Clear Sky Science · it
Architettura a microservizi federata con blockchain per analisi sanitarie scalabili e rispettose della privacy
Perché i tuoi dati sanitari hanno bisogno di protezione più intelligente
Ogni visita in clinica, ogni esame del sangue e ogni rilevazione da uno smartwatch si aggiungono a una montagna sempre crescente di dati sanitari. Quelle informazioni potrebbero aiutare i medici a individuare le malattie prima e a personalizzare le terapie, ma sono frammentate tra ospedali e dispositivi e protette da rigide norme sulla privacy. Questo articolo esplora un nuovo modo per sfruttare il potenziale di quei dati senza lasciarli trapelare, combinando tre idee moderne dell’informatica in un progetto pratico per gli ospedali.
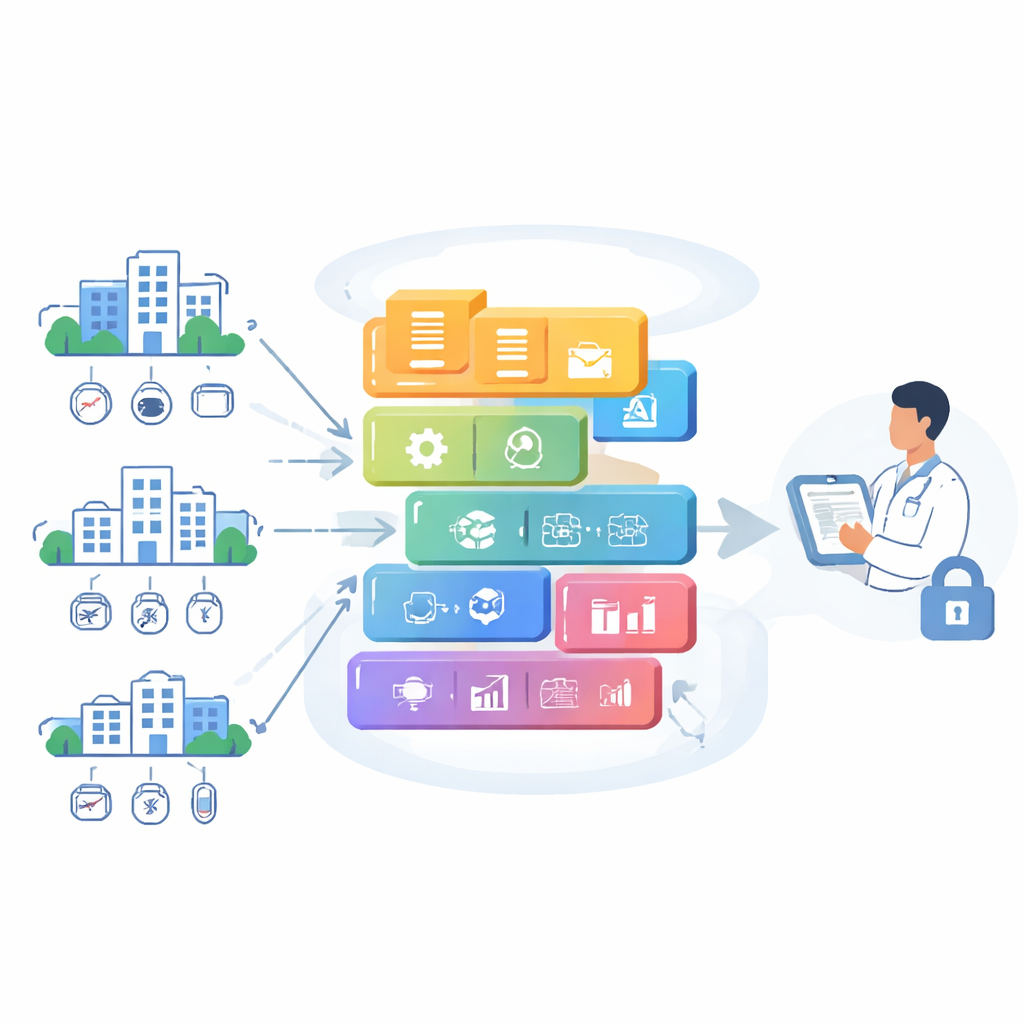
Spezzare il sistema informatico dell’ospedale in blocchi più piccoli
La maggior parte degli ospedali si affida ancora a grandi sistemi software tutto-in-uno che gestiscono ogni cosa, dall’archiviazione delle cartelle all’esecuzione di strumenti predittivi. Questi design “tutto in una scatola” sono difficili da scalare, lenti da aggiornare e rischiosi se qualcosa si guasta o viene violato. Gli autori propongono invece di suddividere il sistema in molti servizi piccoli e mirati che svolgono ciascuno un compito specifico, come pulire i dati in arrivo, eseguire un modello predittivo o fornire una dashboard web. Questi servizi girano in container e sono gestiti da una piattaforma di orchestrazione che può avviarli, fermarli o duplicarli su richiesta. Ciò permette al sistema di crescere agevolmente man mano che si aggiungono pazienti e cliniche, e isola i problemi in modo che un guasto in una parte non comprometta l’intera rete.
