Clear Sky Science · it
Una rete neurale convoluzionale end-to-end per la trasmissione sicura di immagini tramite cifratura congiunta e steganografia
Perché nascondere immagini dentro altre immagini conta
Ogni giorno ospedali, banche e privati inviano un grande numero di foto su Internet — dalle scansioni mediche alle carte d’identità fino agli scatti di famiglia. Mantenere private queste immagini di solito significa cifrarle, il che le fa apparire come rumore casuale, oppure nasconderle all’interno di altre immagini, un trucco chiamato steganografia. Ciascun approccio ha una debolezza: le immagini cifrate attirano attenzione, mentre quelle nascoste possono essere rivelate da analisi sofisticate. Questo articolo presenta un nuovo sistema di deep learning che fonde entrambe le idee, con l’obiettivo di inviare immagini segrete in modo che appaiano naturali all’occhio umano ma restino difficili da decifrare per un attaccante.
Il problema dei metodi di protezione attuali
Gli strumenti di cifratura tradizionali come AES e DES sono matematicamente robusti, ma trasformano una foto in un blocco di rumore visivo che segnala chiaramente “qui c’è qualcosa di importante”. La steganografia classica fa l’opposto: nasconde informazioni nei dettagli fini di un’immagine dall’aspetto normale, spesso però senza una forte protezione crittografica. Se un attaccante individua il trucco, il messaggio nascosto può essere facilmente estratto. Metodi recenti basati sul deep learning hanno migliorato sia la cifratura sia l’occultamento, ma la maggior parte li tratta come due fasi separate. Questa separazione spreca risorse di calcolo e può permettere che errori in una fase compromettano l’altra. Gli autori sostengono che manca un sistema unico che impari, end-to-end, a mascherare e proteggere le immagini contemporaneamente.
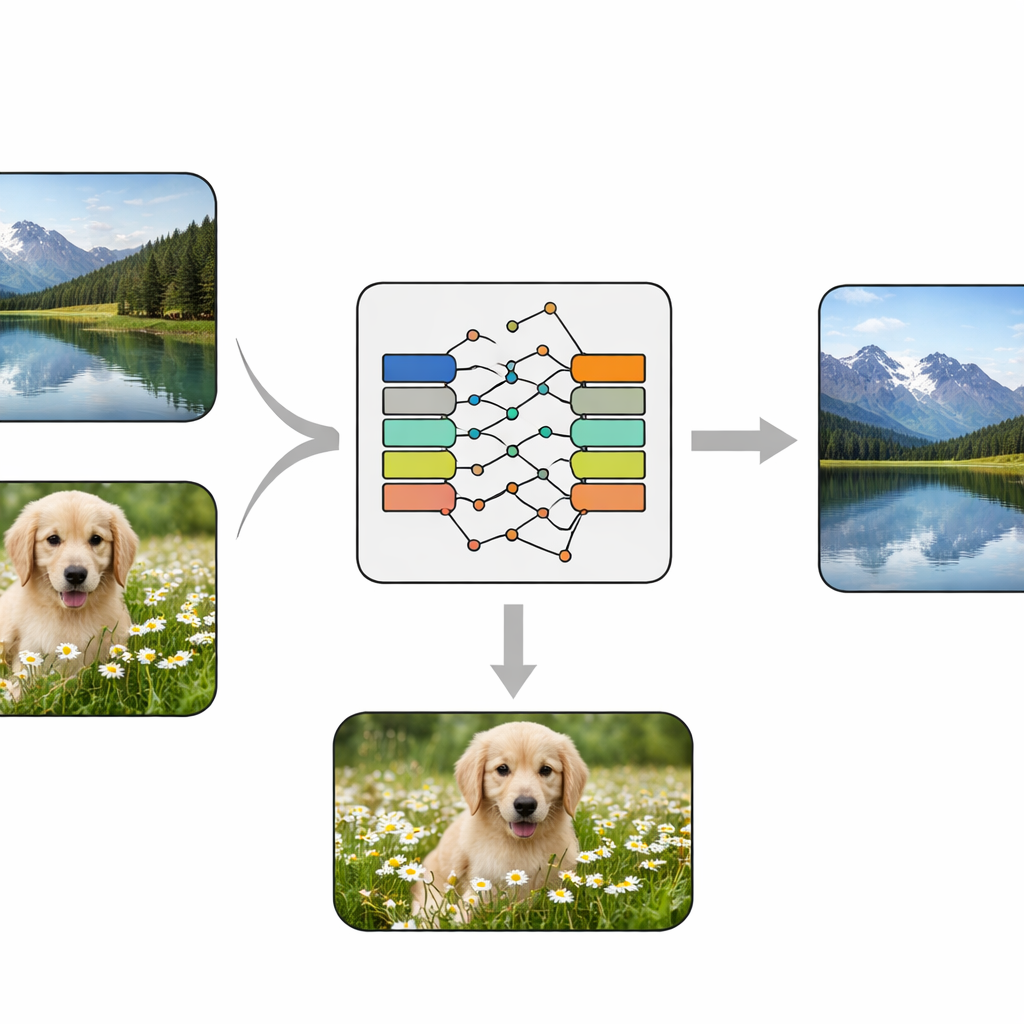
Un unico cervello che miscela e nasconde
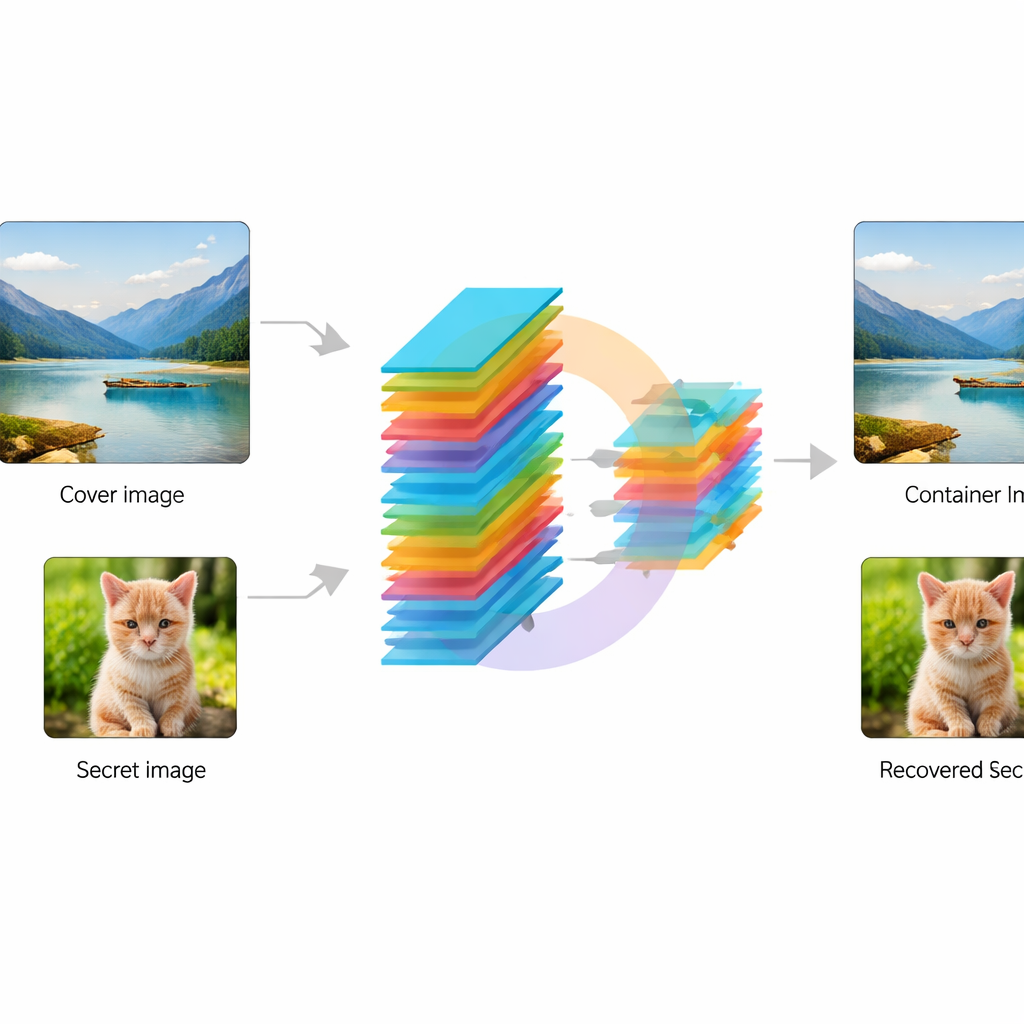
