Clear Sky Science · it
Predizione mascherata della topologia del movimento dello scheletro e apprendimento contrastivo per il riconoscimento auto-supervisionato delle azioni umane
Insegnare ai computer a leggere il linguaggio del corpo
Dai campanelli video agli strumenti di riabilitazione intelligenti, molti sistemi moderni devono capire cosa stanno facendo le persone osservando soltanto come si muovono. Ma addestrare i computer a riconoscere le azioni umane di solito richiede grandi dataset etichettati con cura, in cui ogni saluto, calcio o stretta di mano è annotato manualmente. Questo studio introduce un modo per far apprendere alle macchine a partire solo dai dati grezzi del movimento, usando esclusivamente lo scheletro in movimento del corpo—nessuna etichetta, nessun volto e nessun video a colori—rendendo il riconoscimento delle azioni più accurato, più rispettoso della privacy e molto meno dipendente da costose annotazioni umane.
Perché gli scheletri bastano
Invece di analizzare interi fotogrammi video, il metodo lavora con dati scheletrici 3D: le coordinate delle articolazioni chiave come spalle, gomiti, anche e ginocchia nel tempo. Questa visione essenziale del corpo presenta diversi vantaggi. Evita in larga misura problemi di privacy perché volti e abbigliamento vengono rimossi, ed è sufficientemente compatta da poter essere elaborata in modo efficiente anche per registrazioni lunghe. Gli scheletri sono inoltre robusti a sfondi rumorosi e cambiamenti di illuminazione che possono confondere i sistemi basati su video tradizionali. Tuttavia, la maggior parte degli approcci basati su scheletri si affida ancora pesantemente a esempi etichettati e fatica a catturare appieno come le articolazioni si muovono insieme in azioni complesse e coordinate.
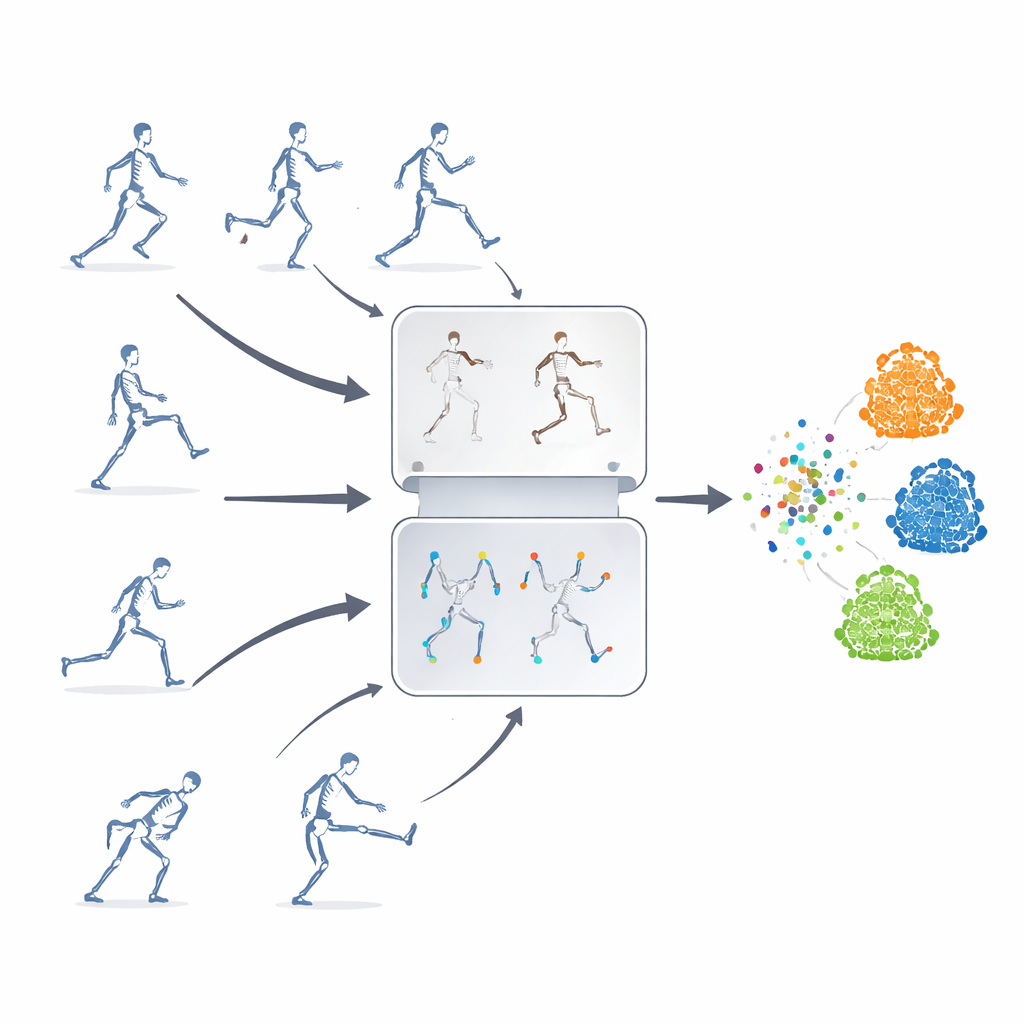
Apprendere senza etichette
