Clear Sky Science · it
Un solido framework di generazione text-to-SQL da linguaggio naturale con strategie dinamiche basate su LLM
Trasformare le domande di ogni giorno in risposte dal database
Le organizzazioni moderne sono sommerse di dati, ma la maggior parte delle persone non conosce il linguaggio tecnico necessario per interrogarli. Questo articolo presenta TriSQL, un sistema che permette agli utenti di porre domande in linguaggio naturale e le converte automaticamente in comandi database precisi. Gestendo con attenzione come i large language model affrontano la complessità, il framework mira a rendere l’accesso ai dati più accurato e affidabile, anche per le domande più difficili.
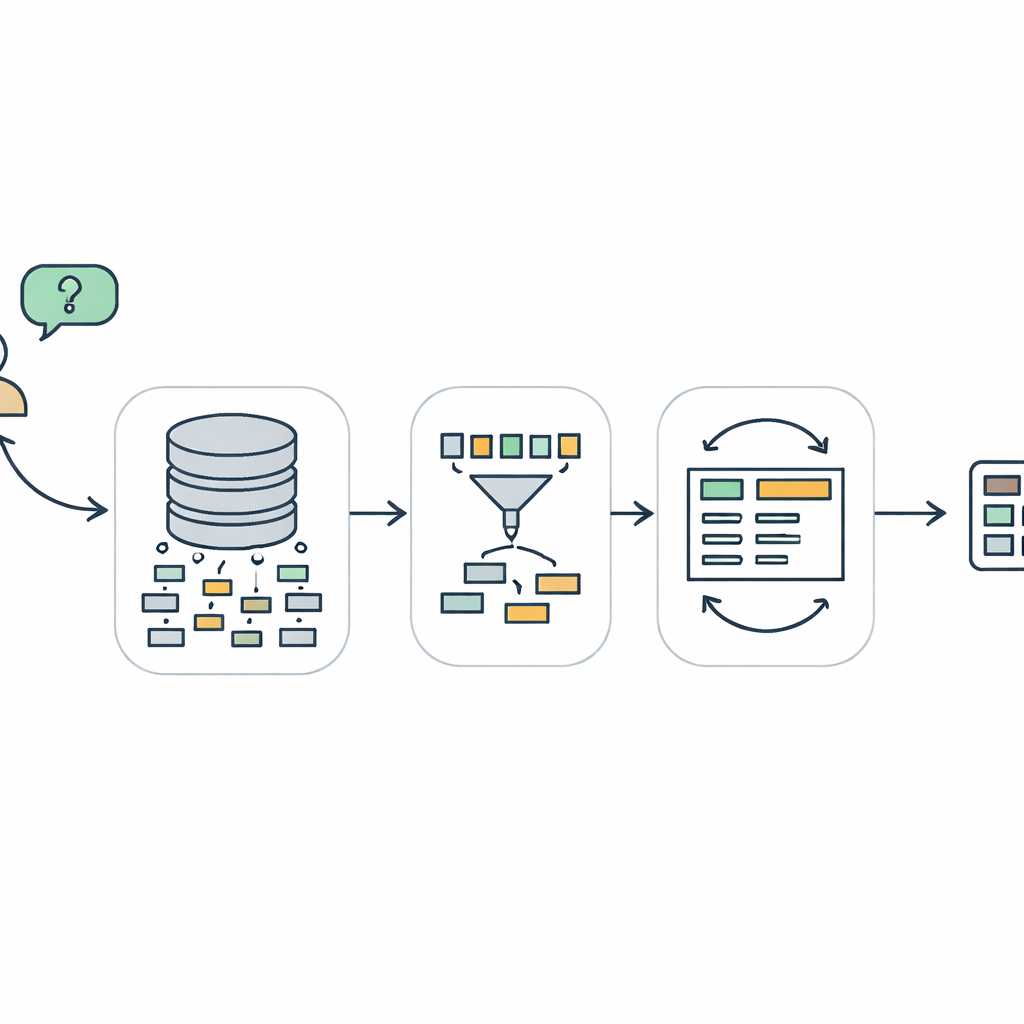
Perché parlare con i database è così difficile
Quando qualcuno digita una domanda come “Quali clienti hanno acquistato più di cinque prodotti il mese scorso?” un computer deve tradurla in SQL, il linguaggio specializzato usato dalla maggior parte dei database. Questo compito, chiamato text-to-SQL, sembra semplice ma è sorprendentemente complesso. Il sistema deve comprendere cosa vuole l’utente, individuare le tabelle e le colonne giuste all’interno di un database talvolta enorme e disordinato, e poi costruire una query che sia sia sintatticamente valida sia fedele all’intento originale. I sistemi precedenti, compresi quelli basati su large language model, spesso falliscono quando le domande coinvolgono molte tabelle, logiche annidate o condizioni sottili. Possono generare query che sembrano corrette ma che non vengono eseguite o restituiscono risultati sbagliati una volta eseguite.
