Clear Sky Science · it
Un framework di deep learning a doppio flusso per il riconoscimento continuo della lingua dei segni per migliorare l’accessibilità comunicativa nella regione di Ha’il
Colmare il divario comunicativo
Per molte persone sorde la lingua dei segni è il principale mezzo di comunicazione, eppure la maggior parte dei computer, dei telefoni e dei servizi pubblici non la comprendono ancora. Questo articolo presenta un nuovo sistema di intelligenza artificiale in grado di osservare segni continui in video e convertirli in parole scritte con maggiore accuratezza. Prestando attenzione non solo ai movimenti delle mani ma anche alla posizione della testa e ai segnali del viso, il sistema mira a rendere la comunicazione tecnologica più naturale e accessibile—soprattutto per le comunità sorde nella regione di Ha’il in Arabia Saudita, dove il supporto digitale è ancora limitato. 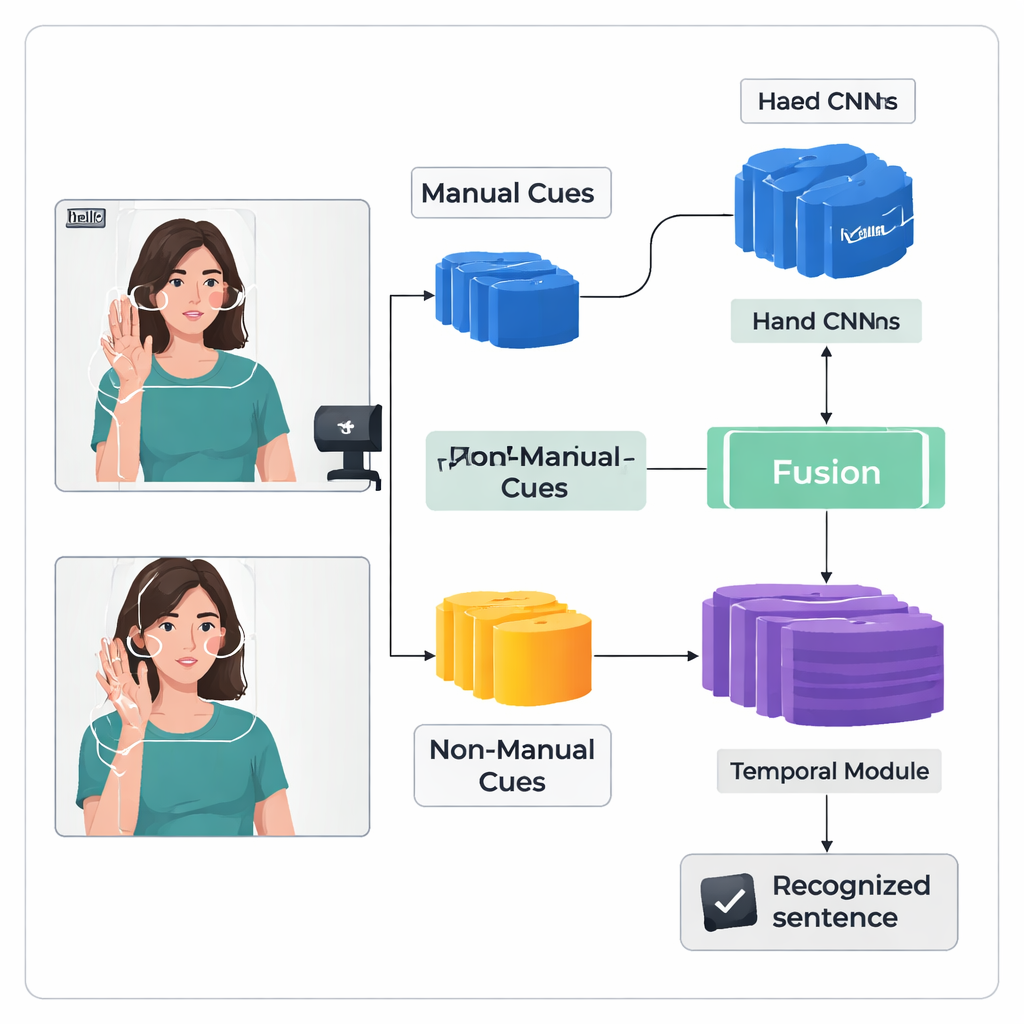
Perché le mani non bastano
Le lingue dei segni sono sistemi ricchi e complessi che coinvolgono tutta la parte superiore del corpo. Il significato non deriva soltanto dal modo in cui le mani si muovono, ma anche dalle espressioni facciali, da dove guarda il firmatario e da come inclina o annuisce con la testa. Questi segnali non manuali possono indicare domande, negazione, enfasi o emozione. Gli esseri umani li leggono senza sforzo, ma la maggior parte dei sistemi informatici per il riconoscimento della lingua dei segni si concentra quasi esclusivamente sulle mani. Questa scorciatoia semplifica l’addestramento ma fa perdere indizi importanti, soprattutto quando i segni si susseguono rapidamente in frasi continue piuttosto che come parole isolate.
