Clear Sky Science · it
Offload dinamico dei compiti nelle reti veicolari usando modelli linguistici di grandi dimensioni per decisioni adattative a bassa latenza
Aiuto più intelligente per le auto impegnate
Le auto connesse di oggi gestiscono navigazione, allarmi di sicurezza, sensori e persino funzioni di guida autonoma—tutte attività che richiedono calcolo rapido. Tuttavia, il computer di bordo e la batteria di un singolo veicolo hanno limiti, soprattutto nel traffico urbano affollato. Questo articolo esplora un nuovo modo di condividere quel carico digitale usando un sistema di intelligenza artificiale simile ai modelli linguistici di grandi dimensioni che stanno dietro ai moderni chatbot. Collocato nelle unità stradali, questo AI aiuta a decidere, in tempo reale, dove ogni auto dovrebbe inviare i propri “compiti” digitali affinché vengano eseguiti rapidamente e con minor consumo energetico.
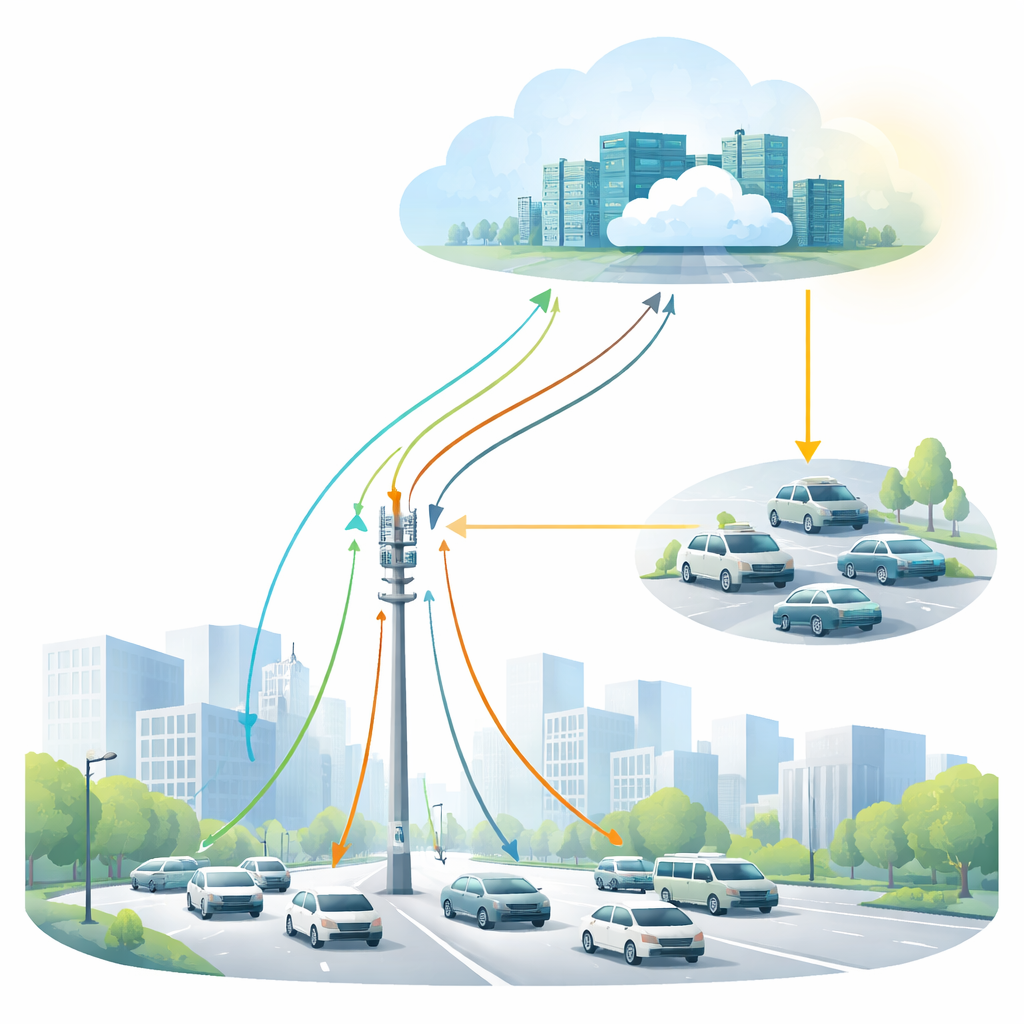
Come le auto condividono i loro compiti digitali
In una rete di traffico moderna, i veicoli generano costantemente piccoli compiti di calcolo: analisi dei dati dei sensori, coordinamento con auto vicine o consultazione di mappe e flussi di traffico. Ogni compito può essere gestito in tre modi: il veicolo può elaborarlo internamente, inviarlo a un altro veicolo meglio attrezzato oppure scaricarlo su un computer stradale o cloud. La sfida è scegliere l’opzione migliore in una frazione di secondo mentre le auto si muovono ad alta velocità e le connessioni di rete appaiono e scompaiono. I metodi tradizionali si basano su formule fisse o schemi di addestramento che faticano quando le strade sono affollate, le condizioni cambiano rapidamente o occorre bilanciare molti fattori diversi contemporaneamente.