Gli autori propongono un framework di apprendimento auto-supervisionato, cioè un sistema che si insegna da sé a partire da sequenze scheletriche non etichettate. L’idea chiave è combinare due strategie potenti che di solito sono impiegate separatamente. Una è la «predizione mascherata», in cui parti dei dati scheletrici vengono deliberateamente nascoste affinché il modello debba indovinarne il movimento mancante a partire dal contesto rimanente. L’altra è l’«apprendimento contrastivo», che mostra al modello più versioni alterate della stessa azione e lo addestra a riconoscere che queste variazioni rappresentano comunque un unico movimento sottostante. Fondendo questi approcci, il sistema apprende sia i dettagli fini del moto delle articolazioni sia il significato d’insieme di un’azione.
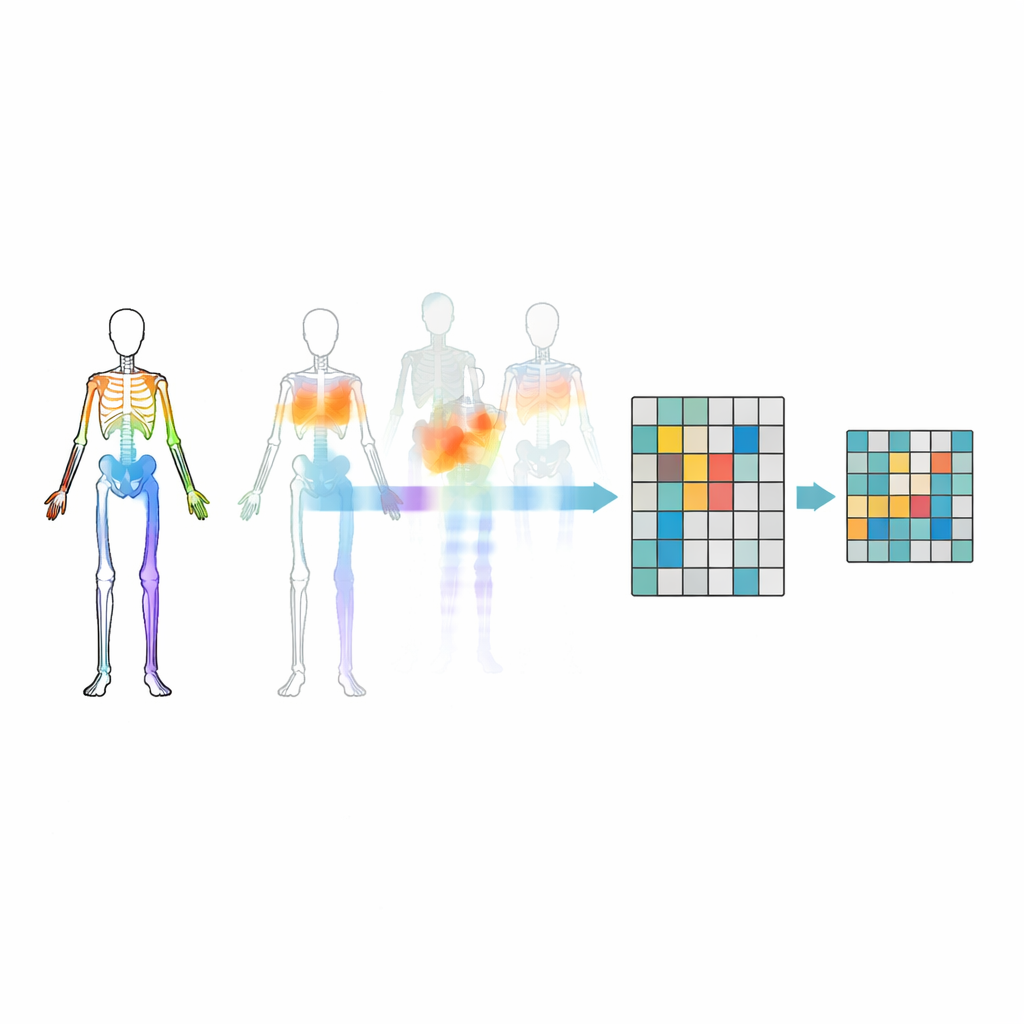
Nascondere le articolazioni giuste
Mascherare semplicemente articolazioni a caso non è sufficiente—il modello potrebbe ignorare relazioni importanti tra le parti del corpo o fissarsi sul movimento più ovvio. Per evitare ciò, i ricercatori introducono una strategia di mascheramento basata su movimento e topologia. Raggruppano le articolazioni in regioni corporee significative come braccia, gambe e tronco, quindi misurano quanto ciascuna regione si muove nel tempo. Le decisioni di mascheramento sono guidate sia dalla struttura del corpo sia dall’intensità del movimento di ciascuna regione, così che talvolta parti molto attive vengono nascoste e il modello è costretto a inferirle dal resto del corpo. Questo nascondimento mirato aiuta il sistema a imparare come le articolazioni collaborano durante le azioni, invece di limitarsi a memorizzare pochi movimenti appariscenti.
Allungare le azioni in tanti modi
Per addestrare la componente contrastiva del sistema, la stessa sequenza scheletrica originale viene trasformata in molteplici «viste». Alcune modifiche sono lievi, come ritagliare la finestra temporale o deformare leggermente la traiettoria, mentre altre sono più estreme, incluse inversioni, rotazioni e rumore più intenso. Questi molteplici livelli di augmentazione espongono il modello a una ricca varietà di pattern di movimento, incoraggiandolo a concentrarsi sulla struttura portante di un’azione piuttosto che su dettagli superficiali. Allo stesso tempo, un modulo di eliminazione delle caratteristiche guidato dalla traiettoria tiene traccia delle caratteristiche di movimento su cui il modello si basa maggiormente e le sopprime intenzionalmente durante l’addestramento. Rimuovendo temporaneamente i suoi indizi preferiti, il sistema viene spinto a scoprire segnali di riserva e a imparare rappresentazioni più generali e trasferibili.
