Clear Sky Science · it
Analisi comparativa delle prestazioni delle mappe di feature quantistiche per l’apprendimento automatico basato su kernel quantistici
Perché questo conta oltre il laboratorio
Man mano che i nostri dati e i problemi diventano più complessi, anche gli strumenti di machine learning migliori di oggi possono avere difficoltà a trovare pattern chiari. I computer quantistici promettono nuovi modi per affrontare questi problemi, ma non è ancora chiaro quando e come possano davvero aiutare. Questo articolo esplora un pezzo pratico di quel puzzle: come progettare e ottimizzare classificatori basati su componenti quantistiche in modo che possano competere con, e talvolta superare, metodi classici consolidati sia su problemi giocattolo sia su un reale set di dati medici.
Trasformare la somiglianza in potenza quantistica
Molti metodi di apprendimento di successo, come le macchine a vettori di supporto, si basano su “kernel” che misurano quanto siano simili due punti dati dopo una trasformazione invisibile in uno spazio di feature più ricco. I computer quantistici possono implementare tali trasformazioni in modo naturale codificando i dati in stati quantistici e confrontando poi quanto due stati si sovrappongono. Gli autori si concentrano su questi kernel quantistici e sulle “mappe di feature” che indicano a un circuito quantistico come convertire numeri ordinari in stati quantistici. Una buona mappa di feature rende più semplice separare dati aggrovigliati; una cattiva spreca l’hardware quantistico. Il lavoro pone due domande chiave: quali mappe di feature funzionano meglio e quanto può migliorare un’accurata ottimizzazione?
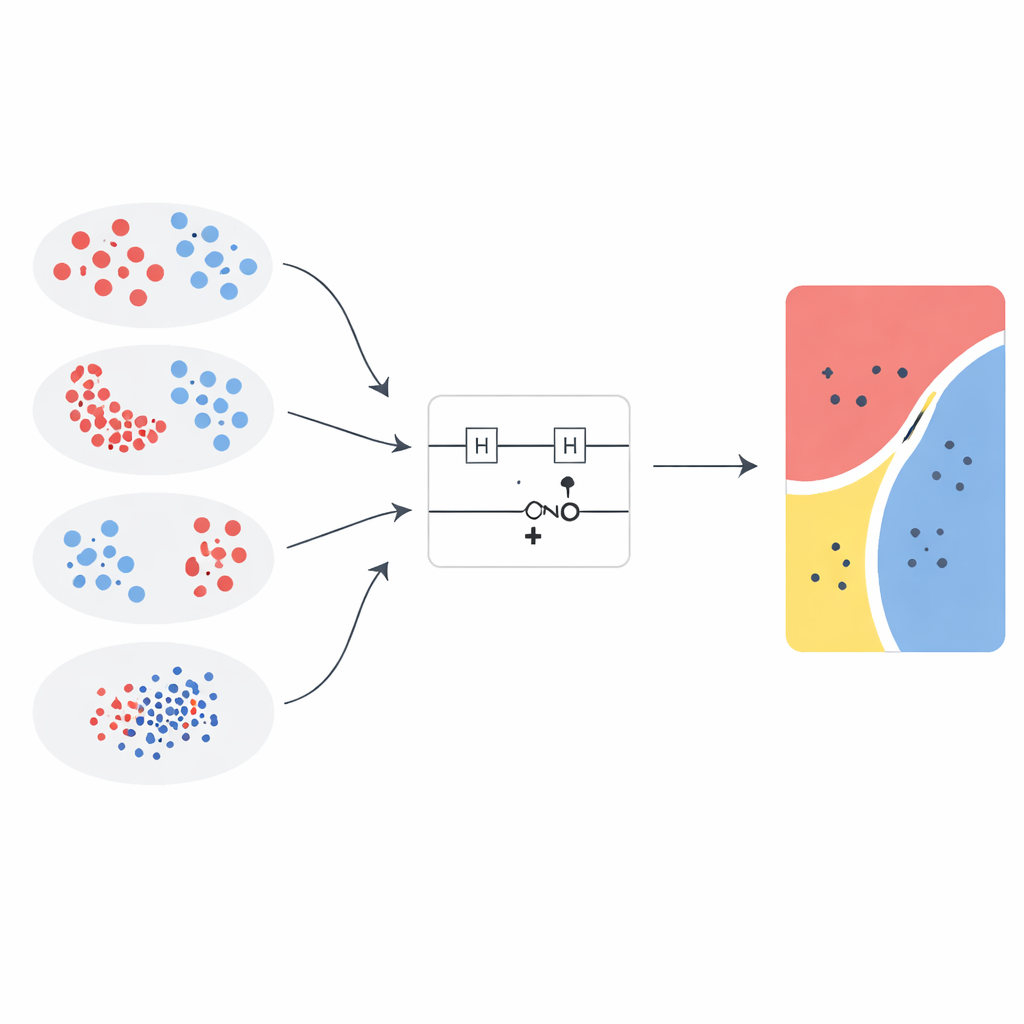
Testare diverse ricette quantistiche
I ricercatori introducono una nuova mappa di feature di ordine elevato e la confrontano con cinque progetti all’avanguardia tratti da lavori precedenti. Ogni mappa utilizza un semplice circuito a due qubit che applica rotazioni su singoli qubit e una porta entangliante, ma le formule matematiche che determinano tali rotazioni differiscono. Per mantenere lo studio focalizzato, la struttura del circuito quantistico, le impostazioni della macchina a vettori di supporto e la procedura di valutazione sono mantenute costanti mentre si varia soltanto la mappa di feature e la sua “forza di rotazione” interna. Ciò rende possibile attribuire i guadagni di prestazione direttamente al modo in cui i dati vengono codificati negli stati quantistici piuttosto che a ulteriori ritocchi dell’algoritmo di apprendimento classico circostante.
