immagini piatte in informazioni 3D, i ricercatori rendono la navigazione robotica molto meno sensibile a ombre, riverberi e altri cambiamenti di illuminazione che normalmente confondono i sistemi basati sulla visione.
Perché trovare lo stesso posto due volte è difficile
Per un robot, il “riconoscimento del luogo” significa capire: «Sono già stato qui», in modo da potersi localizzare su una mappa e navigare in sicurezza. I sistemi tradizionali si basano su fotocamere convenzionali o su sensori di distanza laser noti come LiDAR. Le fotocamere sono economiche e catturano ricche informazioni di colore e texture, ma la loro visione cambia drasticamente fra giornate nuvolose, soleggiate o notturne. Il LiDAR è molto più stabile perché misura direttamente le distanze, ma è ingombrante e costoso. Alcuni robot combinano più sensori, aumentando però prezzo e complessità. Gli autori di questo lavoro scelgono una via diversa: mantengono l’hardware semplice, usando solo una fotocamera omnidirezionale che osserva tutto intorno al robot, e potenziano il software in modo che il robot ragioni sulla struttura 3D invece che sull’aspetto grezzo.
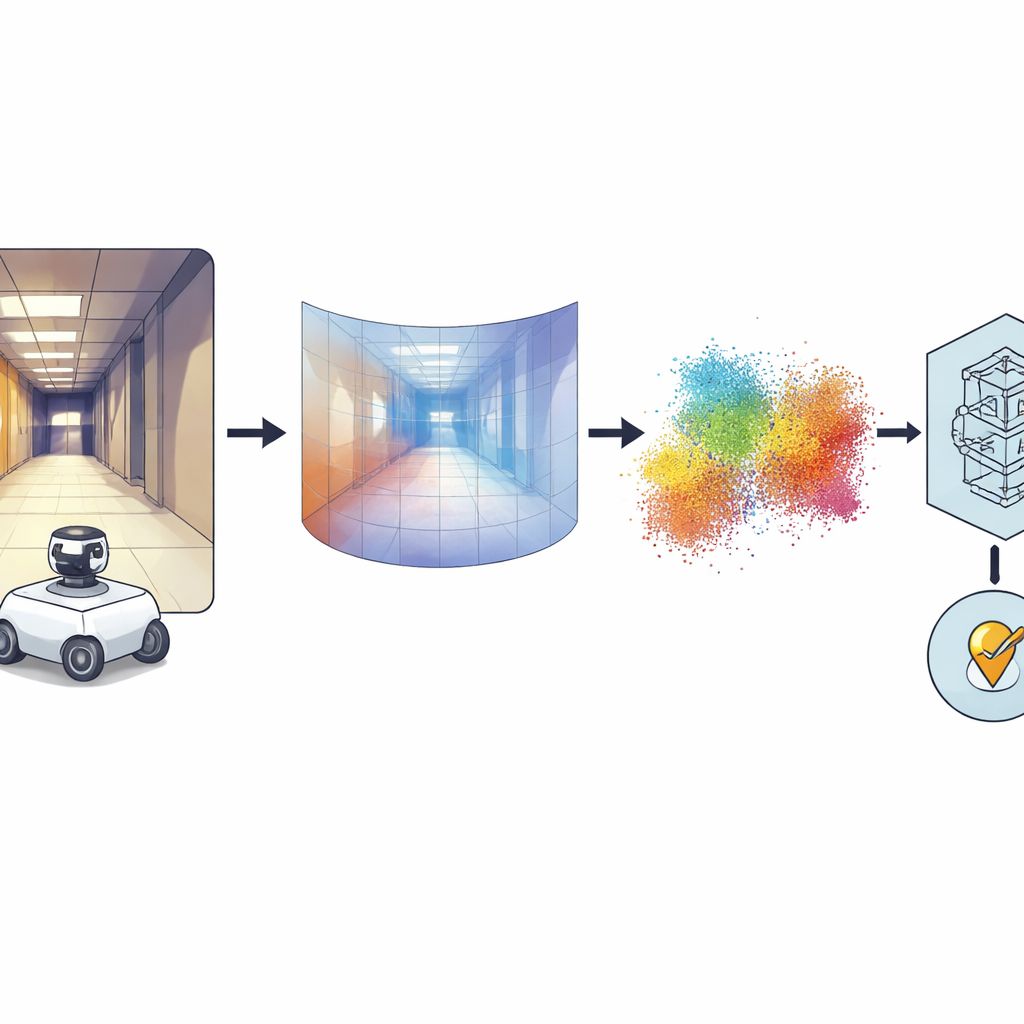
Dalle foto a 360° alle forme 3D
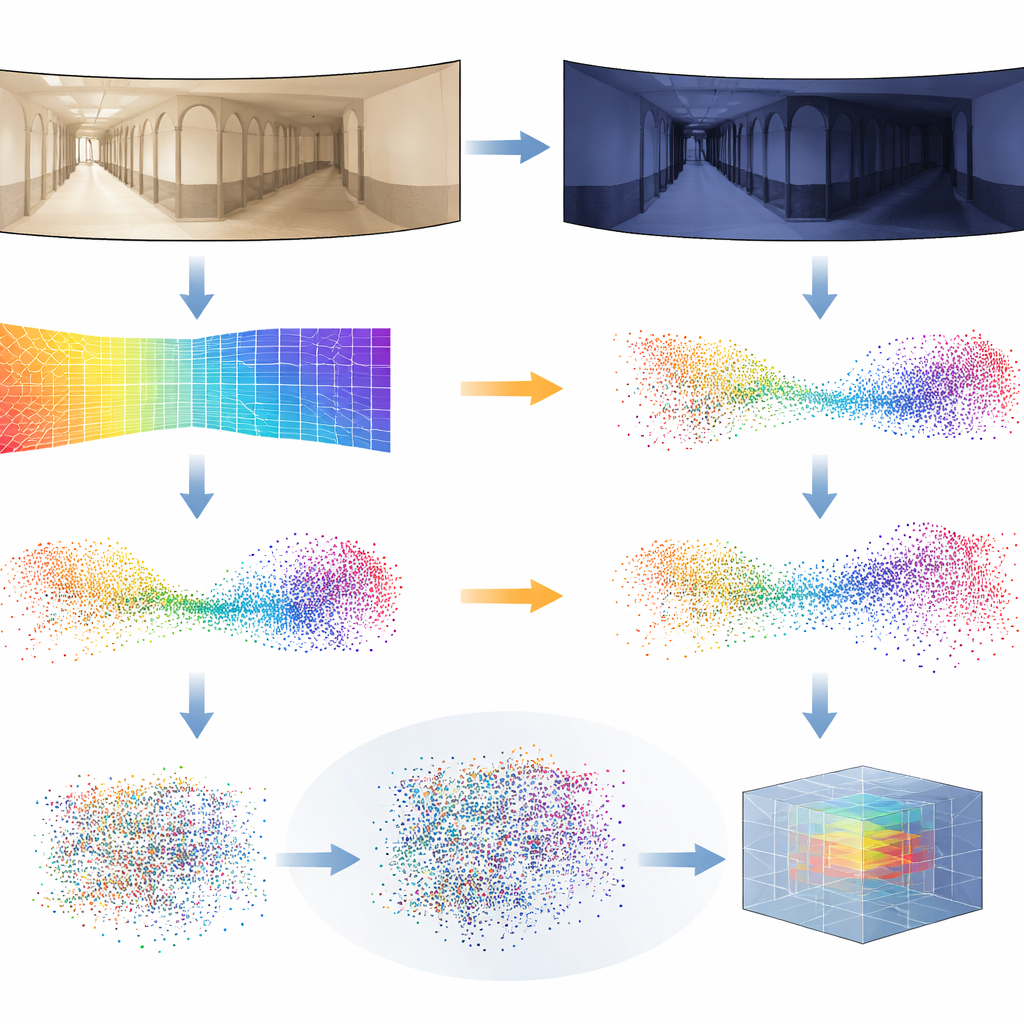
L’idea chiave è convertire ogni immagine panoramica in una mappa di profondità densa, dove ogni pixel codifica quanto è lontana quella parte della scena dalla fotocamera. Per farlo, gli autori si affidano a un potente modello “fondamentale” chiamato Distill Any Depth, che ha imparato a inferire la profondità da enormi collezioni di immagini. La mappa di profondità risultante viene poi trasformata in una nuvola di punti 3D—una sorta di LiDAR virtuale, o pseudo-LiDAR—senza bisogno di un vero scanner laser. Ulteriori elaborazioni ripuliscono gli artefatti introdotti dallo specchio speciale usato per la fotocamera a 360 gradi, così che le regioni mancanti o occluse vengano ricostruite. Infine, una rete neurale chiamata MinkUNeXt, progettata per lavorare direttamente su nuvole di punti 3D, comprime ogni nuvola in un’impronta compatta che cattura la disposizione generale del luogo.
