Clear Sky Science · it
Un metodo per compilare oggetti geografici nelle mappe da immagini satellitari basato su dati vettoriali tramite deep learning
Perché importa modificare ciò che le mappe mostrano
Le mappe online spesso sembrano finestre sul mondo reale, ma ciò che si vede dall’alto è progettato con cura. Le mappe basate su immagini satellitari sono apprezzate perché sembrano luoghi reali; tuttavia a volte è necessario nascondere strutture sensibili, ripulire scene ingombrate o garantire che tipi diversi di mappe siano coerenti tra loro. Questo articolo presenta un nuovo modo per "modificare" automaticamente le immagini satellitari usando l’intelligenza artificiale, in modo che edifici e strade possano essere rimossi, aggiunti, spostati o rimodellati pur mantenendo un aspetto naturale e credibile. 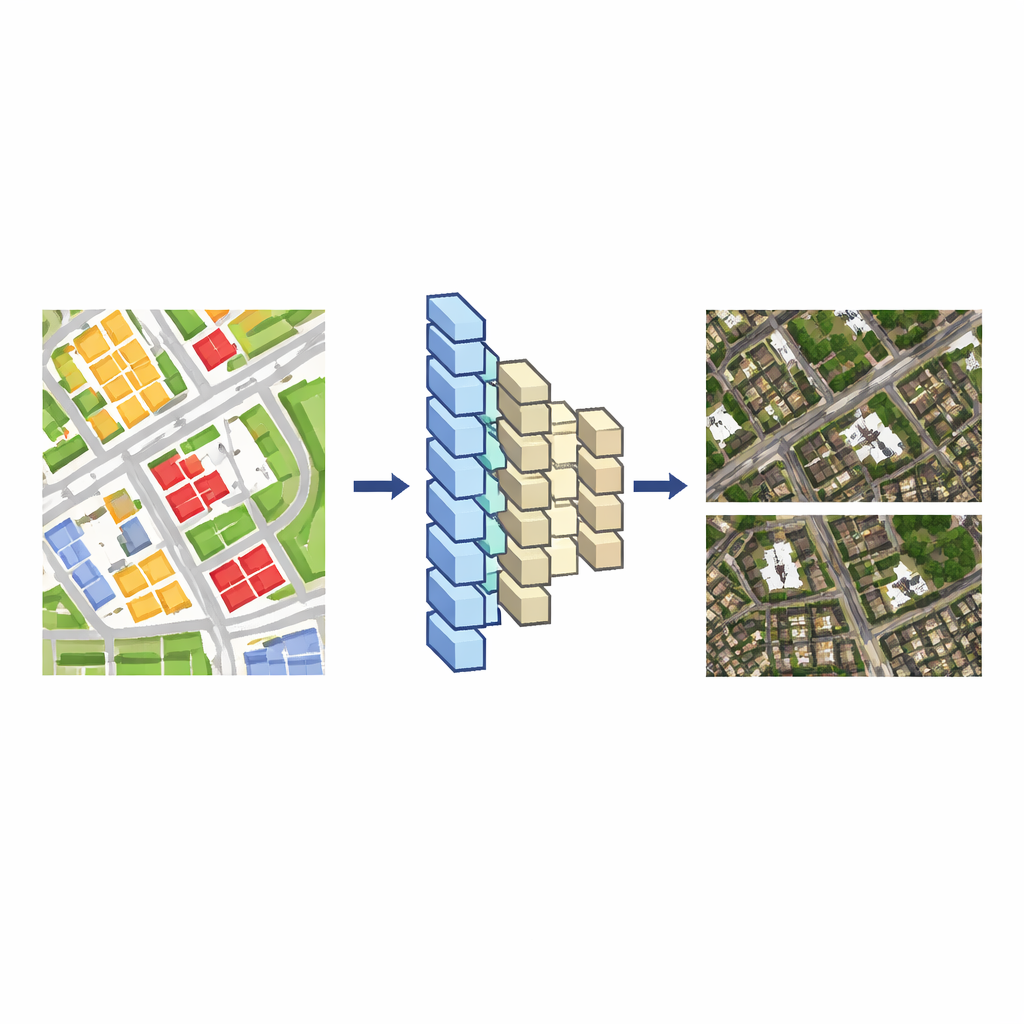
Da disegni semplici a viste realistiche
I moderni sistemi cartografici generalmente contengono due tipi di dati geografici. Uno è l’immagine satellitare stessa, un fitto mosaico di pixel. L’altro è una mappa vettoriale, un disegno più pulito costituito da linee e forme che segnano strade, edifici, fiumi e altro. Modificare la mappa vettoriale è relativamente semplice, ma cambiare manualmente l’immagine satellitare corrispondente è lento e laborioso, perché i pixel di ogni edificio si fondono con ombre, alberi e strutture vicine. L’idea centrale degli autori è insegnare a un modello di deep learning a tradurre questi disegni vettoriali in immagini satellitari realistiche. Una volta che il modello ha appreso questa correlazione, qualsiasi modifica alla mappa vettoriale può essere trasformata automaticamente in un cambiamento coerente nella vista satellitare.
