Clear Sky Science · it
Rilevamento delle cadute interpretabile e leggero in una galleria del patrimonio usando YOLOv11-SEFA per il deployment edge
Perché la sicurezza nelle gallerie è importante
Con l'invecchiamento delle società, sempre più persone anziane visitano musei e gallerie del patrimonio—spazi bellissimi che non sono stati progettati pensando al monitoraggio di sicurezza moderno. Una semplice caduta in questi ambienti può causare gravi lesioni, ma cablare gli edifici con nuovi sensori o osservare continuamente i flussi video è costoso, intrusivo e spesso poco pratico. Questo articolo esplora un nuovo modo per rilevare le cadute automaticamente e rapidamente in tali spazi, usando intelligenza artificiale compatta che può essere eseguita vicino alle telecamere senza intasare la rete o invadere la privacy dei visitatori.
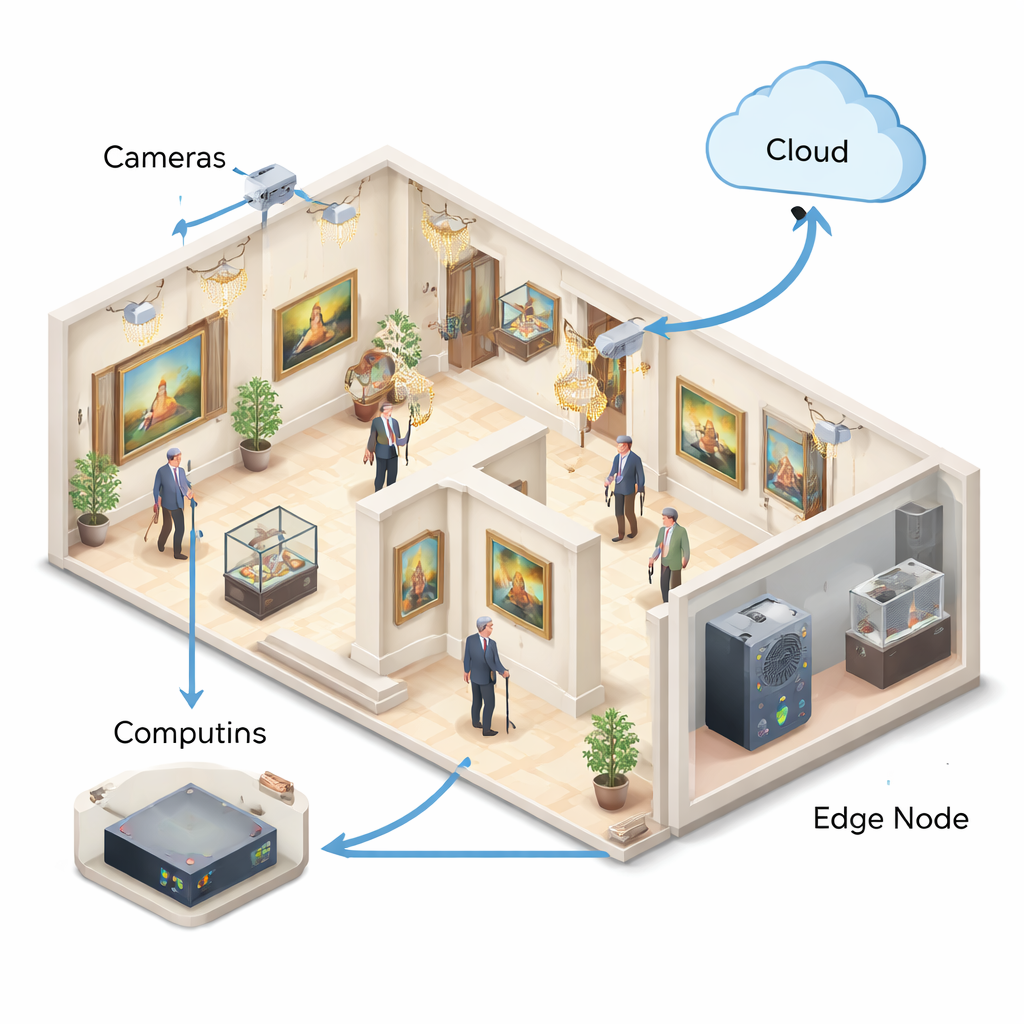
Un luogo difficile da sorvegliare
La Rochfort Gallery a North Sydney, un edificio restaurato degli anni ’20 con soffitti alti, finiture ornate, pavimenti lucidi e vetrine in vetro, è il banco di prova di questo lavoro. Queste caratteristiche lo rendono visivamente ricco per i visitatori ma difficile per le macchine: la luce rimbalza sul vetro, le ombre cambiano durante il giorno e le folle variano. Le regole per la tutela del patrimonio limitano inoltre pratiche come forare, cablare e installare apparecchiature ingombranti. Gli autori sostengono che qualsiasi sistema di rilevamento delle cadute qui deve essere compatto, a basso consumo e rispettoso della privacy, pur essendo sufficientemente affidabile da supportare il personale nel proteggere i visitatori vulnerabili.
