Clear Sky Science · it
Stima della comunezza e della prevalenza delle specie tramite metodi non supervisionati
Perché conta contare specie comuni e rare
Quando immaginiamo la natura in pericolo, pensiamo spesso ad animali rari sull’orlo dell’estinzione. Eppure la maggior parte del tessuto vivente intorno a noi è costituita da creature molto comuni o che scompaiono silenziosamente senza che nessuno se ne accorga. Sapere quanto una specie sia realmente diffusa in un luogo è essenziale per prevedere come gli ecosistemi risponderanno all’inquinamento, all’uso del suolo o ai cambiamenti climatici. Questo articolo presenta un metodo per stimare contemporaneamente quanto siano comuni o rare molte specie, usando solo record di avvistamento esistenti e moderne tecniche di analisi dei dati. L’obiettivo è fornire input più oggettivi ai modelli computazionali che prevedono dove le specie possono vivere oggi e in futuro.
Dai semplici avvistamenti a grandi questioni ecologiche
Gli ecologi usano routine di modellizzazione, chiamate modelli di nicchia ecologica, per determinare quali ambienti sono adatti a una specie. Questi modelli aiutano a prevedere dove una specie potrebbe presentarsi con il cambiamento climatico o in nuove regioni. Un ingrediente cruciale è la “prevalenza” – in termini semplici, la percentuale dei siti censiti in cui una specie è presente. Essa codifica se una specie è prevista come comune o rara prima di nuovi rilevamenti. Questa aspettativa a priori influisce fortemente su come i modelli trasformano i punteggi di idoneità in probabilità di presenza e su come tracciano i confini tra “presente” e “assente” su una mappa. Se la prevalenza è stimata male, specialmente per le specie rare, le previsioni possono essere fuorvianti e i piani di conservazione potrebbero concentrarsi sui luoghi sbagliati.
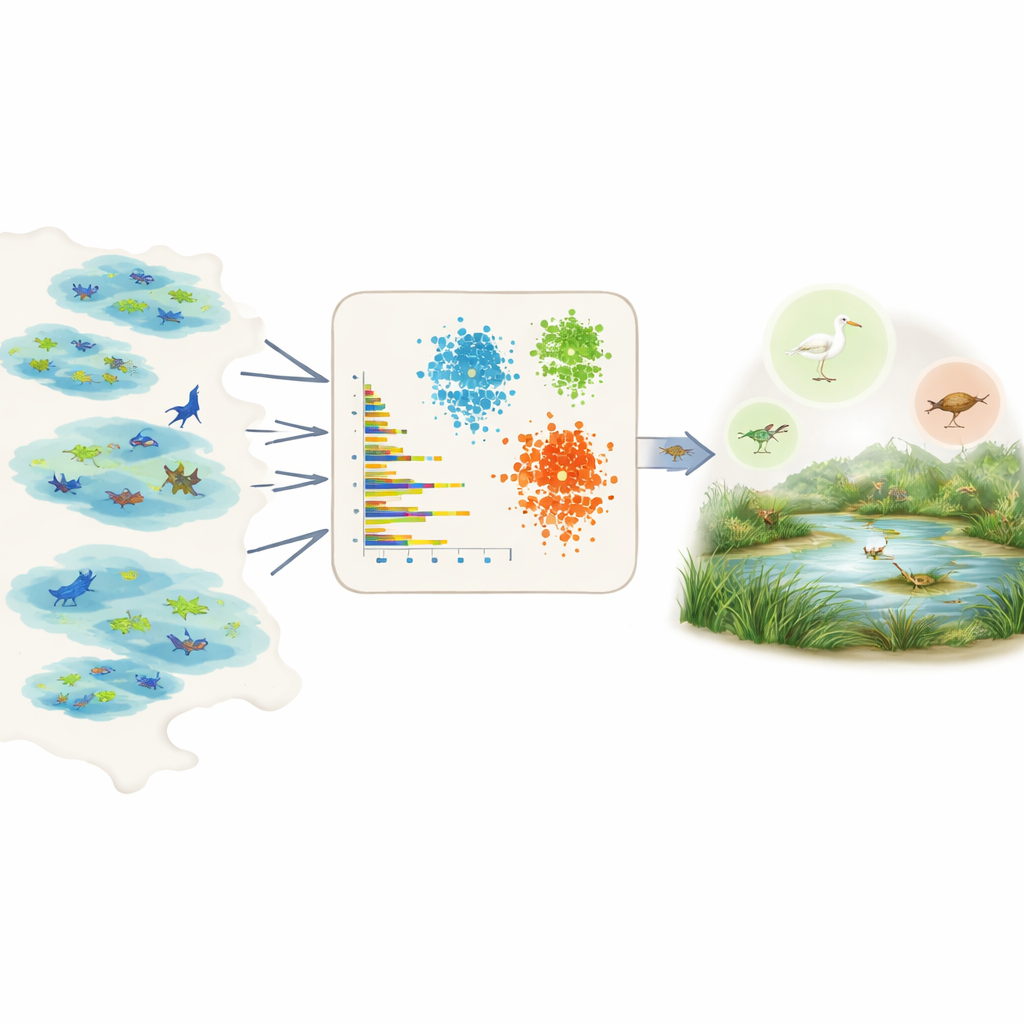
Lasciare che i dati parlino per centinaia di specie
Misurare direttamente la prevalenza è difficile perché i dati di campo sono frammentari e distorti. Alcune aree sono molto rilevate, alcune specie sono più facili da osservare e molti record provengono da progetti di citizen science con sforzi irregolari. Invece di affidarsi all’opinione di esperti o a conoscenze dettagliate per ogni specie, gli autori attingono al Global Biodiversity Information Facility, un enorme