Insegnare a un’IA a immaginare le città
Per costruire questo traduttore, i ricercatori partono da aree in cui una mappa vettoriale e un’immagine satellitare coprono la stessa regione a una scala simile. Tagliano entrambe in molte piccole tessere, accoppiando ogni tessera vettoriale con la corrispondente tessera d’immagine, e usano queste coppie come dati di addestramento. Una rete neurale encoder–decoder—simile agli strumenti usati per la traduzione immagine-immagine—impara come l’insieme di blocchi colorati e linee nella tessera vettoriale si relaziona a tetti, strade e vegetazione nella tessera satellitare. Confrontano due architetture di rete popolari, UNet++ e Pix2Pix, e trovano che Pix2Pix produce immagini dallo stile satellitare che corrispondono più da vicino alla realtà e si addestrano in modo più affidabile, perciò diventa il loro modello di base.
Focalizzare il modello sui punti da modificare
Imparare semplicemente dall’intera città non è sufficiente quando si vogliono modificare oggetti specifici in modo netto. Per affinare l’abilità del modello attorno alle aree target, gli autori usano il transfer learning. Estraggono tessere di addestramento aggiuntive che circondano gli edifici o le strade che intendono modificare e avviano una breve fase di addestramento supplementare utilizzando solo questi esempi locali. Questo passaggio di fine-tuning migliora notevolmente la capacità del modello di riprodurre quei quartieri, rendendo le modifiche successive più nette e precise. 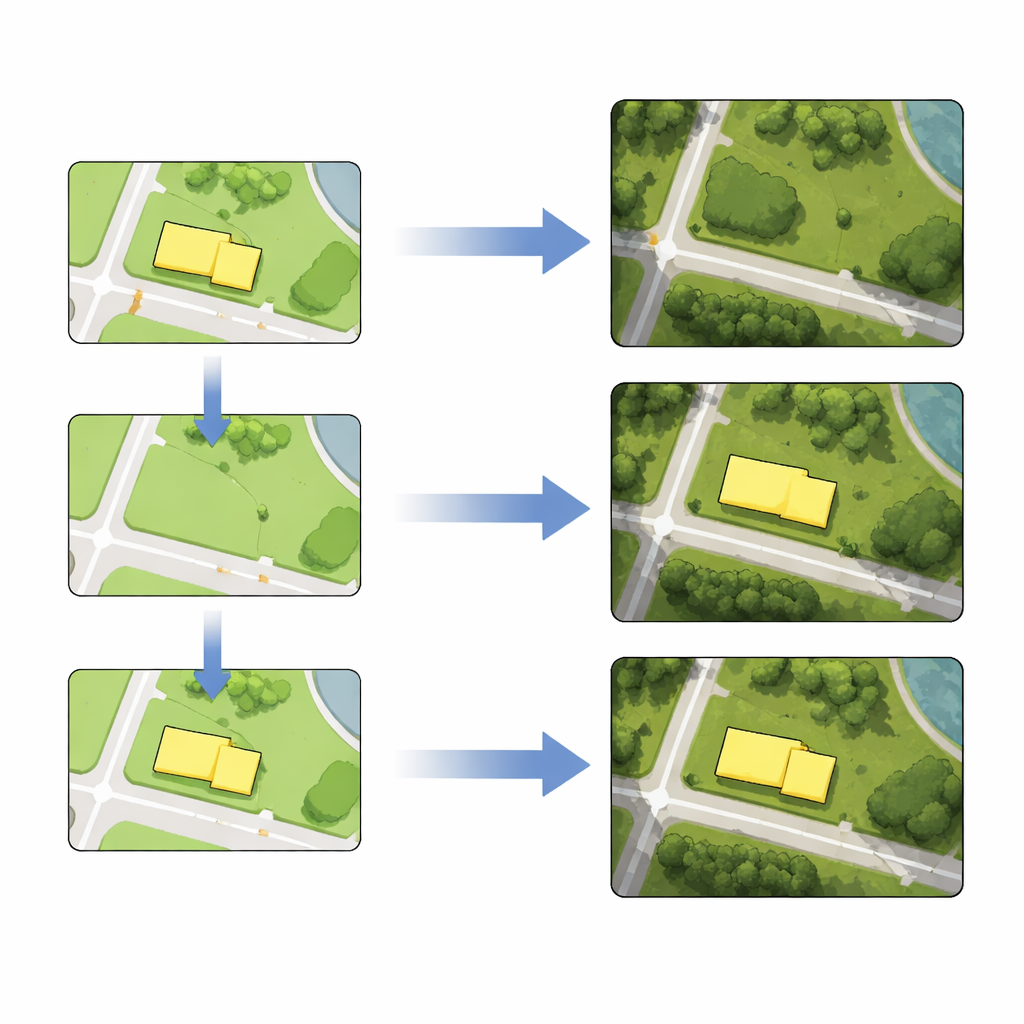
Modificare edifici e strade come livelli di mappa
