Clear Sky Science · it
Un framework Siamese CNN-RNN con aggregazione multi-livello per il re-identification di persone basato su video
Perché seguire le persone attraverso le telecamere è importante
Le città moderne sono coperte da telecamere, ma questi dispositivi raramente “dialogano” tra loro. Quando una persona passa da un angolo di strada a una stazione, viene ripresa da telecamere diverse con angolazioni, illuminazione e spesso attraverso la folla differenti. Riconoscere automaticamente che si tratta della stessa persona in clip video diverse — chiamato re-identification di persone basato su video — può aiutare gli investigatori a tracciare spostamenti dopo un incidente, supportare ricerche di persone scomparse o alimentare analisi in spazi pubblici affollati. Farlo in modo accurato ed efficiente, specialmente su hardware modesto, rappresenta però una sfida tecnica rilevante.
Un cervello più semplice per confrontare persone in movimento
Questo studio presenta un sistema di intelligenza artificiale compatto pensato per stabilire se due clip video brevi mostrano la stessa persona. Invece di seguire l’attuale tendenza delle reti molto profonde o basate su transformer, gli autori partono da un progetto più snello che combina due ingredienti classici: una rete convoluzionale che analizza ogni singolo fotogramma e una gated recurrent unit (GRU) che segue come l’aspetto cambia nel tempo. Questi due rami sono disposti in una struttura siamese — essenzialmente due copie della stessa rete che condividono tutti i parametri interni. Ogni gemella elabora una sequenza video e il sistema impara a produrre firme interne simili per clip della stessa persona e distintamente diverse per persone differenti.
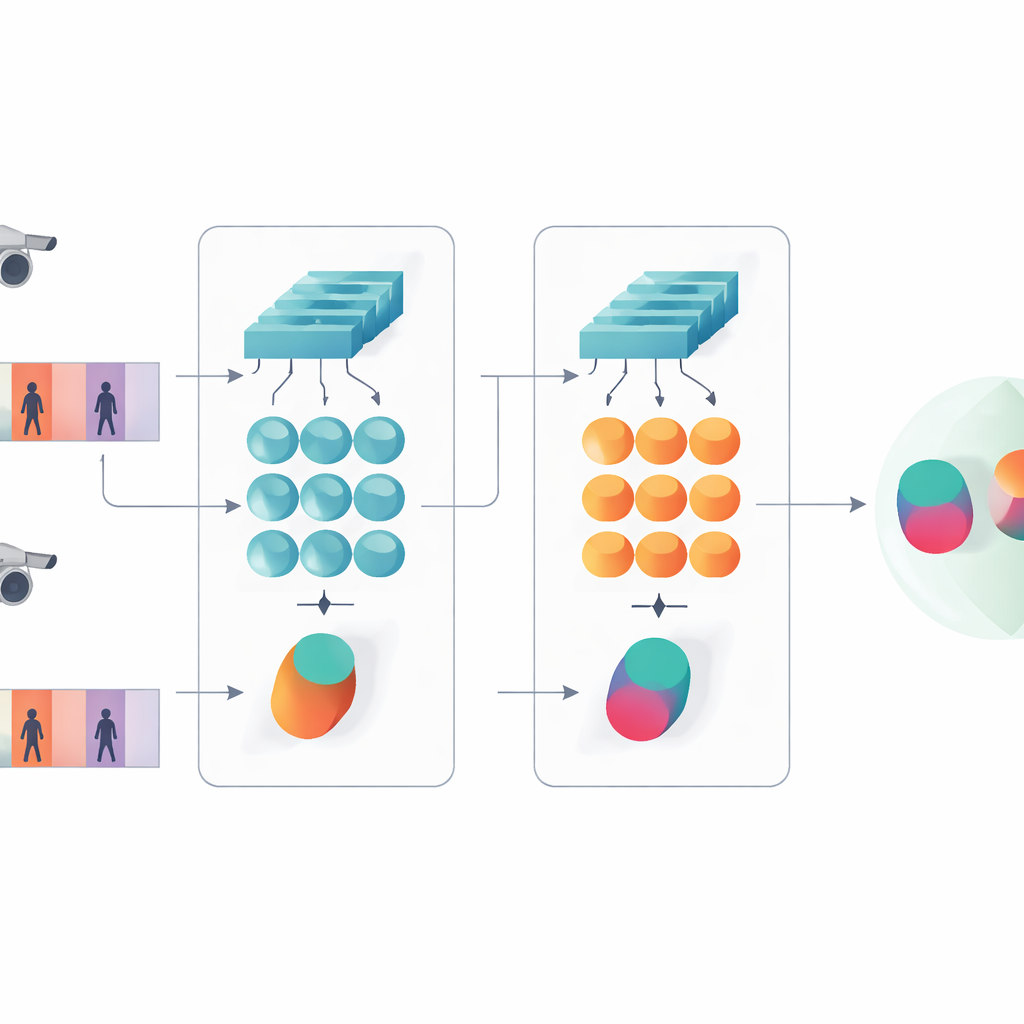
Cogliere sia i dettagli sia i pattern nel tempo
