Clear Sky Science · it
Un approccio per gestire dataset sbilanciati usando lo spostamento del confine
Perché i casi rari sono importanti nei dati di tutti i giorni
Dalla frode bancaria e dalla diagnosi medica alla previsione dell'abbandono dei clienti, molte decisioni che chiediamo ai computer di prendere dipendono dall'individuazione di eventi rari ma cruciali. Nella maggior parte dei dataset reali questi casi importanti sono molto meno numerosi di quelli ordinari. Un modello che vede soprattutto la «normalità» può diventare cieco rispetto alle situazioni che ci interessano di più. Questo articolo presenta un nuovo modo per riequilibrare dati così sbilanciati affinché gli algoritmi di apprendimento prestino la giusta attenzione ai casi rari e ad alto impatto.
La trappola nascosta dei dati sbilanciati
Quando un tipo di esempio sovrasta notevolmente un altro, i metodi standard di machine learning tendono a concentrarsi sulla maggioranza e a trascurare silenziosamente la minoranza. Un sistema di previsione dell'abbandono, per esempio, può etichettare quasi tutti come clienti fedeli e ottenere comunque un'elevata accuratezza, semplicemente perché i veri abbandoni sono pochissimi. Problemi simili si manifestano nel rilevamento degli incidenti, nel monitoraggio delle frodi e nello screening medico, dove i casi positivi sono rari ma costosi da mancare. Le tecniche tradizionali per correggere questo si dividono in due categorie: adattare l'algoritmo di apprendimento per «dare più peso» alla minoranza, oppure rimodellare i dati stessi rimuovendo alcuni esempi della maggioranza (undersampling) o creando esempi aggiuntivi della minoranza (oversampling). Strumenti di oversampling popolari come SMOTE generano esempi sintetici della minoranza, ma possono involontariamente ingombrare la delicata regione di confine dove le due classi si incontrano.
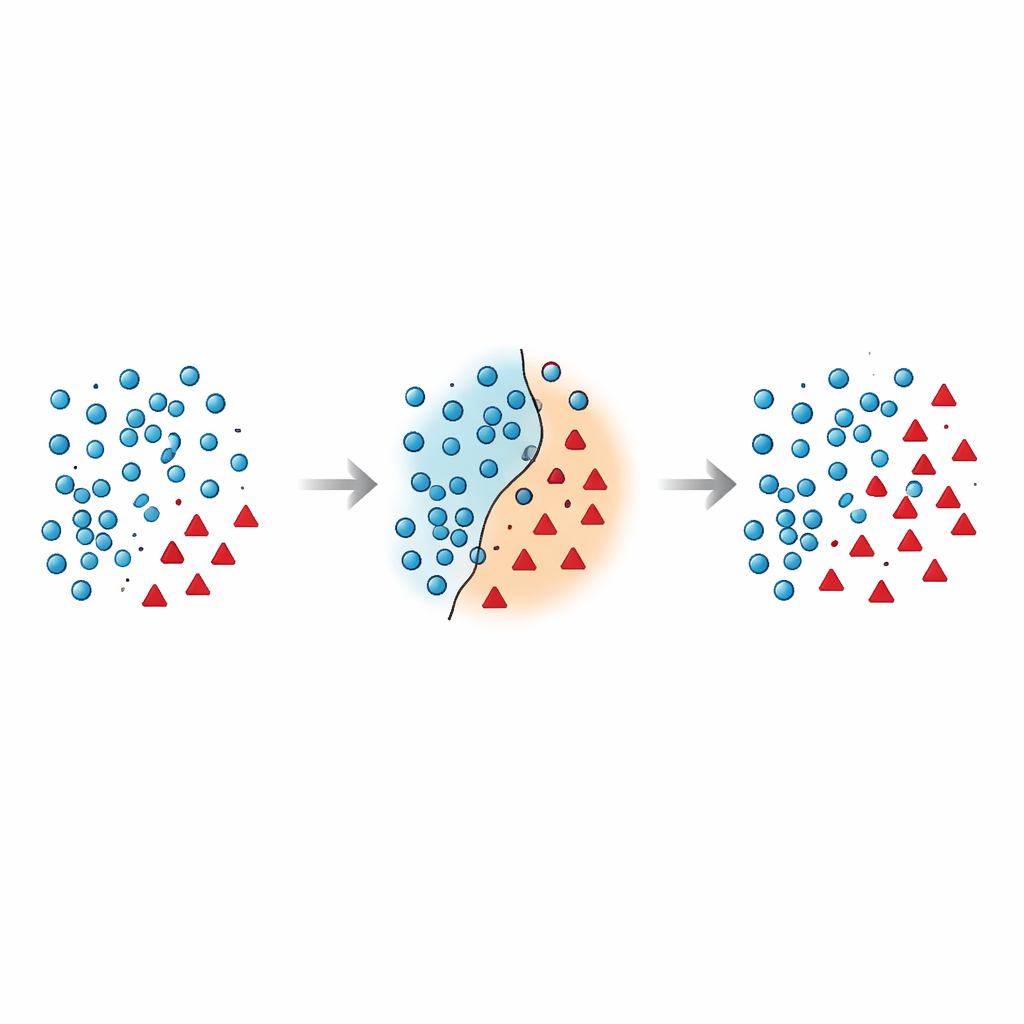
Perché il confine tra gruppi è così fragile
Gli autori sostengono che gli errori più pericolosi avvengono vicino al confine decisionale — la zona in cui i casi della maggioranza e della minoranza si sovrappongono nello spazio delle caratteristiche. Molte tecniche esistenti o aggiungono punti sintetici in questa regione rischiosa senza ripulirla, o cancellano dati in modo aggressivo eliminando per errore esempi informativi. Ricerche recenti hanno cercato di domare questo fenomeno usando vincoli geometrici, stime di densità locale o filtri di rumore, ma la maggior parte dei metodi tratta ancora i punti della minoranza nella loro posizione originale e raramente ripensa a come gestire i punti di maggioranza vicini al confine. Questo lascia un problema persistente: campioni sovrapposti e rumorosi che confondono il classificatore e portano a previsioni instabili, specialmente su dati nuovi.
Un metodo in due fasi per sistemare il confine
