Clear Sky Science · it
Un framework ibrido LSTM-GRU per la classificazione del cancro ai polmoni usando l'algoritmo GWO-WOA per l'ottimizzazione degli iperparametri e BPSO per la selezione delle caratteristiche
Perché è importante per la salute quotidiana
Individuare il cancro ai polmoni precocemente può salvare vite, ma molte persone non eseguono esami avanzati fino a quando non è troppo tardi. Questo studio indaga se semplici controlli basati su questionari — su età, fumo, sintomi e abitudini quotidiane — possano essere integrati con l'intelligenza artificiale moderna per individuare soggetti ad alto rischio molto prima che compaia una malattia grave. Sfruttando al meglio questionari a basso costo e modelli computazionali intelligenti, il lavoro indica la strada verso strumenti di screening più rapidi e accessibili che un giorno potrebbero supportare medici e programmi di sanità pubblica in tutto il mondo.
Trasformare semplici domande in segnali utili
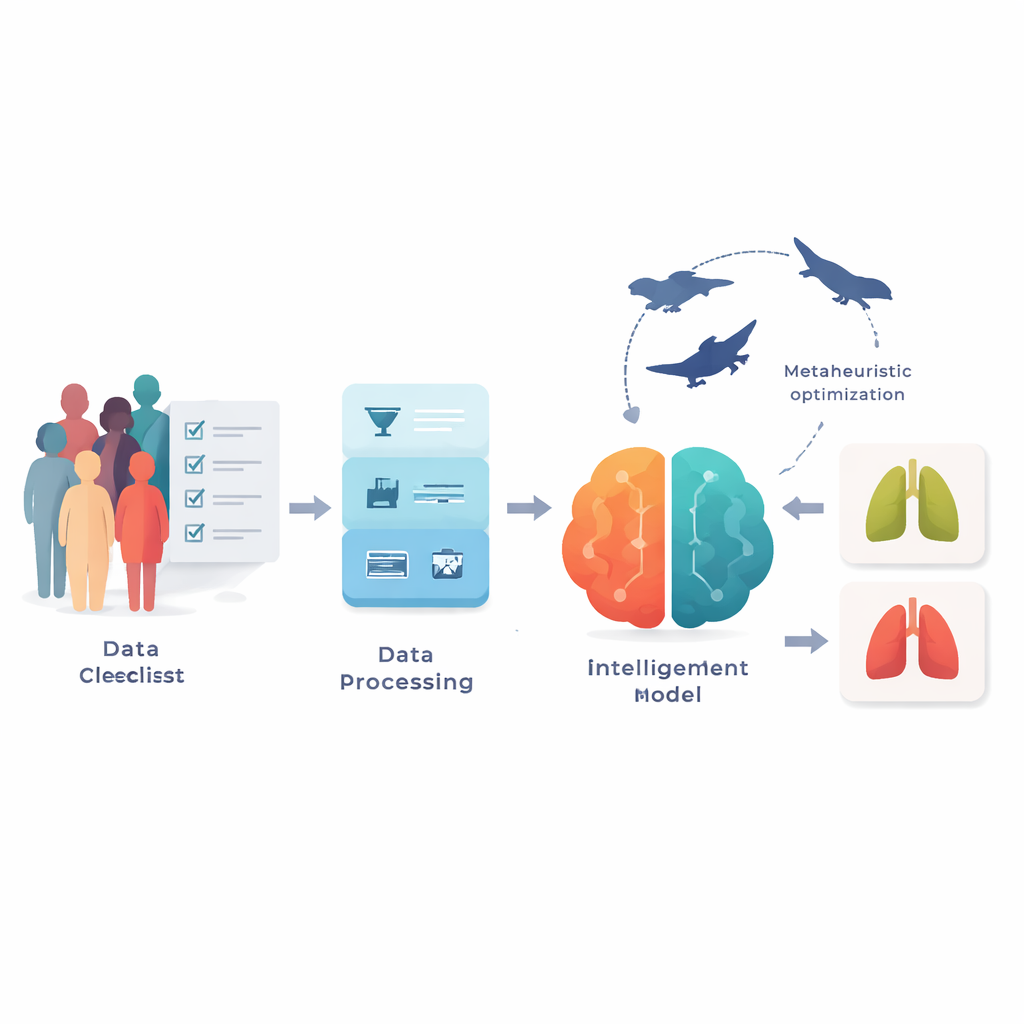
I ricercatori hanno lavorato con due dataset pubblici dal sito Kaggle, che insieme comprendono oltre 3.300 persone. Invece di immagini mediche, ogni record contiene 15 voci che potresti trovare su un modulo clinico: età, sesso, stato di fumatore, dita ingiallite, tosse, mancanza di respiro, dolore toracico e fattori di rischio e sintomi analoghi, oltre a un'etichetta che indica la presenza di cancro al polmone. Poiché i dati reali dei questionari sono spesso disordinati, il team ha prima pulito le informazioni correggendo voci mancanti, rimuovendo duplicati e uniformando la codifica delle risposte tra i due dataset. Hanno anche normalizzato i valori in modo che tutte le caratteristiche fossero su una scala simile e utilizzato un metodo di bilanciamento per correggere un forte sbilanciamento verso i casi di cancro nel dataset più piccolo, aiutando il modello a evitare il bias di predire solo la classe di maggioranza.