Un’idea chiave del lavoro è che il riconoscimento non dovrebbe basarsi solo sulle caratteristiche più profonde e astratte di una rete. I livelli precedenti contengono ancora dettagli visivi nitidi come la trama di una giacca, le righe di un pantalone o il profilo di uno zaino — indizi che spesso resistono alle variazioni di angolazione della telecamera. Il modello proposto quindi mantiene due livelli di descrizione. Un ramo aggrega (pooling) le caratteristiche degli strati iniziali su tutti i fotogrammi per sintetizzare texture fini e pattern locali. L’altro ramo alimenta caratteristiche più avanzate nella GRU, che segue la sequenza fotogramma dopo fotogramma e poi media i suoi stati interni nel tempo. Questo passaggio di media evita di sovrappesare gli ultimi fotogrammi e cattura invece una visione di consenso di come la persona appare e si muove lungo l’intera clip.
Addestrare le reti gemelle a concordare e a classificare
Per insegnare al sistema cosa è rilevante, gli autori combinano due obiettivi di training. Primo, un obiettivo di verifica incoraggia i rami gemelli a produrre firme vicine per video della stessa persona e lontane per persone diverse. Secondo, un obiettivo di classificazione richiede alla rete di assegnare ogni clip di addestramento a una specifica identità. Ottimizzando entrambi simultaneamente, e applicandoli sia ai livelli bassi sia a quelli alti delle feature, il modello impara descrizioni interne che non sono solo distintive tra persone ma anche robuste al rumore, alle occlusioni e a fotogrammi occasionalmente di scarsa qualità. Il progetto rimane poco profondo in termini di strati e parametri, il che aiuta a evitare l’overfitting su dataset video relativamente piccoli.
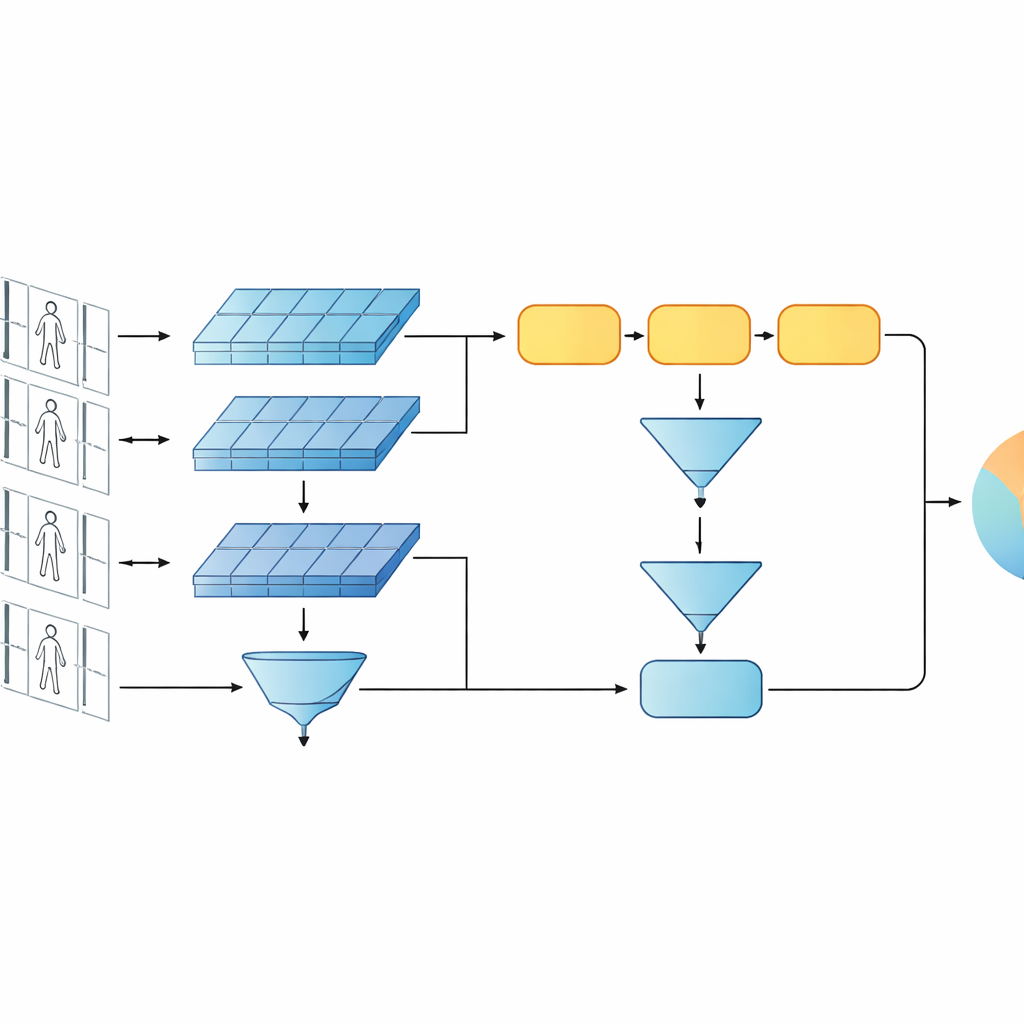
Test su video in stile sorveglianza reale
Il framework è valutato su due benchmark video largamente utilizzati, PRID-2011 e iLIDS-VID, che contengono brevi sequenze di camminata di centinaia di individui catturate da coppie di telecamere disgiunte. Lo studio esamina con cura diverse scelte progettuali: sostituire la GRU con altre unità ricorrenti, variare il numero di layer ricorrenti, modificare come le feature vengono aggregate nel tempo e attivare o disattivare i rami a basso o ad alto livello. In questi test, una GRU a singolo strato con pooling medio e la configurazione multi-livello completa offre costantemente le migliori prestazioni. Il modello eguaglia o supera molti sistemi ricorrenti e siamese più complessi, e risulta competitivo rispetto ad alcuni progetti basati sull’attenzione, pur utilizzando molti meno parametri e risorse computazionali.