L'articolo introduce il Borderline Shifting Oversampling (BSO), un metodo di rimodellamento dei dati in due fasi che prende di mira esplicitamente questa problematica regione di confine. Prima, analizza il vicinato di ciascun esempio di maggioranza per decidere se si trovi in una zona sicura, sul confine o in una posizione chiaramente errata (rumore). I punti di maggioranza circondati da vicini della minoranza vengono o riclassificati verso il lato della minoranza o segnati come rumore e rimossi, pulendo e spostando efficacemente il confine in modo che rifletta meglio il pattern sottostante. Nella seconda fase, il metodo genera nuovi punti sintetici della minoranza usando un'interpolazione simile a SMOTE, ma solo attorno ai campioni di minoranza vicini al confine raffinato. Concentrando i nuovi dati dove sono più informativi ed evitando punti chiaramente rumorosi, BSO costruisce un set di addestramento che è sia più equilibrato nelle dimensioni sia più pulito nella struttura.
Mettere il metodo alla prova
Per valutare l'efficacia pratica, i ricercatori hanno testato BSO su 30 dataset di riferimento con diversi gradi di sbilanciamento e sovrapposizione. Lo hanno confrontato con sette alternative largamente utilizzate, tra cui Random Over‑ e Under‑Sampling, SMOTE, Borderline‑SMOTE, NearMiss e due metodi ibridi che combinano oversampling con pulizia del rumore (SMOTE‑Tomek e SMOTE‑ENN). Tre classificatori comuni — Support Vector Machines, Naïve Bayes e Random Forests — sono stati addestrati su ciascun dataset risamplato. Piuttosto che fare affidamento sulla sola accuratezza grezza, lo studio ha usato metriche più informative in presenza di sbilanciamento, come F1‑score, G‑mean, recall, precision e l'Area Under the ROC Curve (AUC). Su quasi tutti i dataset e classificatori, BSO ha fornito punteggi maggiori o comparabili mostrando allo stesso tempo minore variazione, il che significa che i suoi benefici sono stati costanti e non legati a un particolare modello o impostazione.
Cosa significa per le decisioni nel mondo reale
In termini concreti, l'approccio Borderline Shifting funziona come un attento editore per dati disordinati: pulisce gli esempi confusi vicino alla linea di demarcazione tra le classi e poi aggiunge il giusto numero di casi realistici della minoranza nei punti più adatti. Il risultato è che gli algoritmi di apprendimento diventano migliori nel riconoscere eventi rari ma importanti senza lasciarsi ingannare da sovrapposizioni rumorose. Per applicazioni come il rilevamento delle frodi, la previsione degli incidenti o il triage medico — dove perdere un caso di minoranza può essere costoso — questo metodo offre un modo pratico per rendere i modelli più equi, più sensibili e più affidabili, aggiungendo solo un modesto overhead computazionale.
Citazione: Malhat, M.G., Elsobky, A.M., Keshk, A.E. et al. An approach for handling imbalanced datasets using borderline shifting. Sci Rep 16, 8264 (2026). https://doi.org/10.1038/s41598-026-39118-x
Parole chiave: sbilanciamento delle classi, oversampling, confine decisionale, rilevamento anomalie, robustezza nel machine learning