Clear Sky Science · it
CGDFNet: una rete di segmentazione semantica in tempo reale a doppio ramo con fusione dei dettagli guidata dal contesto
Insegnare alle auto a vedere l'intera strada
Auto e robot moderni si affidano sempre più alle telecamere per comprendere l'ambiente che li circonda: individuare in tempo reale strade, marciapiedi, persone, veicoli e segnali. Questo articolo presenta CGDFNet, un nuovo sistema di visione artificiale progettato per svolgere questo tipo di «comprensione della scena» più rapidamente e con maggiore accuratezza, in particolare nelle affollate strade cittadine. Imparando a mantenere contemporaneamente sia i dettagli fini (come i pali dei semafori o le ruote di una bicicletta) sia la disposizione globale (come strade e edifici), CGDFNet mira a rendere la guida automatizzata e altri compiti di visione in tempo reale più sicuri e affidabili.
Perché la visione a livello di pixel è così impegnativa
Nella segmentazione semantica, un sistema assegna una categoria a ciascun singolo pixel di un'immagine: strada, auto, pedone, cielo e così via. Questo è molto più impegnativo che tracciare semplicemente una scatola attorno a un veicolo, perché il sistema deve delineare con precisione i contorni degli oggetti e le forme minute. Esistono molti metodi ad alta precisione, ma tendono a essere lenti e dispendiosi in termini di energia, il che li rende poco adatti per sistemi in tempo reale su auto, droni o dispositivi indossabili. D'altra parte, i metodi leggeri che funzionano rapidamente spesso sacrificano i dettagli o perdono la visione d'insieme, faticando con oggetti piccoli, strutture sottili o ambienti urbani affollati.
Due percorsi: uno per i dettagli, uno per il contesto
CGDFNet affronta questa tensione con un design a doppio ramo: un ramo si concentra sui dettagli netti, mentre l'altro cattura il contesto ampio. Partendo da una backbone efficiente, gli strati inferiori alimentano un «ramo dei dettagli» che mantiene risoluzioni più alte per preservare bordi e texture. Gli strati più profondi alimentano un «ramo del contesto» che osserva la scena in una forma più