Dai pattern giocattolo alla diagnosi del cancro
Il team valuta i kernel quantistici su tre classici problemi di test bidimensionali—cerchi concentrici, lune a mezzaluna e un pattern XOR—oltre che su una versione ridotta del dataset Wisconsin Breast Cancer Diagnostic. Per i dati medici vengono selezionate, mediante un metodo standard di selezione delle feature, due delle caratteristiche basate su immagini più informative. Tutti gli input vengono quindi riscalati nella stessa gamma e alimentati in circuiti poco profondi a due qubit, mantenendo gli esperimenti realistici per i dispositivi quantistici a scala intermedia rumorosi di oggi. Le prestazioni sono confrontate con un ampio insieme di modelli classici, inclusi SVM lineari e con funzione a base radiale, alberi decisionali, foreste casuali, boosting, naïve Bayes, analisi discriminante lineare e perceptron multistrato, utilizzando accuratezza e coefficiente di correlazione di Matthews per catturare sia la correttezza sia l’equilibrio tra le classi.
Cosa hanno rivelato i confronti
Nei dataset di benchmark più semplici, i kernel quantistici migliorati—soprattutto quelli costruiti con la nuova mappa di feature e due di quelle esistenti—raggiungono classificazioni quasi perfette, eguagliando o superando la maggior parte dei concorrenti classici. Sui dati più impegnativi del tumore al seno, le migliori mappe di feature quantistiche restano competitive con forti baseline classiche come i kernel a base radiale e le reti neurali. Un parametro chiave è il fattore di rotazione, che scala quanto i valori di input influenzano le rotazioni quantistiche. Scandendo questo fattore su diversi valori, gli autori mostrano che sceglierlo bene può migliorare sensibilmente le prestazioni, e che il valore ottimale dipende dal dataset. Visualizzazioni degli spazi di feature e dei confini di decisione risultanti mostrano chiaramente che alcune mappe ritagliano regioni di separazione finemente dettagliate e ben allineate, mentre altre lasciano confini distorti o mal posizionati, spiegando la variabilità dei risultati.