I ricercatori progettano una rete neurale convoluzionale end-to-end — essenzialmente una pipeline di elaborazione delle immagini addestrabile — che prende in input due immagini: una foto “cover” normale e una foto “segreta” da proteggere. Innanzitutto, un modulo speciale chiamato KeyMixer trasforma l’immagine segreta usando chiavi numeriche addestrabili. Diversamente dai cifrari fissi progettati a mano, questo mixer apprende variazioni dipendenti dal contenuto, che tengono conto di texture e forme nell’immagine, introducendo distorsioni sottili e non ovvie. Successivamente, una rete Encoder fonde in modo morbido questo segreto trasformato nella cover, creando un’immagine “container” che dovrebbe ancora apparire naturale. Lato ricevitore, una rete Decoder corrispondente prende solo il container e ricostruisce il segreto nascosto, senza bisogno di chiavi extra o informazioni di contorno durante il recupero.
Insegnare alla rete a bilanciare segretezza e aspetto
Addestrare questo sistema significa chiedergli di raggiungere due obiettivi contemporaneamente: mantenere il container visivamente vicino alla cover originale e recuperare l’immagine segreta nel modo più accurato possibile. Gli autori fanno ciò con una strategia a doppia perdita che penalizza sia le modifiche visibili alla cover sia gli errori nella ricostruzione del segreto. Utilizzano un noto insieme di riferimento di foto naturali, il dataset STL-10, e applicano tecniche standard di data augmentation come ribaltamenti e piccole rotazioni in modo che la rete veda scene variate. Durante l’addestramento il modello migliora progressivamente fino a quando entrambi gli obiettivi si stabilizzano, dimostrando di poter trovare un compromesso praticabile tra invisibilità e recupero fedele.
Quanto sopravvivono le immagini nascoste