Mettere un cervello potente sul bordo strada
Gli autori propongono di collocare un modello linguistico di grandi dimensioni (LLM) nei nodi edge stradali—praticamente scatole intelligenti lungo la strada che già aiutano le auto a connettersi alla rete. Invece di leggere frasi, questo LLM legge snapshot strutturati della situazione del traffico: velocità, posizione, carica residua della batteria, potenza di calcolo disponibile e qualità del segnale wireless di ciascun veicolo, insieme a dettagli su ogni compito come urgenza e dimensione. Da questi input multidimensionali, l’LLM “ragiona” su quale auto o nodo edge dovrebbe eseguire un dato compito, considerando insieme velocità, distanza, stabilità del collegamento e costi energetici piuttosto che uno per volta. Agisce come un controllore del traffico per il lavoro digitale, indirizzando ogni compito verso l’opzione più probabile per completarlo in tempo e con il minimo consumo di batteria.
Dalle regole semplici al ragionamento adattativo
Per evidenziare i benefici di questo approccio, lo studio confronta il sistema basato su LLM con due alternative comuni: un metodo semplice basato su regole che usa un punteggio ponderato fisso e modelli di machine learning avanzati basati su alberi (Random Forest e XGBoost). Questi riferimenti trattano la decisione come una formula rigida o una raccolta di alberi decisionali. Funzionano abbastanza bene quando ci sono poche auto e condizioni semplici, ma vacillano man mano che il traffico si densifica, i veicoli si muovono più velocemente o devono essere considerati molti segnali di stato diversi. Al contrario, l’LLM impara relazioni complesse durante l’addestramento e può regolare istantaneamente quali fattori considerare più importanti—per esempio privilegiando una connessione più stabile quando le auto si muovono rapidamente, o risparmiando batteria quando la rete è congestionata.
Cosa rivelano le simulazioni
Gli autori testano il loro framework in un simulatore dettagliato che imita strade cittadine reali, collegamenti wireless e veicoli in movimento. Variano il numero di auto in strada, la velocità e la quantità di informazioni fornite a ogni modello. In tutti questi scenari, il sistema basato su LLM completa più compiti con successo, con minori ritardi e migliore efficienza energetica rispetto sia ai metodi di deep reinforcement learning riportati in lavori precedenti sia ai modelli basati su alberi testati qui. In media, riduce il tempo di attesa dei compiti di circa il 15% e migliora l’efficienza energetica di oltre il 20% rispetto a un robusto baseline di reinforcement learning, completando comunque circa il 97,5% dei compiti. Quando l’LLM è ottimizzato e compresso per girare su una GPU a bordo strada, il suo ritardo decisionale diventa sufficientemente piccolo per applicazioni di guida critiche in termini di tempo.