Due flussi che lavorano in parallelo
Gli autori introducono un framework di deep learning a “doppio flusso” chiamato TS-CNN che elabora separatamente mani e testa, per poi integrarli. Un flusso si concentra su immagini ritagliate delle mani del firmatario, apprendendo schemi di forma, movimento e posizione. L’altro flusso riceve una mappa compatta del viso e della testa, derivata da punti di riferimento e stime della posa della testa. Entrambi i flussi usano un tipo standard di rete visiva per trasformare ogni frame video in feature numeriche. Il sistema fonde poi queste feature frame per frame, rispettando il fatto che segnali di mani e testa compaiono contemporaneamente nella firma reale. Un modulo temporale successivo analizza molti frame per comprendere come i segni si sviluppano nel tempo, e uno strato ricorrente produce una sequenza di unità di segno previste, o gloss.
Affinare la memoria del sistema sui segni
Riconoscere la firma continua è difficile perché i dati di addestramento sono limitati e i segni si confondono senza etichette chiare frame per frame. Per affrontare questo problema, gli autori aggiungono un Modulo di Potenziamento delle Feature che fornisce alla rete una guida extra durante l’addestramento. Una tecnica ampiamente usata allinea la sequenza di gloss predetta con il video, producendo posizioni probabili per ogni gloss nel tempo. Il nuovo modulo prende questi suggerimenti di allineamento e li usa come supervisione diretta per affinare la rappresentazione interna delle feature dei gloss. In termini semplici, il sistema impara non solo a produrre la sequenza corretta, ma anche a costruire “memorie” interne più chiare e coerenti di come appare ogni segno attraverso video differenti.
Mettere l’approccio alla prova