Quanto funziona bene?
Il framework è testato su tre grandi benchmark pubblici di azioni umane 3D, che coprono comportamenti quotidiani, movimenti legati a contesti medici e interazioni tra persone. Pur utilizzando soltanto dati delle articolazioni scheletriche e una rete neurale ricorrente relativamente leggera, il metodo eguaglia o supera molti sistemi all’avanguardia che si basano su input o architetture più complesse. Risulta particolarmente efficace quando le annotazioni sono scarse o quando alcune parti del corpo sono occluse, condizioni che si presentano comunemente in ambienti reali. Sebbene la sua capacità di trasferire conoscenza tra dataset molto diversi lasci ancora spazio a miglioramenti, l’approccio riduce in modo significativo il divario tra addestramento etichettato e non etichettato per il riconoscimento delle azioni.
Cosa significa per i sistemi nel mondo reale
Per un non specialista, il punto principale è che questo lavoro dimostra come i computer possano diventare molto più bravi a leggere il linguaggio del corpo umano senza che venga detto esplicitamente cosa significa ogni movimento. Nascondendo e distorcendo in modo intelligente i dati scheletrici durante l’addestramento, il modello impara pattern di movimento robusti che resistono a scarsa illuminazione, a clutter visivo o a articolazioni mancanti, utilizzando molte meno etichette fornite dall’uomo. Ciò apre la strada a sistemi di riconoscimento delle azioni più rispettosi della privacy, scalabili e adattabili per applicazioni che vanno dal monitoraggio domestico e dall’allenamento sportivo alla riabilitazione medica e all’interazione uomo-robot.
Citazione: Hui, Y., Li, F., Hu, X. et al. Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition. Sci Rep 16, 8100 (2026). https://doi.org/10.1038/s41598-026-39330-9
Parole chiave: riconoscimento delle azioni umane, dati scheletrici 3D, apprendimento auto-supervisionato, apprendimento contrastivo, analisi del movimento