Clear Sky Science · it
Un metodo di protezione della privacy dei dati per modelli di previsione delle malattie infettive con equilibrio tra velocità di addestramento e accuratezza
Perché la protezione dei dati sanitari è ancora importante
Ospedali e agenzie sanitarie si affidano ora all’intelligenza artificiale per prevedere focolai di influenza, COVID-19 e altre infezioni con giorni o settimane di anticipo. Queste previsioni possono orientare campagne vaccinali, il personale e la pianificazione delle emergenze. Tuttavia, gli stessi dettagli dei fascicoli dei pazienti che rendono accurate le previsioni sono anche estremamente sensibili. Normative e preoccupazioni pubbliche spesso impediscono di aggregare i dati fra istituzioni, indebolendo l’efficacia di questi modelli. Questo articolo presenta un metodo per addestrare sistemi di previsione delle malattie infettive di alta qualità mantenendo i dati di ogni ospedale sicuri e confinati in sede.
Apprendere da molti ospedali senza condividere cartelle cliniche
Gli autori si basano su una tecnica chiamata federated learning, in cui diversi ospedali addestrano insieme un modello di previsione condiviso. Anziché copiare i record grezzi dei pazienti su un server centrale, ogni struttura addestra il modello localmente e invia solo aggiornamenti numerici alle impostazioni interne del modello. Un server centrale combina questi aggiornamenti e ridistribuisce il modello migliorato. Questo ciclo si ripete molte volte. In teoria, il federated learning tutela la privacy perché le informazioni personali non lasciano mai la struttura. In pratica, però, attaccanti sofisticati possono talvolta dedurre dettagli sui dati sottostanti a partire dagli aggiornamenti condivisi, perciò sono necessarie ulteriori protezioni. 
Proteggere i numeri con crittografia intelligente
Per rafforzare la sicurezza, il gruppo utilizza la crittografia omomorfica—una forma di protezione digitale che permette di eseguire calcoli direttamente su numeri cifrati, senza mai vederli in chiaro. Gli schemi tradizionali di questo tipo sono molto sicuri ma notoriamente lenti e affamati di risorse, il che li rende difficili da applicare a modelli ampi e complessi come quelli basati su reti LSTM (Long Short-Term Memory). I ricercatori progettano uno schema ibrido che tratta in modo diverso le varie parti del modello. Le componenti più rivelatrici sono protette con una forma di crittografia forte ma pesante, mentre le parti meno sensibili usano una protezione più leggera e veloce. Inoltre, un programma casuale predefinito decide in quali round di addestramento le sedi inviano effettivamente aggiornamenti cifrati, permettendo di saltare comunicazioni ridondanti. I test mostrano che questa combinazione accelera l’addestramento di circa il 25% rispetto all’applicazione della crittografia pesante ovunque, mantenendo i dati protetti secondo solide assunzioni crittografiche.
Inviare solo gli aggiornamenti che contano davvero
Anche con una cifratura più intelligente, trasferire ogni piccola modifica del modello avanti e indietro tra le istituzioni spreca tempo e larghezza di banda. Gli autori propongono quindi una nuova regola di addestramento chiamata Data Selection–Distributed Selection Stochastic Gradient Descent (DS-DSSGD). Durante l’addestramento, l’algoritmo misura quanto cambia ciascuna parte del modello da un passo al successivo. Solo gli aggiornamenti che superano una soglia prefissata vengono trasmessi; le variazioni piccole e a basso impatto sono semplicemente ignorate. Contemporaneamente, l’algoritmo traccia quali punti dati sono responsabili dei cambiamenti più grandi e informativi. Questi record influenti vengono raccolti in un dataset raffinato usato per un giro finale di addestramento. Esperimenti su tre anni di segnalazioni reali di infezione della città di Yichang, combinati con trend di ricerca web locali, mostrano che DS-DSSGD riduce i tempi di addestramento di circa il 10% rispetto a diversi metodi standard, senza perdita significativa di accuratezza predittiva.
