Clear Sky Science · it
Una strategia di controllo umanoide basata sul deep reinforcement learning per un maggiore comfort nei robot di riabilitazione degli arti inferiori
Robot che aiutano le persone a camminare di nuovo
Quando qualcuno ha difficoltà a camminare dopo un ictus o un trauma spinale, la terapia può essere lenta, faticosa e scomoda. I robot per la riabilitazione degli arti inferiori sono progettati per sostenere e guidare le gambe del paziente durante l’esercizio, ma le macchine attuali spesso risultano rigide e “robotiche”. Questo studio esplora come dotare questi robot di un comportamento più umano — utilizzando algoritmi di apprendimento avanzati — possa rendere l’allenamento più dolce, più naturale e, in ultima analisi, più efficace per i pazienti.
Perché la pratica del camminare deve sembrare naturale
Con l’invecchiamento della popolazione, sempre più persone vivono con seri problemi di deambulazione e molte si rivolgono alla riabilitazione assistita da robot. I robot tradizionali seguono traiettorie pre-programmate per le gambe e utilizzano regole di controllo semplici per muovere le articolazioni. Pur essendo affidabili, questi metodi faticano a gestire la realtà disordinata del movimento umano: il passo di ciascuno è leggermente diverso e un robot rigido può tirare o spingere in modi che risultano goffi o addirittura dolorosi. Gli autori sostengono che perché la riabilitazione sia efficace, il robot deve non solo mantenere il paziente eretto e in movimento, ma anche adattarsi ai modelli naturali del camminare e minimizzare le forze che esercita sul corpo.
Apprendere dai passi umani reali
Per insegnare al robot come camminano davvero le persone, i ricercatori hanno prima costruito un modello matematico semplificato delle gambe e del tronco. Hanno poi registrato dati di deambulazione di cinque volontari sani usando un sistema di acquisizione di movimento 3D ad alta precisione e pedane di forza nel pavimento. Marcatori riflettenti su anche, ginocchia, caviglie e tronco hanno permesso di calcolare come ogni articolazione si muoveva durante un passo completo, mentre i sensori sotto i piedi misuravano quanto ogni gamba spingeva contro il suolo. Da queste misure sono state create curve di riferimento lisce per gli angoli di anche e ginocchia e tracciato come variavano nel tempo le forze articolari, catturando sia la forma sia il ritmo del camminare normale.
Un controllore più intelligente che però mantiene la sicurezza
Il cuore dell’articolo è una nuova strategia di controllo “umanoide” che combina il deep reinforcement learning (DRL) con un classico controllore proporzionale-derivativo (PD). Il DRL è un tipo di intelligenza artificiale in cui un agente virtuale prova azioni, osserva i risultati e scopre gradualmente cosa funziona meglio massimizzando un segnale di ricompensa. In questo caso l’agente si trova sopra il controllore PD: osserva gli angoli e le velocità delle articolazioni del robot e decide quali coppie applicare, mentre lo strato PD assicura che le articolazioni non si discostino troppo dagli angoli target sicuri e simili a quelli umani. La funzione di ricompensa è progettata con cura per favorire una camminata stabile in avanti penalizzando qualsiasi aspetto che risulterebbe sgradevole per un paziente — come movimenti scattosi, forze elevate alle articolazioni o posture insicure come un’inclinazione eccessiva o una bassa clearance del piede.