Insegnare ai computer come appare una caduta
Per addestrare il loro sistema, il team non si è basato su un piccolo set di dati messo in scena. Al contrario, ha ampliato una raccolta di immagini esistente con migliaia di fotografie aggiuntive scattate in musei, gallerie e centri comunitari. Ogni immagine è stata etichettata come postura normale (ad esempio in piedi o in cammino) o come postura di caduta (sdraiato a terra in diverse orientazioni), e acquisita da vari angoli—montata al soffitto, laterale e a livello degli occhi—in condizioni che vanno dalla luce diurna a stanze dimmerate o illuminate a spot. Hanno intenzionalmente incluso anche scene con parziale ostruzione da mobili o altri visitatori, così come sale affollate, per rispecchiare il disordine e la confusione degli spazi pubblici reali.
Un osservatore intelligente e leggero all'edge
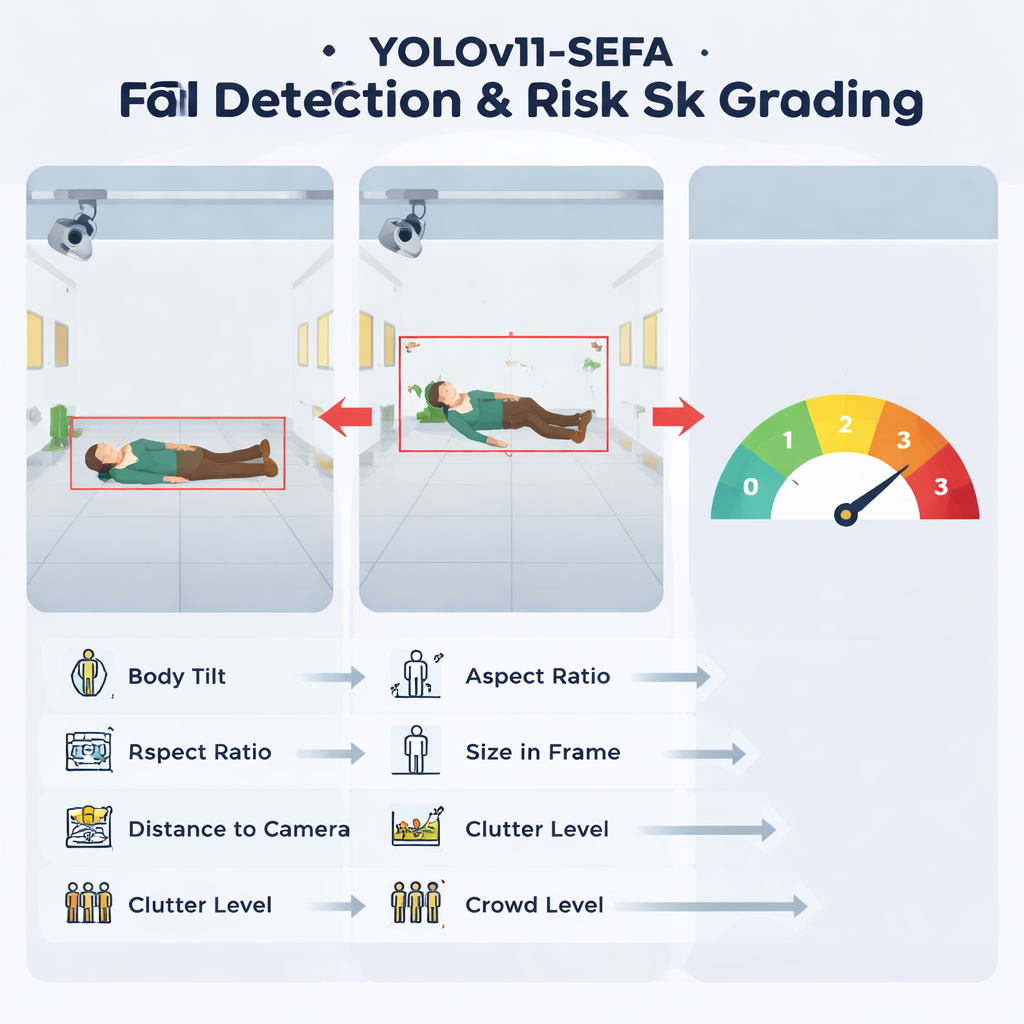
Il nucleo del sistema è una rete di object detection snella chiamata YOLOv11-SEFA, che analizza ogni frame della telecamera e decide se qualcuno è caduto. Piuttosto che costruire un modello più pesante e complesso, gli autori aggiungono due aggiustamenti mirati a un rilevatore veloce esistente in modo che presti particolare attenzione a corpi piccoli o parzialmente nascosti e alle regioni in cui una persona tocca il pavimento. Questo aumenta sia la frazione di cadute vere rilevate sia la precisione delle scatole delimitanti, mantenendo al contempo il carico computazionale sufficientemente basso da poter girare su computer "edge" modesti installati nell'edificio. I test rispetto a diverse alternative popolari mostrano che questo modello ottimizzato offre uno dei migliori compromessi tra accuratezza e velocità, usando solo un piccolo incremento di potenza di calcolo rispetto al punto di partenza.