Per valutare la qualità, il team misura quanto i container sono simili alle cover e quanto i segreti recuperati corrispondono agli originali, usando metriche standard di qualità dell’immagine. Sui test il metodo raggiunge un’alta somiglianza strutturale sia per la cover sia per il segreto, con valori superiori a 0,90, il che significa che forme e dettagli sono in gran parte preservati. Le immagini segrete in particolare ottengono similitudini molto elevate, indicando un recupero percettivo quasi perfetto. Rispetto a diversi moderni sistemi di steganografia basati su deep learning e pipeline ibride, il nuovo modello end-to-end offre la migliore ricostruzione dell’immagine segreta, anche se alcuni rivali preservano leggermente meglio la cover. Test statistici sulle distribuzioni dei pixel, sulla casualità e sulla sensibilità alle modifiche suggeriscono che i container non rivelano indizi evidenti dell’esistenza di un contenuto nascosto.
Cosa potrebbe significare per la privacy quotidiana
In termini concreti, questo lavoro mostra che un unico modello di deep learning può imparare a mascherare e proteggere immagini in modo che un’immagine nascosta possa essere recuperata con alta chiarezza, mentre l’immagine condivisa continua ad apparire ordinaria. Piuttosto che collegare cifratura e steganografia in una catena goffa, il sistema apprende un compromesso fluido tra sottigliezza visiva e sicurezza. Sebbene al momento richieda hardware potente e ulteriori test contro attacchi avanzati, l’approccio indica la strada verso strumenti futuri che potrebbero proteggere discretamente scansioni mediche, foto personali o altre immagini sensibili nella comunicazione online di routine senza dichiarare che è presente qualcosa di segreto.
Citazione: Iqbal, A., Sattar, H., Shafi, U.F. et al. An end-to-end convolutional neural network for secure image transmission via joint encryption and steganography. Sci Rep 16, 8228 (2026). https://doi.org/10.1038/s41598-026-39351-4
Parole chiave: sicurezza delle immagini, steganografia, apprendimento profondo, cifratura neurale, protezione della privacy