Un percorso in tre fasi dalla domanda alla query
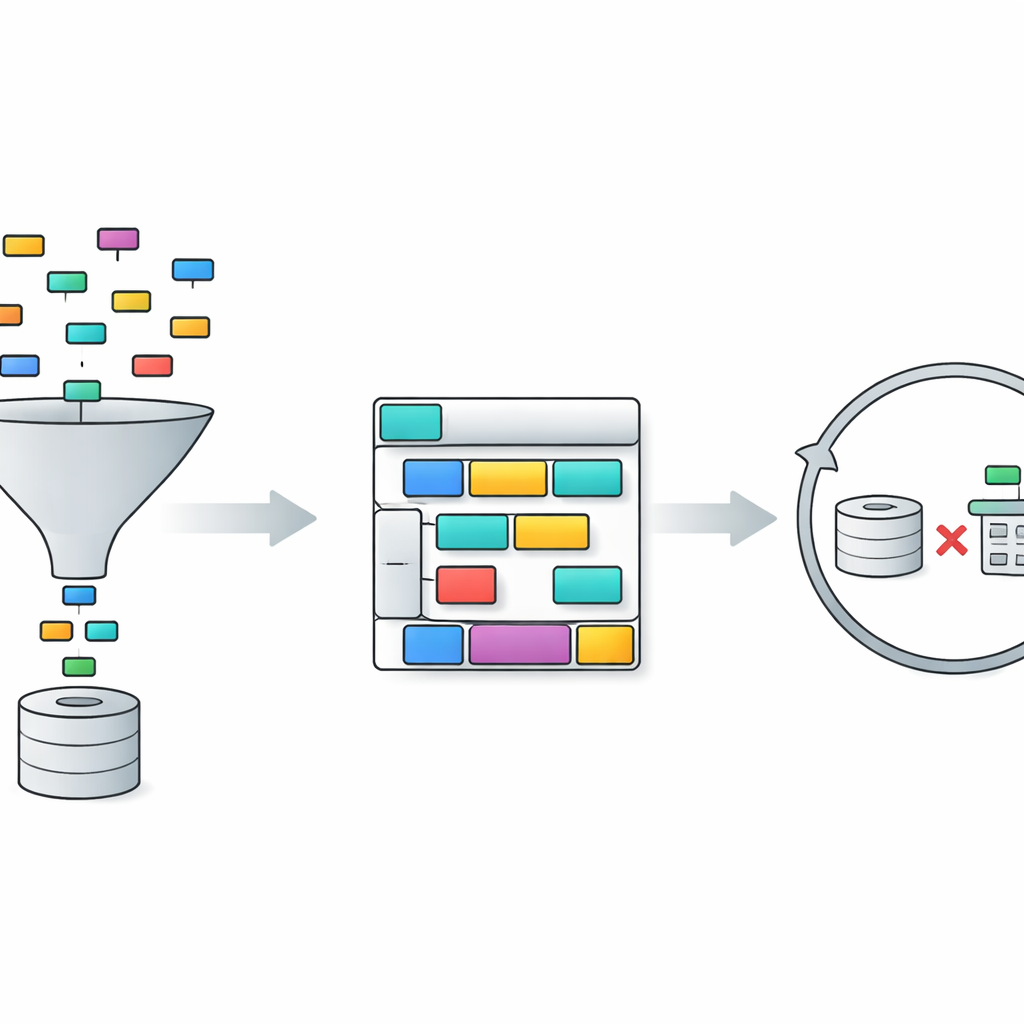
TriSQL affronta questi problemi con una pipeline in tre stadi. Innanzitutto, un selettore guidato dalla domanda esamina le parole dell’utente e l’intera struttura del database e decide quali tabelle e colonne sono effettivamente rilevanti. Invece di esporre ciecamente al modello linguistico l’intero schema, restringe la vista alle sole parti che contano. In secondo luogo, un generatore consapevole della struttura pianifica la forma della query SQL prima di riempirne i dettagli. Disegna prima uno scheletro ad alto livello—quali clausole sono necessarie e come si integrano—e poi inserisce tabelle specifiche, join e condizioni. Questo approccio “prima la struttura, poi il contenuto” aiuta a preservare la rigida grammatica di SQL, specialmente per query lunghe e intricate. Infine, un raffinatore consapevole della complessità controlla e migliora la query iniziale, usando strategie diverse a seconda della difficoltà apparente della domanda.