Con il modello ottimizzato, compilare mappe basate su immagini satellitari diventa una ricetta in tre passaggi. Primo, un cartografo modifica la mappa vettoriale: elimina un edificio, disegna una nuova strada, rimodella un isolato o sposta un oggetto in una nuova posizione. Secondo, le tessere modificate della mappa vettoriale vengono inserite nella rete addestrata, che genera nuove tessere satellitari che riflettono il cambiamento desiderato preservando i dettagli e le texture circostanti. Terzo, queste tessere generate sostituiscono le tessere d’immagine originali. Usando dati reali di Berlino, gli autori dimostrano tutte e quattro le operazioni—eliminazione, inserimento, distorsione e spostamento—sia per le impronte degli edifici sia per le linee stradali, singolarmente o in blocco. Le misurazioni mostrano che le posizioni degli oggetti modificati nelle immagini generate differiscono dalle controparti vettoriali di solo pochi pixel, una precisione accettabile per molte attività cartografiche.
Cosa significa per le mappe del futuro
In termini semplici, lo studio mostra che una volta che un’IA ha appreso come le mappe vettoriali e le immagini satellitari corrispondono, è possibile modificare il disegno semplice e lasciare che il modello ridipinga una vista aerea credibile per adattarsi. Questo apre la porta a mappe da immagini satellitari personalizzabili: nascondere siti sensibili, chiarire scene complesse o fondere spazi reali e immaginari come mondi di gioco e ambienti virtuali. Allo stesso tempo, mette in luce la potenza—e il rischio—della geografia “deepfake”, dove immagini aeree dall’aspetto realistico potrebbero non essere più fotografie dirette del mondo così com’è.
Citazione: Du, J., Zeng, D., Cai, K. et al. A method for compiling satellite image map geographic objects based on vector map data via deep learning. Sci Rep 16, 9295 (2026). https://doi.org/10.1038/s41598-026-39096-0
Parole chiave: immagini satellitari, deep learning, modifica delle mappe, telerilevamento, cartografia deepfake