compressa, utile per comprendere la struttura complessiva e le relazioni tra gli oggetti. Diversamente dai precedenti design a due rami che in gran parte mantengono questi flussi separati e poi li sommano in modo approssimativo, CGDFNet li incoraggia a comunicare tra loro durante l'elaborazione, in modo che i dettagli fini siano costantemente verificati rispetto a ciò che la rete sa della scena nel suo insieme.
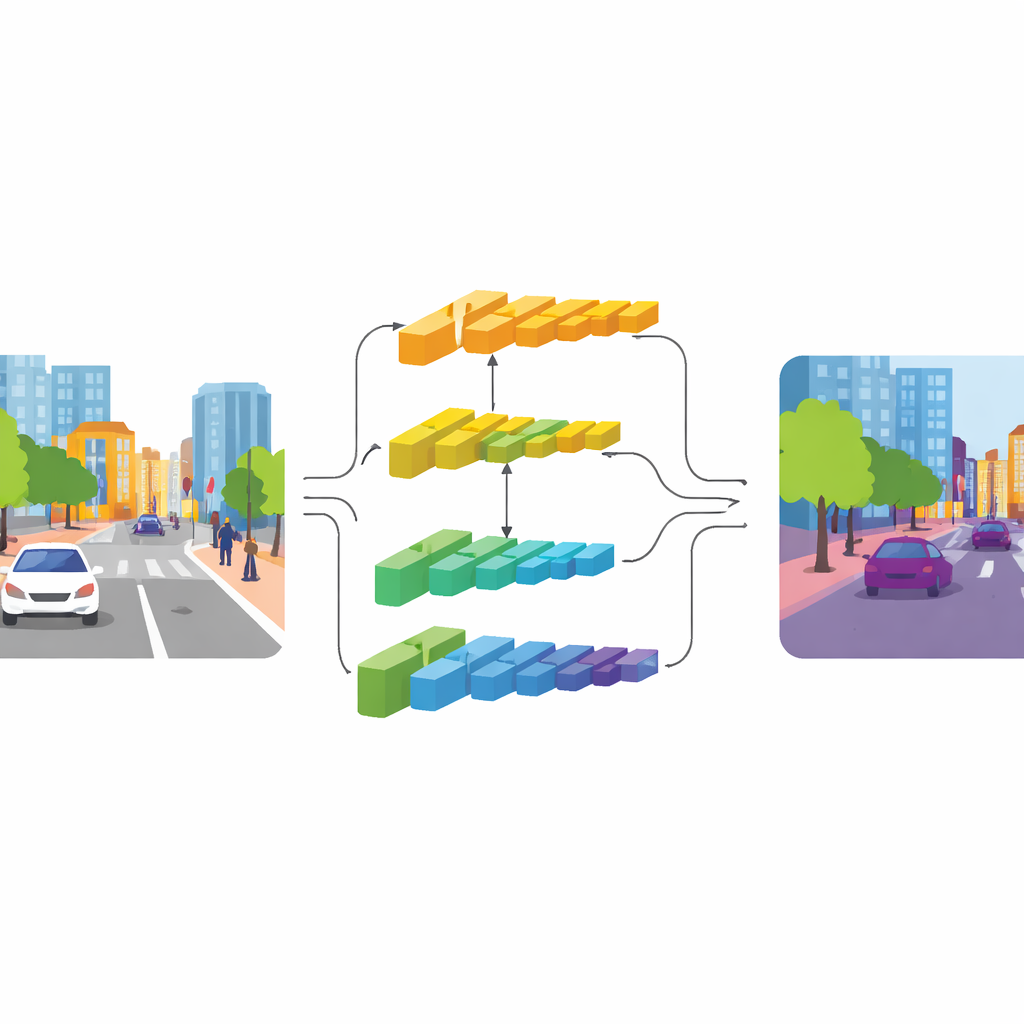
Guidare i dettagli con il significato
Due componenti chiave rafforzano questa interazione. Nel ramo del contesto, un Modulo di Refinimento Semantico impara a mettere in evidenza le regioni e i canali più informativi nelle sue mappe di caratteristiche. Lo fa combinando indizi locali (quali parti della scena sono attive tra loro) con indizi globali (cosa vede la rete sull'intera immagine), in modo che la rappresentazione contenga sia dettaglio di vicinato sia significato a livello di scena. Nel ramo dei dettagli, un Modulo di Dettaglio Guidato dal Contesto usa queste informazioni semantiche per orientare l'attenzione verso bordi e strutture sottili rilevanti, come il profilo di un autobus o la cornice di una bicicletta. Si basa su una particolare modalità di convoluzione più sensibile alle variazioni tra pixel adiacenti, che enfatizza naturalmente i contorni e gli oggetti piccoli senza aggiungere molti parametri extra.
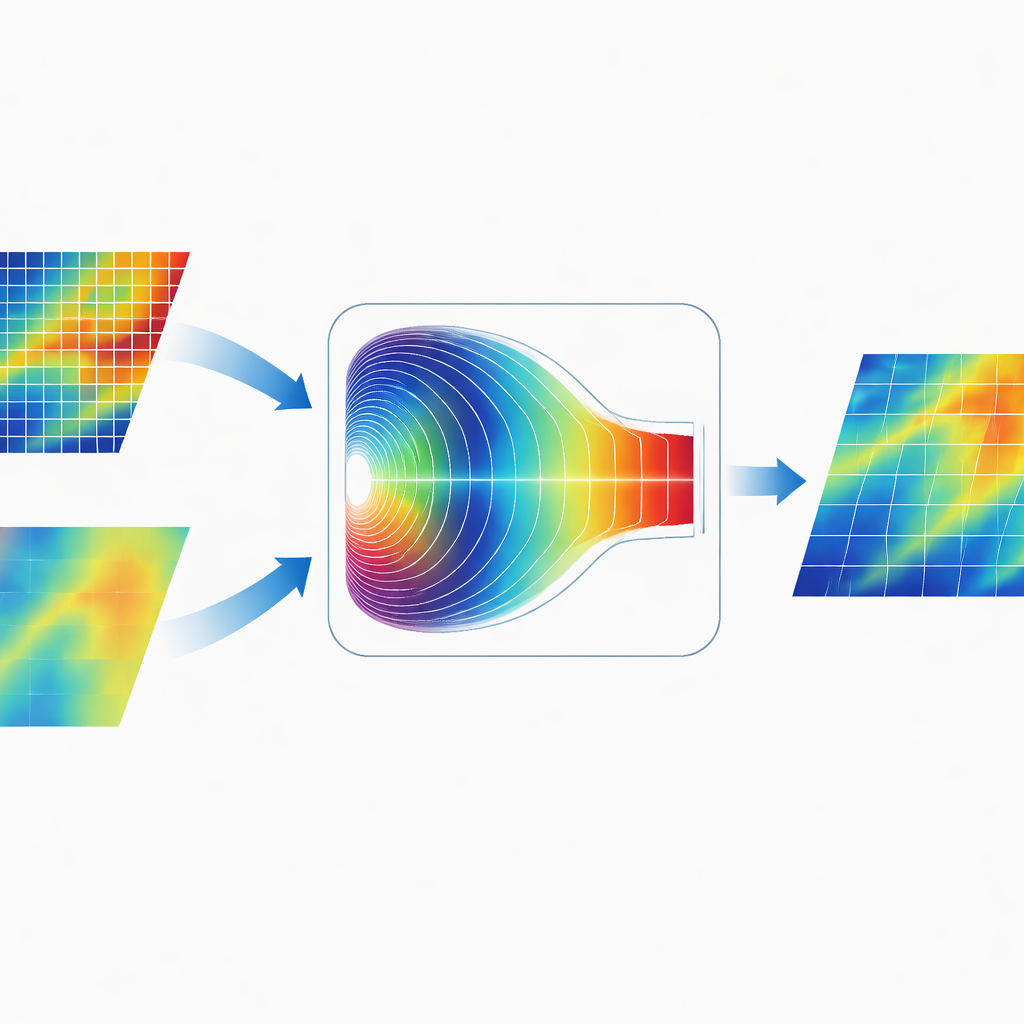
Fondere le informazioni nel dominio delle frequenze
Una caratteristica distintiva di CGDFNet è il modo in cui unisce i due rami. Piuttosto che sommare semplicemente le loro mappe nello spazio dell'immagine, gli autori progettano un Modulo di Fusione Adattiva nel Dominio di Fourier. Questo modulo trasforma temporaneamente le caratteristiche combinate nel dominio delle frequenze, dove i pattern sono rappresentati in termini di variazioni lente e ampie e cambiamenti rapidi e netti. Un meccanismo di gating adattivo impara quindi quali componenti di frequenza enfatizzare dal ramo dei dettagli e quali enfatizzare dal ramo del contesto. Dopo questo ponderamento, le caratteristiche vengono trasformate di nuovo nello spazio originale, producendo una rappresentazione che unisce in modo più efficace bordi netti e struttura globale coerente rispetto alle tradizionali fusioni spaziali.
