Clear Sky Science · it
I grandi modelli linguistici mostrano effetti simili al fenomeno Dunning-Kruger nel fact-checking multilingue
Perché il fact-checking intelligente conta per tutti
La disinformazione si diffonde oggi più rapidamente che mai, plasmando le convinzioni delle persone su salute, politica, scienza e vita quotidiana. Sempre più piattaforme e redazioni si affidano all’intelligenza artificiale—in particolare ai grandi modelli linguistici, o LLM—to per aiutare a verificare se affermazioni virali siano vere o false. Questo studio pone una domanda apparentemente semplice ma cruciale: quando lasciamo che questi sistemi giudichino i fatti, quanto spesso hanno ragione, quanto sicuri appaiono e questo cambia a seconda della lingua e della regione del mondo?
Come i ricercatori hanno messo alla prova l’IA contro voci del mondo reale
Invece di inventare esempi artificiali, gli autori hanno costruito i loro test su 5.000 affermazioni autentiche già verificate da organizzazioni professionali di fact-checking in tutto il mondo. Queste affermazioni coprivano 47 lingue e provenivano sia dal Nord che dal Sud del mondo, riflettendo la realtà variegata e multiculturale delle dicerie online. Sono state incluse solo le affermazioni con verdetti chiari di “vero” o “falso”, concordati da più fact-checker, creando così un solido terreno di verità per il confronto.
Successivamente hanno fatto eseguire nove modelli linguistici ampiamente usati, da sistemi open-source più piccoli a soluzioni commerciali avanzate, su ogni singola affermazione. Per rispecchiare il modo in cui le persone interagiscono con i chatbot, la maggior parte dei prompt erano semplici domande come “È vero?” o “È falso?”, scritte nella stessa lingua dell’affermazione. Una quarta impostazione, più professionale, usava un’istruzione dettagliata in inglese che trasformava il modello in un verificatore virtuale dei fatti e richiedeva output strutturati. Annotatori umani hanno letto con cura le risposte dei modelli e le hanno etichettate come affermazioni che dichiaravano la notizia vera, falsa, o come rifiuto di dare un verdetto chiaro.
Misurare non solo giusto o sbagliato, ma anche quando dire “Non lo so”
Il team ha fatto più che conteggiare successi e insuccessi. Ha utilizzato tre misure chiave per catturare il comportamento dei modelli. Primo, la “precisione selettiva” ha considerato quanto spesso un modello fosse corretto quando effettivamente prendeva posizione e dichiarava un’affermazione vera o falsa. Secondo, la “precisione favorevole all’astensione” ha trattato come accettabile, e persino desiderabile, che il modello ammettesse incertezza invece di indovinare, caratteristica vitale in ambiti sensibili come medicina o elezioni. Terzo, il “tasso di certezza” ha tracciato con quale frequenza un modello forniva una risposta definitiva, servendo come indicatore approssimativo del grado di sicurezza mostrato.
Il prompt in stile professionale, con la sua guida passo-passo, ha costantemente aumentato la precisione su tutti i modelli. Ma ha anche rivelato un trade-off: i modelli più piccoli spesso diventavano più risoluti senza migliorare in affidabilità, mentre i modelli più grandi sfruttavano la struttura per fornire meno risposte, ma di qualità migliore. I prompt di tipo conversazionale hanno prodotto comportamenti più cauti, specialmente nei modelli più deboli, ma hanno anche leggermente ridotto la loro accuratezza.