Insegnare al sistema a ignorare i trucchi dell’illuminazione
Le stime di profondità non sono perfette, specialmente quando l’illuminazione cambia drasticamente da un momento all’altro. Per rendere il sistema robusto, i ricercatori introducono un nuovo trucco di addestramento che chiamano Distilled Depth Variations. Invece di fidarsi di un singolo modello di profondità, mescolano intenzionalmente le predizioni di profondità provenienti da diverse versioni più piccole e meno accurate dello stimatore di profondità. Questo “rumore” controllato imita i tipi di distorsioni che compaiono sotto differenti condizioni di illuminazione, costringendo la rete 3D a imparare cosa conta davvero nella geometria di un luogo e cosa può essere ignorato in sicurezza. Arricchiscono inoltre ogni punto 3D con informazioni sui contorni e sulla forza della texture dell’immagine—caratteristiche che tendono a essere più stabili rispetto al colore puro in presenza di variazioni di illuminazione.
Dimostrare che funziona nel mondo reale
Per verificare il loro approccio, il team ha usato dataset pubblici impegnativi di percorsi robotici indoor. In queste raccolte, un robot percorre corridoi e stanze più volte sotto luce nuvolosa, pieno sole e di notte, mentre mobili e persone si muovono. Gli autori hanno addestrato il loro sistema usando solo immagini diurne nuvolose di un edificio e poi lo hanno valutato su tutti gli edifici e le condizioni di illuminazione, incluse scene mai viste prima. Il loro metodo pseudo-LiDAR ha costantemente eguagliato o superato le tecniche 2D basate su immagini più avanzate e altri sistemi 3D, soprattutto nei casi più difficili come le registrazioni notturne o il trasferimento in ambienti completamente nuovi. Hanno anche dimostrato che la stessa pipeline funziona con normali fotocamere frontali, non solo con quelle panoramiche, sostituendo la proiezione appropriata dalla profondità al 3D.
Cosa significa per i robot del futuro
In termini pratici, questo lavoro mostra che un robot può ottenere una consapevolezza simile al LiDAR dell’ambiente circostante usando solo una singola fotocamera e software intelligente. Concentrandosi sulla struttura 3D invece che sui dettagli volubili di illuminazione e colore, il sistema può riconoscere i luoghi in modo affidabile tra giorno, notte e cambiamenti meteorologici, mantenendo al contempo l’hardware semplice ed economico. Questo potrebbe rendere la navigazione indoor robusta più accessibile per robot di servizio, veicoli da magazzino e dispositivi assistivi, e apre la strada a sistemi futuri che combinano profondità con comprensione di scene di livello più alto per un’autonomia ancora più affidabile.
Citazione: Cabrera, J.J., Alfaro, M., Gil, A. et al. Robust place recognition under illumination changes using pseudo-LiDAR from omnidirectional images. Sci Rep 16, 8817 (2026). https://doi.org/10.1038/s41598-026-39848-y
Parole chiave: localizzazione robot, visione 3D, riconoscimento dei luoghi, stima della profondità, fotocamere omnidirezionali