Adattare lo sforzo alla difficoltà della domanda
La fase di raffinamento è in cui TriSQL sfrutta in modo particolarmente innovativo i large language model. Il sistema valuta quanto è complessa ogni domanda e bozza di query, considerando fattori come il numero di tabelle unite, la profondità di eventuali annidamenti e il tipo di vincoli utilizzati. Per i casi semplici applica solo correzioni leggere, come sistemare piccoli errori di sintassi. Per i casi di difficoltà media riorganizza le clausole e si assicura che la query sia allineata allo schema scelto. Per le domande più impegnative invoca il modello linguistico per un ragionamento più profondo, a volte decomponendo il problema in sottocompiti ed eseguendo query alternative. Cruciale è che TriSQL esegue sia la query originale sia quella perfezionata sul database e usa il loro comportamento—se vengono eseguite, quanto tempo impiegano e cosa restituiscono—per decidere quale versione mantenere o se tentare un ulteriore giro di raffinamento.
Mettere il sistema alla prova
Per verificare l’efficacia di TriSQL, gli autori lo testano su un benchmark ampiamente utilizzato chiamato Spider, insieme a diverse varianti più difficili che introducono conoscenze di dominio, schemi di frase insoliti e strutture di query più realistiche. Misurano due cose: exact match, che verifica se la stringa SQL generata è identica a una di riferimento scritta da un umano, e execution accuracy, che verifica se produce effettivamente la risposta corretta quando viene eseguita. Su questi dataset, TriSQL raggiunge la più alta execution accuracy riportata finora mantenendo l’exact match competitivo con i migliori sistemi precedenti. È anche più robusto: man mano che le domande passano da facili a estremamente difficili, le prestazioni di TriSQL diminuiscono molto più gradualmente rispetto ai metodi concorrenti. Esperimenti aggiuntivi su un dataset reale di gestione della rete elettrica mostrano che lo stesso framework può gestire non solo il recupero dati, ma anche comandi di insert, update, delete e creazione di tabelle. Adattamenti pilota a database a grafo (Cypher) e pipeline MongoDB suggeriscono che il design in tre fasi può estendersi oltre l’SQL classico.
Cosa significa questo per l’uso quotidiano dei dati
In termini semplici, questo lavoro ci avvicina a un mondo in cui le persone possono conversare con database complessi con la stessa facilità con cui oggi chattano con i motori di ricerca. Scegliendo con cura quali parti del database considerare, pianificando la struttura di una query prima di riempire i dettagli e adattando l’uso dei large language model alla difficoltà di ogni domanda, TriSQL produce query che hanno maggiori probabilità di essere eseguite correttamente e di restituire i risultati desiderati. Pur rimanendo sfide—come la gestione di domande ambigue e database mai visti prima—lo studio mostra che un design ponderato e a fasi può rendere le interfacce in linguaggio naturale per i dati sia più potenti sia più prevedibili per gli utenti di tutti i giorni.
Citazione: Su, X., Gu, Y., Wang, P. et al. A robust natural language text-to-SQL generation framework with dynamic strategies based on LLMs. Sci Rep 16, 7892 (2026). https://doi.org/10.1038/s41598-026-39128-9
Parole chiave: text-to-SQL, interfacce in linguaggio naturale, interrogazione di database, large language model, robustezza delle query