Addestrare modelli predittivi condivisi senza scambiare dati grezzi
Una sfida importante in medicina è che ogni ospedale possiede solo una vista parziale della popolazione, e mettere insieme tutti i registri in un unico enorme database infrangerebbe molte regole sulla privacy. L’articolo utilizza l’apprendimento federato per aggirare questo ostacolo. In questa configurazione, il modello predittivo si sposta presso ogni ospedale, apprende dai dati locali e invia indietro soltanto aggiornamenti basati su calcoli matematici anziché nomi, valori di laboratorio o note cliniche. Un coordinatore centrale fonde questi aggiornamenti in un modello globale più robusto e lo rimanda per il giro successivo. Misure aggiuntive, come l’introduzione di rumore calibrato e la cifratura degli aggiornamenti, rendono molto difficile per un attaccante ricostruire dettagli sui singoli pazienti a partire da questi messaggi.
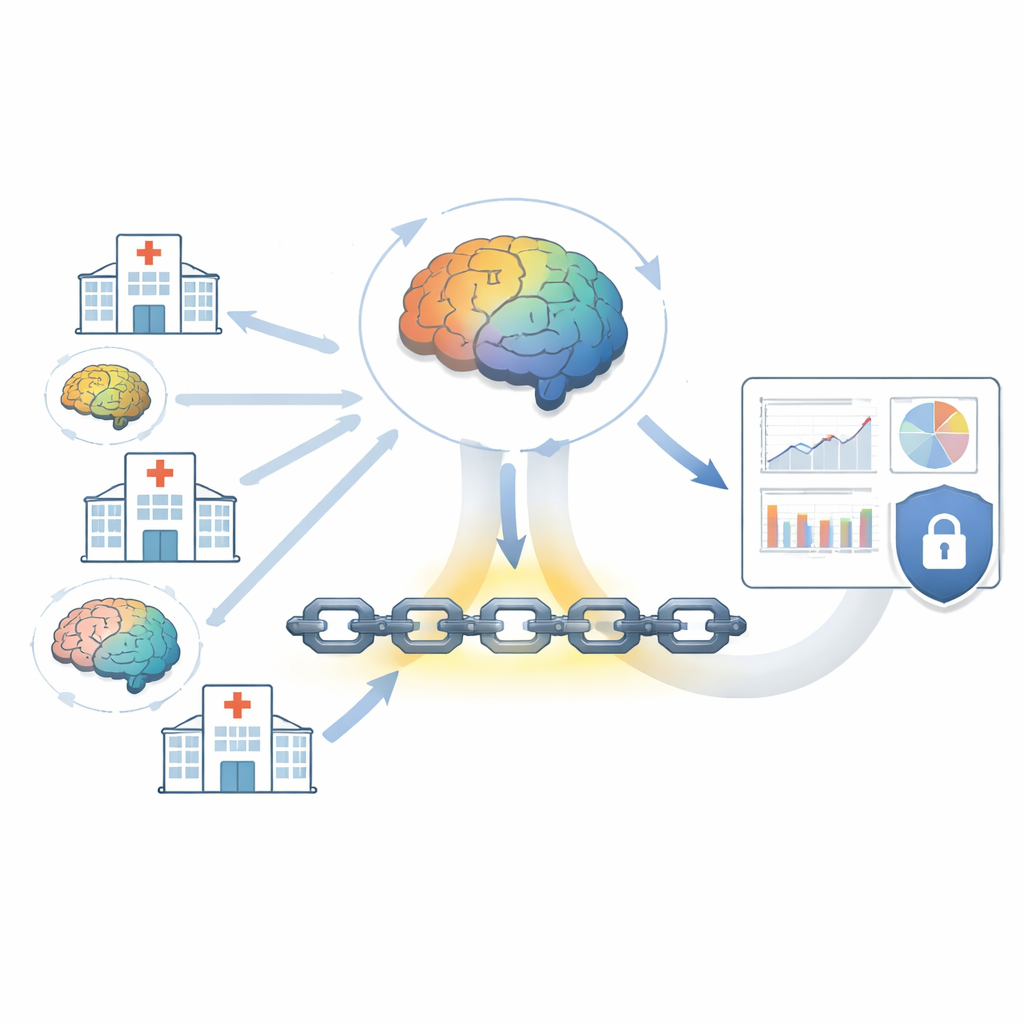
Bloccare la traccia delle azioni su un registro a prova di manomissione
Le normative sulla privacy moderne non si limitano a chi può vedere i dati, ma richiedono anche di dimostrare cosa è avvenuto e quando. Per affrontare questo aspetto, il framework registra eventi importanti—come l’aggiornamento di un modello o l’effettuazione di una previsione—su una blockchain autorizzata. Si tratta di un registro digitale condiviso in cui possono scrivere solo le parti approvate, e una volta aggiunta una voce non può essere modificata silenziosamente. Regole di controllo “intelligenti” su questo registro verificano che gli aggiornamenti del modello in arrivo siano validi e che le regole di accesso siano rispettate. Se qualcuno prova a inserire un aggiornamento falso o a riprodurne uno vecchio, la discrepanza viene rilevata e bloccata, fornendo una solida traccia di audit per i regolatori e i team di conformità degli ospedali.
Mettere il sistema alla prova con pazienti reali e simulati