Da semplici allarmi a un rischio graduato
Invece di limitarsi a segnalare "caduta" o "nessuna caduta", il sistema compie un passo in più e assegna a ogni evento rilevato un livello di rischio da 0 a 3. Per farlo, converte il rilevamento visivo in sei numeri semplici: quanto spazio dell'immagine occupa la persona, quanto è inclinata, quanto appare distante dalla telecamera, quanto è allungato o schiacciato il suo profilo, quanto è visivamente affollata l'area circostante e quante altre persone sono presenti. Un modello decisionale separato, ispirato a opinioni di esperti di sicurezza, combina questi valori in quattro bande: attività normale, postura strana a basso rischio, rischio medio‑alto e cadute ovvie ad alto rischio. È importante che gli autori usino uno strumento di spiegazione per confermare che il modello si basa effettivamente soprattutto su indizi legati alla postura, come inclinazione e forma del corpo, piuttosto che su dettagli di sfondo irrilevanti.
Test nella galleria reale
Il sistema completo collega telecamere, computer edge locali e un servizio cloud in una pipeline a quattro livelli. Le telecamere trasmettono video a bassa frequenza a macchine compatte sullo stesso piano, che eseguono il rilevatore di cadute e generano allarmi; solo brevi clip o sovrapposizioni a mappa di calore vengono inviate al cloud quando necessario, limitando sia la larghezza di banda sia l'esposizione della privacy. In un pilota di 72 ore alla Rochfort Gallery, il sistema ha mantenuto tempi di risposta intorno a un quarto di secondo anche in scene affollate e ha prodotto meno di mezzo falso allarme all'ora nei momenti di picco—per lo più da visitatori accovacciati per scattare foto—mentre le cadute simulate durante le prove sono state tutte rilevate. Gli autori sottolineano che questi numeri provengono da una prova relativamente breve e controllata, ma mostrano che l'approccio è tecnicamente praticabile in un ambiente reale e impegnativo.
Cosa significa per gli spazi pubblici futuri
Per i non esperti, l'esito chiave è che ora è possibile aggiungere un livello automatico e graduato di avviso per cadute ai sistemi di telecamere esistenti in gallerie storiche e edifici pubblici simili senza rebuild significativi o sorveglianza umana costante. Eseguendo un rilevatore efficiente su piccoli computer locali e strutturando con cura come i risultati vengono interpretati e condivisi, il sistema fornisce le prime prove che la tecnologia può sorvegliare silenziosamente in background—individuando cadute probabili, suggerendo quanto possano essere serie e facendo tutto ciò con hardware modesto e attenzione alla privacy. Serviranno prove più ampie e prolungate, oltre a estensioni ad altri tipi di edifici, prima che possa essere considerato uno standard di sicurezza a livello cittadino, ma questo lavoro traccia un percorso chiaro e praticabile in quella direzione.
Citazione: Wu, S., Yang, H., Hu, Y. et al. Interpretable and lightweight fall detection in a heritage gallery using YOLOv11-SEFA for edge deployment. Sci Rep 16, 7795 (2026). https://doi.org/10.1038/s41598-026-39527-y
Parole chiave: rilevamento delle cadute, gallerie intelligenti, edge AI, sicurezza degli anziani, visione artificiale