Lasciare che il computer scelga le domande più indicative
Non tutte le domande su un modulo sono ugualmente utili per individuare la malattia, e usarne troppe può effettivamente confondere un modello. Per concentrarsi su ciò che conta davvero, gli autori hanno impiegato una strategia di ricerca ispirata agli sciami chiamata Binary Particle Swarm Optimization. In termini semplici, molti candidati “insiemi di domande” vengono testati in parallelo e si muovono nello spazio delle possibilità, copiando e migliorando i migliori esemplari. Col tempo, questo processo ha selezionato insiemi compatti di circa sette domande chiave, mettendo ripetutamente in evidenza caratteristiche come il fumo, le dita ingiallite, la tosse, il dolore toracico, il respiro sibilante, la mancanza di respiro e le malattie croniche. Questi insiemi mirati hanno migliorato l'accuratezza di diversi punti percentuali rispetto all'uso delle 15 domande, rendendo al contempo il modello finale più interpretabile e più veloce da eseguire.

Un motore più intelligente per leggere i pattern nelle risposte
Per trasformare le risposte del questionario in una previsione sì/no sul cancro, il team ha costruito un modello ibrido che combina due unità di deep learning correlate spesso usate per sequenze: Long Short-Term Memory (LSTM) e Gated Recurrent Unit (GRU). Sebbene le risposte a un questionario non siano serie temporali come il parlato o il video, gruppi di sintomi e abitudini formano comunque pattern che possono essere trattati come brevi sequenze. Il modello alimenta prima le domande selezionate attraverso strati LSTM che possono memorizzare e dimenticare informazioni in modo selettivo, poi attraverso strati GRU che raffinano questi pattern con meno passaggi interni e minori costi computazionali. Per evitare il design per prova ed errore, gli autori hanno ottimizzato impostazioni cruciali — come il learning rate, il numero di unità nascoste, la dimensione del batch e il dropout — usando un secondo livello di ricerca ispirata alla natura che combina l'ampia esplorazione dei “lupi grigi” con gli aggiustamenti fini delle “balene”. Questo ottimizzatore congiunto ricerca combinazioni di iperparametri che forniscono costantemente alta accuratezza durante la cross‑validation.
Quanto bene ha funzionato il sistema
Dopo l'addestramento, il modello ibrido LSTM–GRU è stato confrontato con diversi solidi baseline, inclusi reti LSTM e GRU standalone, una rete neurale convoluzionale, support vector machine tradizionali e metodi basati su alberi come random forest e gradient boosting. Sul dataset più piccolo di 309 persone, il sistema proposto ha classificato correttamente ogni singolo caso nella porzione di test tenuta da parte, raggiungendo il 100% di accuratezza, precisione, recall e F1‑score. Sul dataset più esteso di 3.000 persone, si è mantenuto quasi perfetto, con circa il 99,3% di accuratezza e punteggi altrettanto elevati nelle altre misure, superando tutti i modelli concorrenti sia deep‑learning che classici. Gli autori hanno inoltre mostrato che la loro strategia a due stadi — prima selezionare le domande con la ricerca a sciame, poi ottimizzare la rete ibrida con l'ottimizzatore lupi‑e‑balene — ha fornito risultati più stabili attraverso ripetute esecuzioni di cross‑validation rispetto a configurazioni più semplici.
Cosa significa per il futuro dello screening polmonare
In termini pratici, questo lavoro dimostra che un sistema di IA ben progettato può leggere risposte di un questionario ordinario e separare con grande accuratezza persone con e senza cancro ai polmoni su dataset di riferimento. Non sostituisce le scansioni, i medici o le sperimentazioni cliniche, e gli autori sottolineano che i loro dati sono limitati e non ancora pronti per un uso diretto in ambito ospedaliero. Tuttavia, l'approccio dimostra che combinare una selezione intelligente delle domande con motori di deep learning finemente tarati può trasformare moduli a basso costo in potenti strumenti di allerta precoce. Con ulteriori test su popolazioni più ampie e clinicamente curate e con migliori metodi di spiegabilità per mostrare perché il modello segnala una persona come ad alto rischio, sistemi simili potrebbero un giorno aiutare a decidere chi indirizzare verso esami di imaging più dettagliati, favorendo diagnosi più precoci mantenendo lo screening economico e non invasivo.
Citazione: Amrir, M.M.S., Ayid, Y.M., Elshewey, A.M. et al. A hybrid LSTM-GRU framework for lung cancer classification using GWO-WOA algorithm for hyperparameter tuning and BPSO for feature selection. Sci Rep 16, 8600 (2026). https://doi.org/10.1038/s41598-026-39020-6
Parole chiave: screening del cancro ai polmoni, dati da questionario, deep learning, selezione delle caratteristiche, IA medica