Per verificare se questo progetto fosse più della sola teoria, gli autori hanno costruito un sistema completo e lo hanno testato su due tipi di dati. Uno era un ampio insieme di cartelle cliniche generate al computer, pensate per imitare il traffico reale degli ospedali; l’altro era una raccolta reale di registri di persone trattate per diabete in oltre cento ospedali statunitensi. L’obiettivo era prevedere chi avrebbe sviluppato il diabete di tipo 2 entro sei mesi. L’architettura combinata ha raggiunto circa il 95 percento di accuratezza, superando sia un modello centralizzato tradizionale addestrato su dati aggregati sia modelli separati addestrati in isolamento in ciascun ospedale. Contemporaneamente, la disposizione a microservizi ha ridotto i tempi di risposta quasi della metà e ha permesso al sistema di riprendersi dai guasti circa dieci volte più velocemente rispetto a un design monolitico più vecchio.
Cosa potrebbe significare per l’assistenza futura
Nel loro insieme, i risultati suggeriscono che gli ospedali non devono scegliere tra analisi potenti e forte protezione della privacy. Suddividendo il software in parti modulari, permettendo ai modelli di apprendere dove risiedono i dati e registrando ogni passo importante su un registro resistente alle manomissioni, l’approccio proposto fornisce previsioni più rapide, maggiore accuratezza, meno interruzioni di sistema e nessuna violazione dei dati riuscita negli attacchi simulati. Per i pazienti, questo potrebbe tradursi in avvisi più precoci per condizioni come il diabete senza che le loro cartelle personali lascino mai le istituzioni di origine. Per i sistemi sanitari, offre una tabella di marcia verso strumenti digitali più intelligenti e affidabili che possono espandersi su regioni e nazioni pur rispettando norme rigorose di privacy e sicurezza.
Citazione: Harshith, M., Ansari, Z.A., Fatima, S. et al. Federated microservices architecture with blockchain for privacy-preserving and scalable healthcare analytics. Sci Rep 16, 9023 (2026). https://doi.org/10.1038/s41598-026-39837-1
Parole chiave: analisi sanitaria, apprendimento federato, microservizi, blockchain, privacy dei pazienti