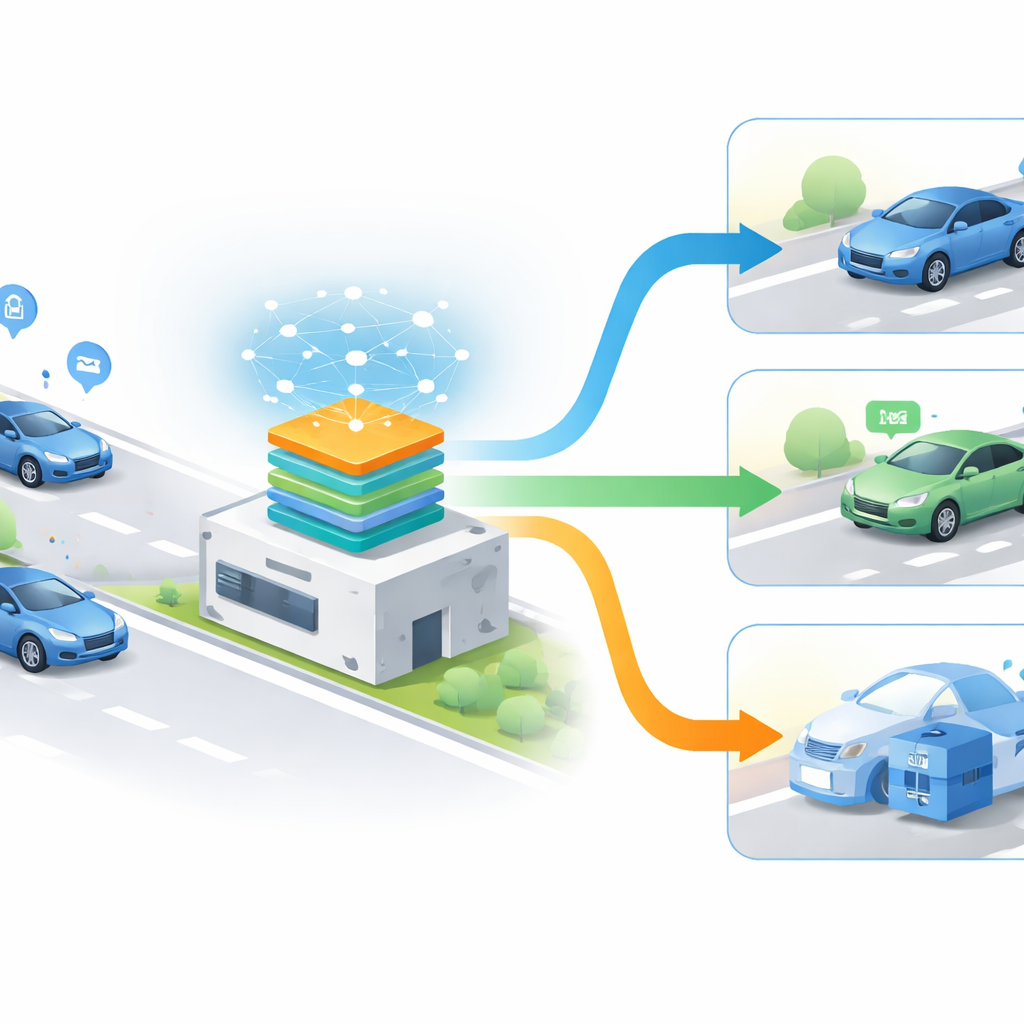
Sfide al margine della strada
Questi guadagni comportano compromessi. I modelli linguistici di grandi dimensioni richiedono molta memoria e potenza di calcolo, il che rappresenta una preoccupazione per le unità stradali che potrebbero dover funzionare su hardware limitato. Con l’aumentare del numero di veicoli e dei compiti, i nodi edge possono sperimentare elevati utilizzi di CPU e memoria. La natura black-box di tali modelli rende inoltre difficile spiegare perché un’auto è stata scelta rispetto a un’altra per un compito specifico. Gli autori discutono modi per attenuare questi problemi, come comprimere il modello, usare aritmetica a precisione inferiore e migliorare strumenti che rivelino come il modello prende le sue decisioni.
Cosa significa per le strade del futuro
Nel complesso, lo studio suggerisce che usare LLM come motori decisionali nelle reti veicolari potrebbe rendere le auto connesse e autonome più reattive e attente all’energia, specialmente in condizioni affollate e in rapido cambiamento. Trattando l’intero sistema stradale come un puzzle vivente e mutevole e ragionando su molti segnali contemporaneamente, questi modelli possono scegliere con più efficacia dove eseguire ogni compito digitale rispetto a regole fisse o a metodi di apprendimento più datati. Se gli ingegneri riusciranno a domare le loro richieste di risorse, l’offload dei compiti guidato dagli LLM potrebbe diventare un ingrediente chiave nei futuri sistemi di trasporto intelligenti, aiutando il traffico a scorrere in modo più fluido e sicuro mantenendo sotto controllo batterie e reti dei veicoli.
Citazione: Trabelsi, Z., Ali, M., Qayyum, T. et al. Dynamic task offloading in vehicular networks using large language models for adaptive low latency decision making. Sci Rep 16, 9144 (2026). https://doi.org/10.1038/s41598-026-39791-y
Parole chiave: edge computing veicolare, offload dei compiti, modelli linguistici di grandi dimensioni, veicoli autonomi, reti a bassa latenza