Efficienza per implementazioni nel mondo reale
Oltre all’accuratezza, il lavoro pone l’accento sulla praticità. L’intera rete ha solo circa uno-due milioni di parametri addestrabili — ordini di grandezza in meno rispetto ai popolari backbone deep residual o basati su transformer — e richiede una frazione del loro costo computazionale per fotogramma. Questo la rende più adatta all’implementazione su dispositivi con memoria e potenza di calcolo limitate, come server edge vicini alle telecamere. Gli esperimenti mostrano inoltre che sequenze di gallery più lunghe, nelle quali il sistema vede più fotogrammi di ogni persona memorizzata, migliorano sostanzialmente il riconoscimento, sebbene con un aumento lineare del costo di elaborazione. Gli autori sostengono che architetture compatte e progettate con cura possano offrire una re-identification affidabile senza il costo elevato dei modelli più grandi di oggi.
Cosa significa questo per i sistemi di sorveglianza quotidiani
In termini semplici, questo articolo dimostra che il design intelligente può superare la pura dimensione: combinando analisi delle immagini poco profonda, modellazione leggera delle sequenze e una visione a due livelli della similarità visiva, è possibile tracciare chi è chi attraverso le telecamere con elevata affidabilità mantenendo il modello piccolo e veloce. Per i sistemi futuri che devono operare su molte telecamere, spesso con vincoli stretti di hardware ed energia, questo approccio efficiente e multi-livello potrebbe aiutare a portare analisi video più capaci e responsabili nell’uso reale.
Citazione: Wang, YK., Pan, TM. & Sun, CP. A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification. Sci Rep 16, 8224 (2026). https://doi.org/10.1038/s41598-026-39277-x
Parole chiave: re-identificazione di persone, videosorveglianza, reti neurali siamese, modellazione temporale, deep learning efficiente