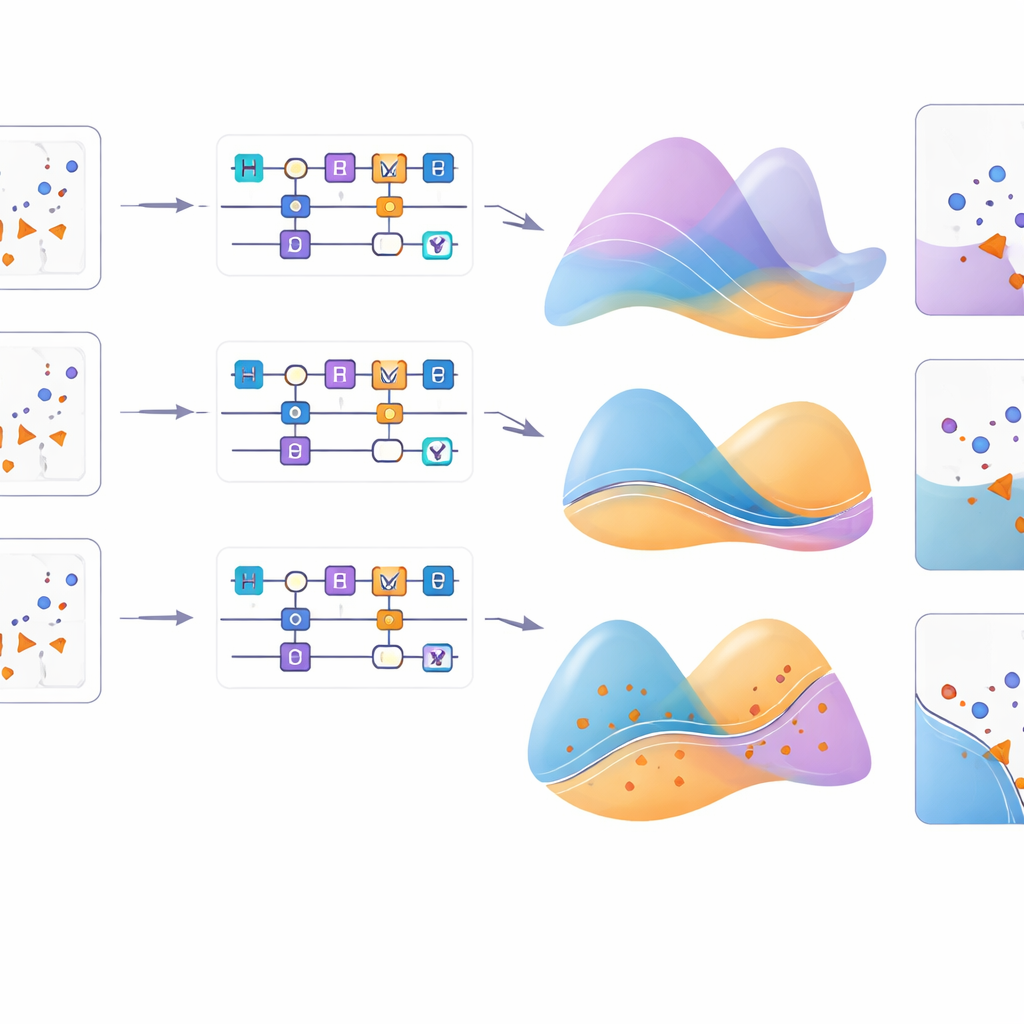
Approfondire il funzionamento
Per comprendere meglio questi effetti, lo studio visualizza come ogni mappa di feature rimodella una griglia di punti di input per problemi diversi. Per il pattern circolare, la maggior parte delle mappe riproduce con successo la struttura sottostante, ma per le lune a mezzaluna e i dati reali sul cancro solo un sottoinsieme di mappe si allinea bene con la distribuzione reale. Esperimenti aggiuntivi variano il tipo di rotazione su singolo qubit utilizzata e confermano che, per certi pattern come l’XOR, la scelta dell’asse di rotazione può contare tanto quanto la formula di codifica dettagliata. Complessivamente, la nuova mappa di feature si classifica costantemente tra le migliori, particolarmente se abbinata a un appropriato fattore di rotazione, evidenziando la sottile interazione tra porte quantistiche, formule di codifica e impostazioni degli iperparametri.
Cosa significa per il futuro
Per un non specialista, il messaggio principale è che il vantaggio quantistico nel machine learning non arriverà “gratis” semplicemente eseguendo modelli standard su hardware quantistico. Il successo dipende invece dal progettare il modo giusto di fornire dati ai circuiti quantistici e dal sintonizzare pochi parametri critici in modo che gli stati quantistici catturino la struttura del problema. Questo articolo fornisce una roadmap per fare esattamente questo con i metodi a kernel quantistici, mostrando che mappe di feature quantistiche progettate e ottimizzate con cura possono offrire prestazioni solide, talvolta superiori, anche con circuiti molto piccoli. Allo stesso tempo, gli autori notano che i loro risultati si basano su simulazioni senza rumore hardware e su dataset relativamente modesti, quindi realizzare pienamente questi guadagni su macchine quantistiche reali e su scala maggiore resta una sfida vitale per lavori futuri.
Citazione: Jha, R.K., Kasabov, N., Bhattacharyya, S. et al. Comparative performance analysis of quantum feature maps for quantum kernel-based machine learning. Sci Rep 16, 8142 (2026). https://doi.org/10.1038/s41598-026-39392-9
Parole chiave: apprendimento automatico quantistico, kernel quantistici, mappe di feature, ottimizzazione degli iperparametri, classificazione