Il team valuta TS-CNN su due dataset noti di lingua dei segni: RWTH-PHOENIX-Weather 2014 per la lingua dei segni tedesca e CSL Split II per la lingua dei segni cinese. Misurano le prestazioni usando il tasso di errore per parola, una metrica standard simile a quella usata nel riconoscimento vocale. Rispetto a un baseline che considera solo i movimenti delle mani, l’aggiunta delle informazioni sulla posa della testa riduce gli errori di circa 4 punti percentuali sui dati tedeschi e di 3–4 punti sui dati cinesi. L’inclusione del modulo di potenziamento delle feature apporta miglioramenti ancora maggiori, riducendo gli errori di circa il 10–14 percento complessivamente in entrambi i dataset. Il sistema funziona inoltre in modo efficiente, raggiungendo velocità real-time su una moderna GPU, aspetto cruciale se deve essere impiegato in interpretazione live o in strumenti mobili. 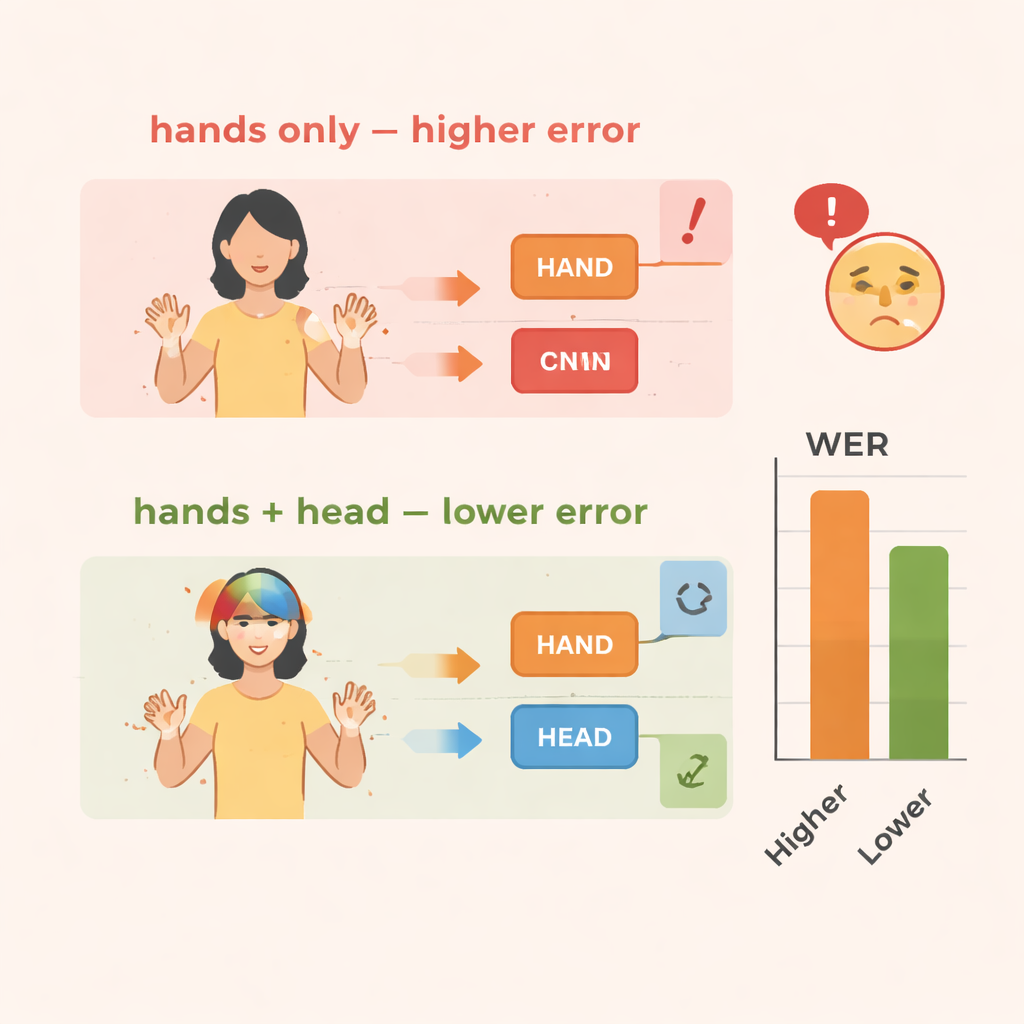
Cosa significa nella vita quotidiana
In termini concreti, questa ricerca dimostra che i computer possono comprendere la lingua dei segni in modo più affidabile quando osservano l’intero firmatario, non solo le mani. Modellando i movimenti della testa e i segnali facciali insieme ai movimenti delle mani, e raffinando con cura l’apprendimento da dati di addestramento limitati, il framework TS-CNN si avvicina a sistemi pratici che potrebbero assistere le persone sorde in scuole, ospedali e uffici pubblici. Per regioni come Ha’il, dove gli interpreti umani sono scarsi e i progetti tecnologici sono ancora in fase di sviluppo, un sistema del genere potrebbe infine favorire una comunicazione più inclusiva—aiutando a colmare il divario tra firmatari e udenti senza sostituire la ricca esperienza umana della firma stessa.
Citazione: Harrouch, H., Guesmi, H., Alalfy, H. et al. A dual-stream deep learning framework for continuous sign language recognition to enhance communication accessibility in the Ha’il region. Sci Rep 16, 7070 (2026). https://doi.org/10.1038/s41598-026-38912-x
Parole chiave: riconoscimento della lingua dei segni, deep learning, accessibilità, computer vision, interazione uomo–computer