Quando sistemi meno capaci appaiono più sicuri di sé
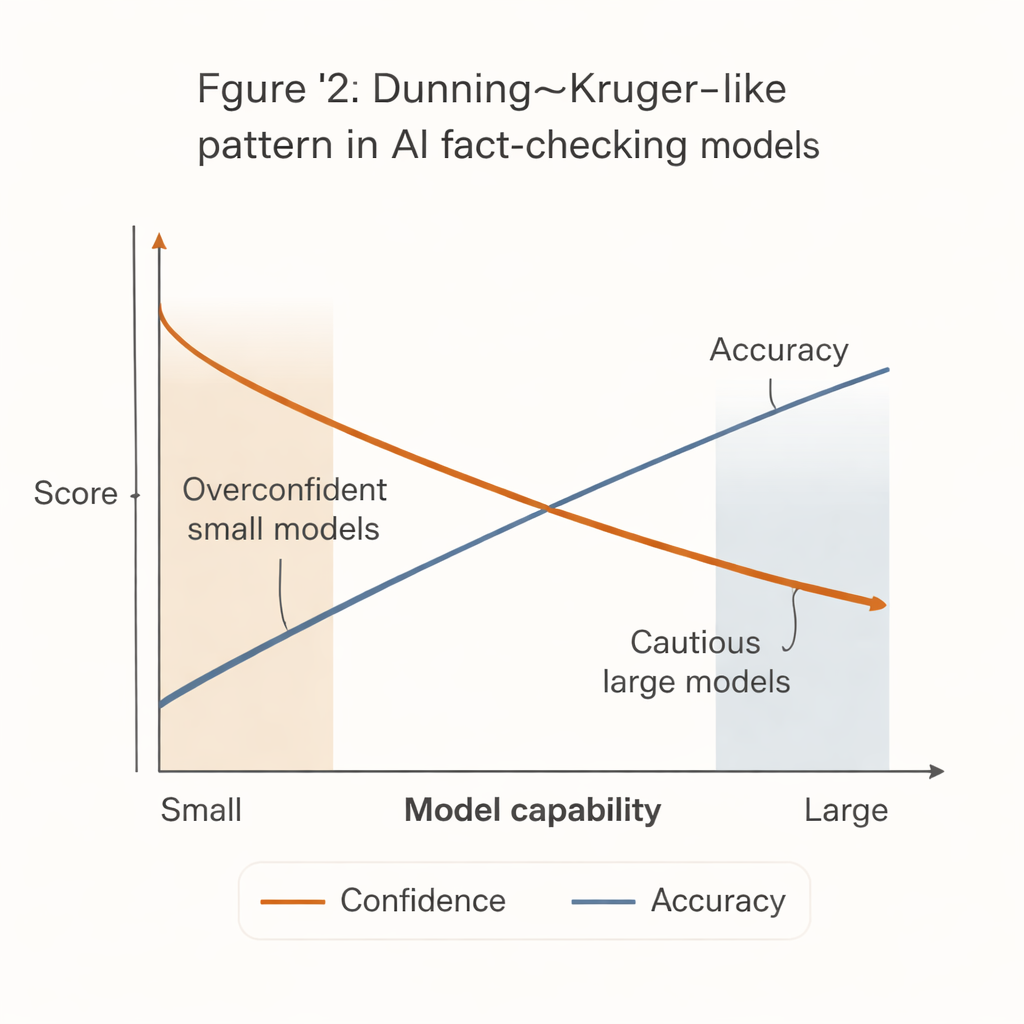
È emerso uno schema sorprendente che rispecchia il noto effetto Dunning–Kruger della psicologia umana: i sistemi meno capaci si comportano come i più sicuri. I modelli piccoli e economici tendevano a emettere verdetti fermi per la grande maggioranza delle affermazioni, ma con accuratezza notevolmente inferiore. Al contrario, i modelli più potenti—come le versioni avanzate di GPT—erano molto più accurati quando prendevano posizione, ma molto più propensi ad astenersi, soprattutto su affermazioni difficili o ambigue.
Questo “divario fiducia-competenza” ha conseguenze nel mondo reale. Molte redazioni con risorse limitate, ONG e centri locali di fact-checking non possono permettersi i sistemi di IA più potenti. È più probabile che adottino modelli più piccoli ed economici che appaiono decisi ma sono più spesso errati. Se questi strumenti vengono integrati in flussi di lavoro o sistemi di moderazione comunitaria senza adeguate salvaguardie, potrebbero invece amplificare la disinformazione producendo verifiche dei fatti sicure ma sbagliate.
Prestazioni diseguali tra lingue e regioni
Lo studio rivela inoltre che questi sistemi non funzionano allo stesso modo per tutti. In diverse lingue principali, i modelli in generale hanno reso meglio sulle affermazioni in inglese e leggermente peggio su portoghese e hindi. I modelli più grandi tendevano a rispondere con maggiore cautela nelle lingue non inglesi, ma comunque superavano quelli più piccoli in accuratezza. Quando gli autori hanno confrontato affermazioni legate al Nord del mondo e al Sud del mondo, la maggior parte dei modelli ha mostrato più difficoltà su queste ultime. I sistemi più piccoli spesso rimanevano sicuri mentre perdevano accuratezza, mentre i modelli grandi mostravano cali più marcati nella certezza ma diminuzioni più contenute nella correttezza, suggerendo che percepivano la propria incertezza e si trattenevano.
Cosa significa questo per il futuro di strumenti IA affidabili
Per un pubblico non specialista, il messaggio principale è chiaro: i verificatori di fatti basati su IA di oggi sono ben lontani dall’essere equivalenti, e quelli più accessibili possono essere i più fuorvianti. I modelli potenti possono essere cauti e accurati, ma sono costosi e talvolta eccessivamente esitanti. I modelli più deboli sono audaci ma più soggetti a errore, specialmente al di fuori dell’inglese e nelle notizie provenienti dal Sud del mondo. Gli autori sostengono che l’IA dovrebbe supportare, non sostituire, i fact-checker umani, e che scelte di politica e di progettazione devono promuovere una migliore calibrazione—insegnando ai sistemi quando tacere—e un accesso più equo a strumenti di alta qualità. Altrimenti, la stessa tecnologia concepita per combattere la disinformazione potrebbe approfondire le disuguaglianze informative che intendeva risolvere.
Citazione: Qazi, I.A., Khan, Z., Ghani, A. et al. Large language models show Dunning-Kruger-like effects in multilingual fact-checking. Sci Rep 16, 7594 (2026). https://doi.org/10.1038/s41598-026-39046-w
Parole chiave: disinformazione, verifica dei fatti, grandi modelli linguistici, fiducia dell'IA, bias multilingue