Clear Sky Science · it
Rilevamento automatico dei fotorecettori a coni usando dati sintetici e deep learning in immagini AOSLO con ottica adattiva confocale
Visioni più nitide dell’occhio vivo
Vedere le cellule sensibili alla luce dell’occhio una per una potrebbe trasformare il modo in cui i medici individuano e monitorano le malattie che portano alla cecità. Oggi gli esperti devono però segnare manualmente queste cellule in immagini della retina fortemente ingrandite, un processo lento, soggettivo e difficilmente scalabile a migliaia di pazienti. Questo studio mostra come modelli informatici addestrati su immagini “finte” realistiche dell’occhio possano imparare a trovare automaticamente queste cellule, aprendo la strada a controlli oculari più rapidi, più affidabili e a una valutazione migliore dei nuovi trattamenti.
Perché le cellule microscopiche sono importanti
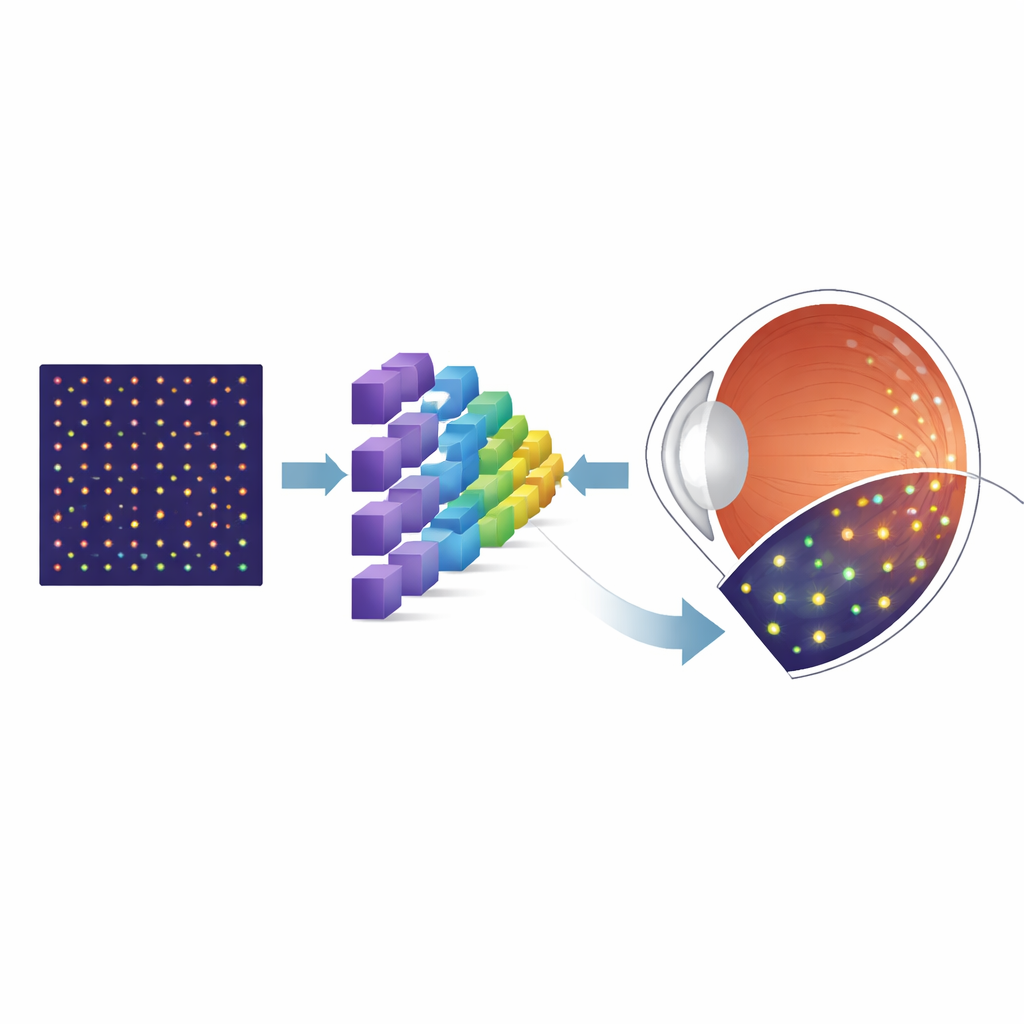
La parte posteriore dell’occhio è rivestita di fotorecettori—cellule specializzate che trasformano la luce nei segnali che il nostro cervello interpreta come visione. I fotorecettori a coni, in particolare, sono essenziali per la visione centrale nitida e la percezione dei colori; la loro perdita è un segno distintivo di molte malattie retiniche. Una potente tecnologia d’imaging chiamata ophthalmoloscope a scansione laser con ottica adattiva (AOSLO) può catturare immagini dettagliate di queste cellule in soggetti vivi. Tuttavia, prima che medici e ricercatori possano misurare la densità dei coni o monitorare i cambiamenti nel tempo, devono prima identificare con precisione ogni singolo cono nell’immagine. La marcatura manuale non richiede solo molto tempo, ma può variare da persona a persona, limitandone l’utilità in cliniche di routine e in grandi studi clinici.