Risultati sulle strade reali
Il team ha testato CGDFNet su due benchmark ampiamente usati per scene di guida urbana: Cityscapes, raccolto in città europee, e CamVid, acquisito dal punto di vista del guidatore nel Regno Unito. CGDFNet ha elaborato immagini di grandi dimensioni a velocità in tempo reale—circa 88 fotogrammi al secondo su Cityscapes e circa 129 fotogrammi al secondo su CamVid—raggiungendo al contempo una precisione di segmentazione che competono o superano molti sistemi all'avanguardia. Ha ottenuto prestazioni particolarmente buone su categorie che solitamente sono difficili da segmentare, come recinzioni, segnali stradali, autobus e biciclette, dove preservare contorni precisi e strutture piccole è cruciale.
Cosa significa per la tecnologia di tutti i giorni
In termini pratici, CGDFNet dimostra che è possibile costruire sistemi di visione abbastanza veloci per l'uso in tempo reale e al tempo stesso accurati nel rispettare dettagli piccoli e critici per la sicurezza in scene urbane complesse. Combinando un ramo focalizzato sui dettagli, un ramo focalizzato sul contesto e un passaggio di fusione intelligente nel dominio delle frequenze, la rete mantiene una visione bilanciata della strada: sa dove è ogni cosa e dove comincia e finisce ogni oggetto. Pur restando delle sfide—come folle densamente addensate o condizioni meteorologiche avverse—l'approccio offre un modello promettente per la visione on‑device futura, dalle auto a guida autonoma alle telecamere intelligenti del traffico e ai robot assistivi.
Citazione: Zhao, S., Fu, W., Gao, J. et al. CGDFNet: a dual-branch real-time semantic segmentation network with context-guided detail fusion. Sci Rep 16, 9191 (2026). https://doi.org/10.1038/s41598-026-39370-1
Parole chiave: segmentazione semantica in tempo reale, visione per guida autonoma, rete neurale a doppio ramo, fusione delle caratteristiche basata su Fourier, comprensione di scene urbane