Una piattaforma pratica per la collaborazione sicura
I progressi tecnici contano solo se ospedali e laboratori possono effettivamente usarli. Per colmare questo divario, il team integra i loro metodi in un ambiente informatico reale chiamato Yi Shu Fang XDP Privacy Security Computing Platform. XDP gestisce l’intero percorso dei dati sanitari, dalla raccolta e pulizia all’analisi cifrata e alla condivisione dei risultati. Supporta strumenti familiari a statistici, bioinformatici e clinici, e permette a ricercatori di diverse istituzioni di collaborare all’interno di uno spazio di lavoro controllato senza mai scaricare i dati grezzi. All’interno di questa piattaforma, lo schema di crittografia ibrido e l’algoritmo DS-DSSGD funzionano come componenti plug-in, trasformando il quadro teorico in un sistema operativo. 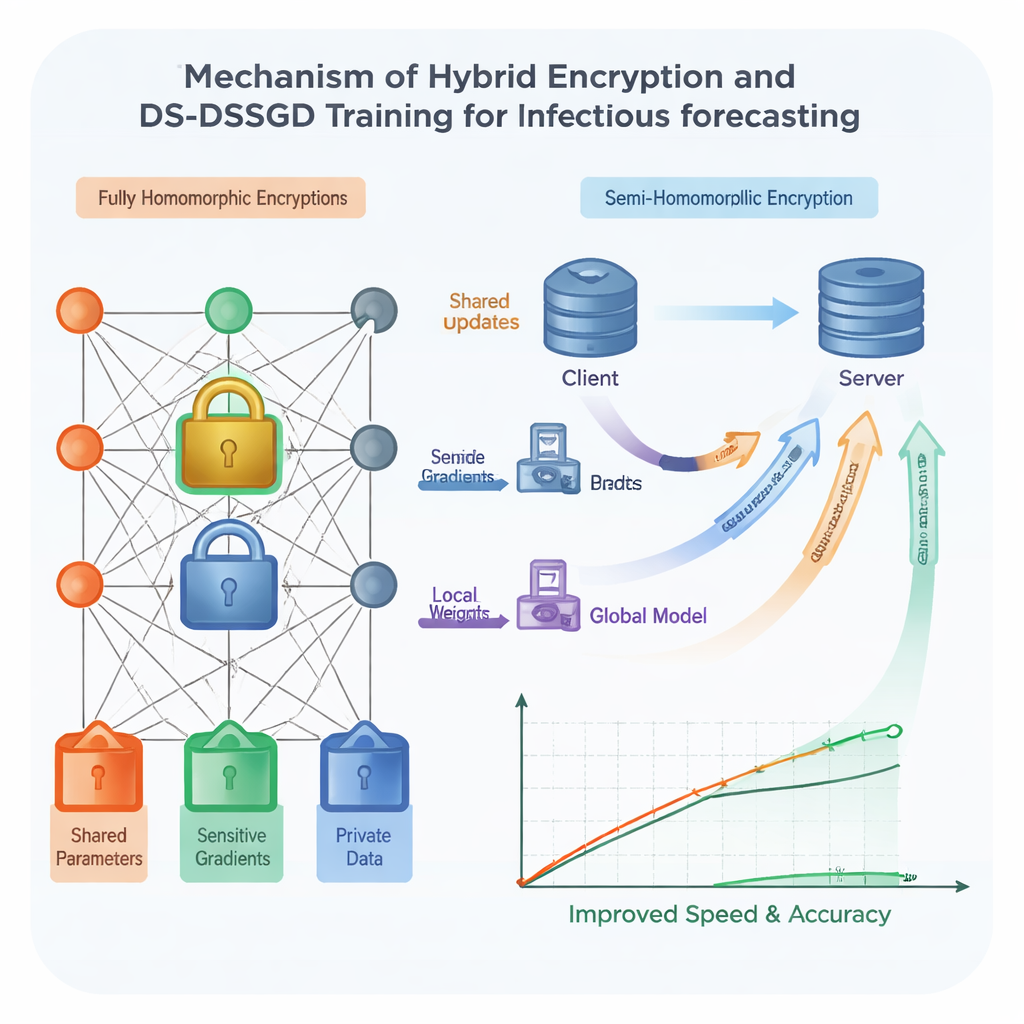
Cosa significa per la previsione dei futuri focolai
In termini concreti, questo studio dimostra che è possibile ottenere il «meglio di entrambi i mondi» per la previsione delle malattie infettive: proteggere la privacy dei pazienti mantenendo però la capacità di addestrare modelli veloci e accurati su dati provenienti da molte istituzioni. Crittografando diverse parti del modello con il livello di protezione adeguato, trasmettendo aggiornamenti solo quando necessario e racchiudendo il tutto in una piattaforma di collaborazione sicura, gli autori riducono il costo della privacy da un onere paralizzante a un sovraccarico gestibile. Se adottati su larga scala, tali approcci potrebbero permettere a ospedali e agenzie di sanità pubblica di mettere in comune le loro conoscenze contro la prossima epidemia senza mai esporre singoli fascicoli medici.
Citazione: Wang, X., Jiang, Y., Pan, G. et al. A data privacy protection method for infectious disease prediction models with balanced training speed and accuracy. Sci Rep 16, 7415 (2026). https://doi.org/10.1038/s41598-026-38906-9
Parole chiave: previsione delle malattie infettive, privacy dei dati sanitari, federated learning, crittografia omomorfica, deep learning