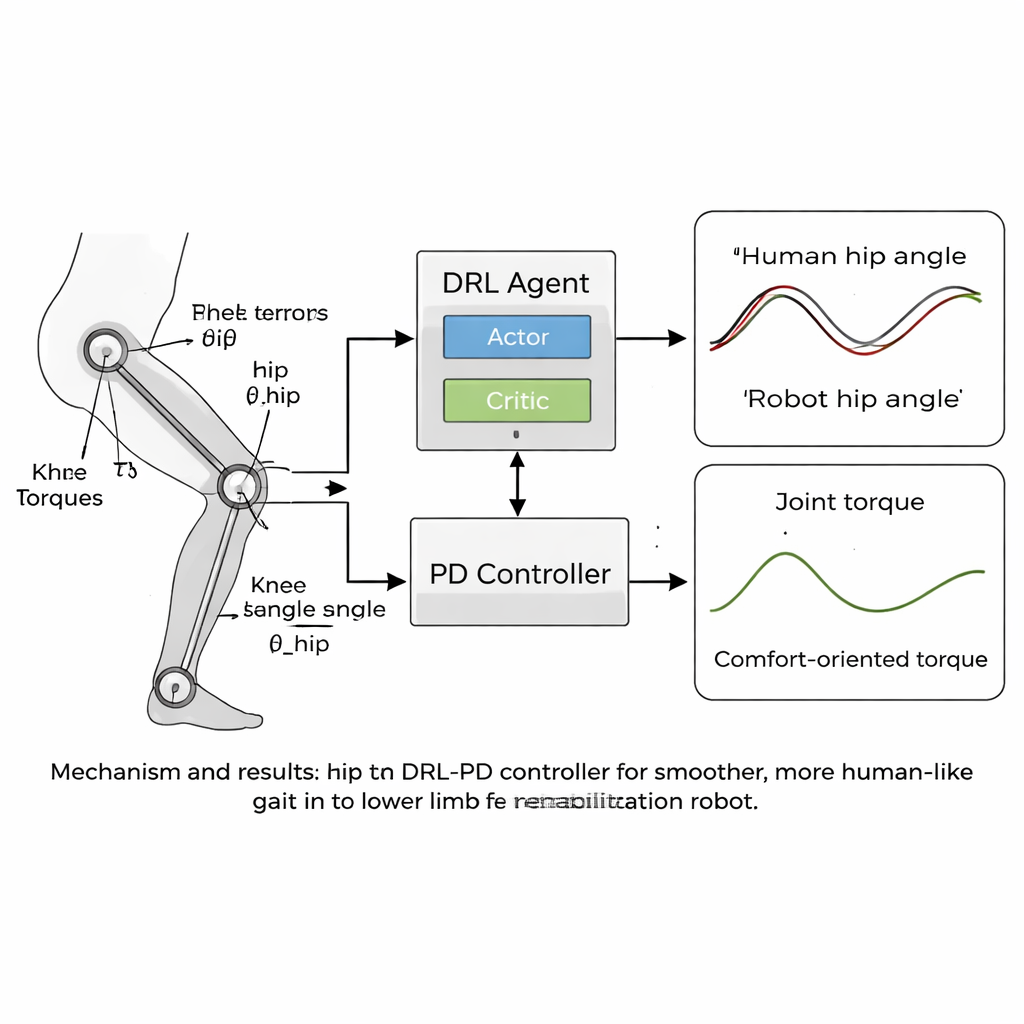
Movimento più fluido, più vicino al passo umano
Il team ha testato l’approccio in simulazioni al computer usando un modello di robot per la riabilitazione degli arti inferiori con articolazioni di anche e ginocchia che corrispondevano ai loro dati di deambulazione. Nel corso di migliaia di episodi di addestramento, il controllore DRL-PD ha imparato a produrre un ciclo di cammino ripetitivo in cui gli angoli articolari seguivano da vicino i modelli di riferimento umani. Anche e ginocchia del robot si muovevano in loop regolari e stabili, segno di un passo affidabile e ripetibile. Crucialmente, le coppie necessarie per muovere le articolazioni sono diventate più morbide e di entità inferiore rispetto a un controllore PD standard. Misure quantitative hanno mostrato che gli errori di tracciamento sono scesi a poche centesimi di radiante, e la velocità con cui variavano le coppie articolari — un proxy di quanto i movimenti potessero risultare “scattosi” per un paziente — è stata ridotta di oltre la metà. Il controllore è rimasto stabile anche quando le masse delle gambe nel modello variavano di alcuni percentuali, suggerendo che potrebbe tollerare differenze reali tra gli utenti.
Cosa significa questo per i futuri robot riabilitativi
Per i non specialisti, il messaggio è semplice: permettendo a un robot di apprendere i ritmi e i limiti del camminare umano a partire da dati reali, e premiandolo per essere morbido e gentile, possiamo progettare macchine che aiutino le persone a esercitarsi a camminare in modo più naturale e meno stressante. I pazienti potrebbero essere più inclini a partecipare a sessioni più lunghe e più frequenti se il robot si muove con loro piuttosto che contro di loro. Sebbene i risultati attuali derivino da simulazioni e richiedano computer potenti per l’addestramento, una volta completato l’apprendimento il controllore può funzionare con efficienza su dispositivi reali. Gli autori vedono questo lavoro come un passo verso robot di riabilitazione personalizzati e adattivi che si adeguano al passo e alle esigenze di comfort di ciascun paziente, potenzialmente migliorando sia il recupero sia la qualità della vita.
Citazione: Jin, Y., Zhang, J., Li, W. et al. A humanoid control strategy based on deep reinforcement learning for enhanced comfort in lower limb rehabilitation robots. Sci Rep 16, 7370 (2026). https://doi.org/10.1038/s41598-026-39011-7
Parole chiave: robot per la riabilitazione, allenamento del passo, deep reinforcement learning, esoscheletro, comfort del paziente