Dalle regole artigianali all’apprendimento dai dati
I primi programmi informatici hanno cercato di automatizzare il rilevamento dei coni seguendo regole fisse: per esempio, cercando punti luminosi di una certa dimensione o spaziatura. Questi metodi basati su regole potevano funzionare bene su immagini pulite di occhi sani, ma spesso avevano difficoltà quando le immagini erano rumorose, leggermente sfocate o provenivano da pazienti con patologie. Il deep learning offre una strategia diversa. Invece di progettare regole a mano, una rete neurale impara i pattern direttamente dagli esempi. Il problema è che questi modelli solitamente richiedono un enorme numero di immagini già accuratamente annotate da esperti—proprio il tipo di dati che scarseggia e costa molto nell’imaging AOSLO.
Costruire un terreno di addestramento virtuale
Per ovviare alla carenza di immagini reali etichettate, i ricercatori hanno usato uno strumento di simulazione chiamato ERICA, capace di generare immagini AOSLO realistiche della tessitura dei coni insieme alla perfetta “verità a terra” della posizione di ogni cono. Hanno creato ampi insiemi di queste immagini sintetiche coprendo molte posizioni della retina, variando sistematicamente le imperfezioni chiave che influenzano le immagini reali, come il rumore casuale e il lieve sfocamento ottico. Hanno quindi addestrato un’architettura di rete neurale specializzata, nota come U-Net, per trasformare ogni immagine di input in una mappa di probabilità che indica dove è più probabile trovare i coni. Dopo questo addestramento iniziale su dati sintetici, il gruppo ha perfezionato il modello usando una collezione molto più piccola di immagini AOSLO reali provenienti da un noto dataset pubblico e infine lo ha testato su immagini indipendenti di un altro laboratorio per valutare la capacità di generalizzazione.

Quanto bene il computer eguaglia gli esperti umani
Il team ha confrontato il loro metodo automatizzato con l’accurata annotazione manuale e con due algoritmi di rilevamento dei coni all’avanguardia. Utilizzando una misura standard di sovrapposizione tra le marcature dei coni previste e quelle manuali, la nuova U-Net ha eguagliato o quasi eguagliato le prestazioni sia dei valutatori esperti sia dei metodi automatizzati concorrenti sul dataset pubblico. Crucialmente, quando è stato testato su un set separato di immagini acquisite a diverse distanze dal centro della visione e raccolte con uno strumento diverso, il modello ha comunque mostrato ottime prestazioni. Ciò suggerisce che l’addestramento intensivo su dati sintetici che coprono un ampio ventaglio di condizioni visive ha aiutato la rete ad apprendere caratteristiche trasferibili alle immagini del mondo reale, anziché adattarsi troppo a una singola macchina o a un gruppo di pazienti specifico.
Cosa potrebbe significare per la cura degli occhi in futuro
Per i non specialisti, il messaggio centrale è che un programma informatico addestrato in larga misura su immagini oculari “virtuali” può oggi individuare i coni reali in scansioni retiniche ad alta risoluzione con un’affidabilità simile a quella degli esperti umani. Rendendo il rilevamento dei coni più rapido, più oggettivo e più facile da applicare su diversi scanner e in diverse cliniche, questo approccio potrebbe contribuire a trasformare l’imaging retinico dettagliato in uno strumento di routine per monitorare le malattie a livello delle singole cellule. A lungo termine, metodi simili basati su dati sintetici potrebbero essere estesi per rilevare altri tipi cellulari e modellare la perdita cellulare legata a malattie, favorendo diagnosi più precoci, un migliore monitoraggio della progressione e una valutazione più precisa di nuovi trattamenti mirati a preservare la vista.
Citazione: Shah, M., Young, L.K., Downes, S.M. et al. Automated cone photoreceptor detection using synthetic data and deep learning in confocal adaptive optics scanning laser ophthalmoscope images. Sci Rep 16, 8313 (2026). https://doi.org/10.1038/s41598-026-39570-9
Parole chiave: imaging retinico, fotorecettori a coni, deep learning, dati sintetici, ottica adattiva