database aperto di osservazioni di specie. Per ogni specie in una regione scelta, sintetizzano i record grezzi in pochi numeri semplici e confrontabili: quanti individui vengono solitamente segnalati per avvistamento, in quante diverse banche dati o zone umide compare la specie, quanto è diffusa all’interno di quelle zone umide e con quale frequenza viene osservata nel tempo, incluse le ricorrenze di picchi di molte osservazioni.
Addestrare le macchine a distinguere specie comuni e rare
Con questi tratti riassuntivi a disposizione, il team applica tre strumenti di apprendimento non supervisionato – due metodi di clustering e un modello di deep learning noto come autoencoder variazionale – che cercano schemi senza essere informati in anticipo su quali specie siano comuni o rare. I metodi di clustering raggruppano specie che condividono simili livelli di abbondanza, diffusione e frequenza di osservazione. L’autoencoder impara cosa rappresenta un record tipico di una specie e segnala come anomalie i modelli inusuali, che spesso corrispondono a specie rare o poco osservate. I modelli assegnano quindi a ciascuna specie tre classi intuitive – molto comune, abbastanza comune o rara – e convertono queste classi in valori numerici di prevalenza che possono essere inseriti direttamente nei modelli di nicchia ecologica come probabilità a priori.
Testare l’approccio in una zona umida vulnerabile
Per valutare l’efficacia del quadro, gli autori si concentrano sul bacino del Lago di Massaciuccoli in Toscana, un’area palustre bassa ricca di uccelli, pesci, insetti e altri animali. Questo paesaggio è sia un hotspot di biodiversità sia una calamita per i turisti, ma è anche vulnerabile ai cambiamenti climatici, alla scarsità d’acqua e all’inquinamento. Per 161 specie animali legate al lago, i modelli sono stati addestrati usando record provenienti da altre zone umide italiane, per poi inferire quanto dovesse essere comune ciascuna specie a Massaciuccoli. Due esperti locali, con profonda esperienza sul campo nell’area, hanno valutato le stesse specie in modo indipendente. Confrontando i due giudizi, il modello di deep learning concordava con la visione combinata degli esperti per circa l’81–90 percento delle specie, mentre i metodi di clustering e un ensemble dei tre modelli hanno mostrato anch’essi buone prestazioni.
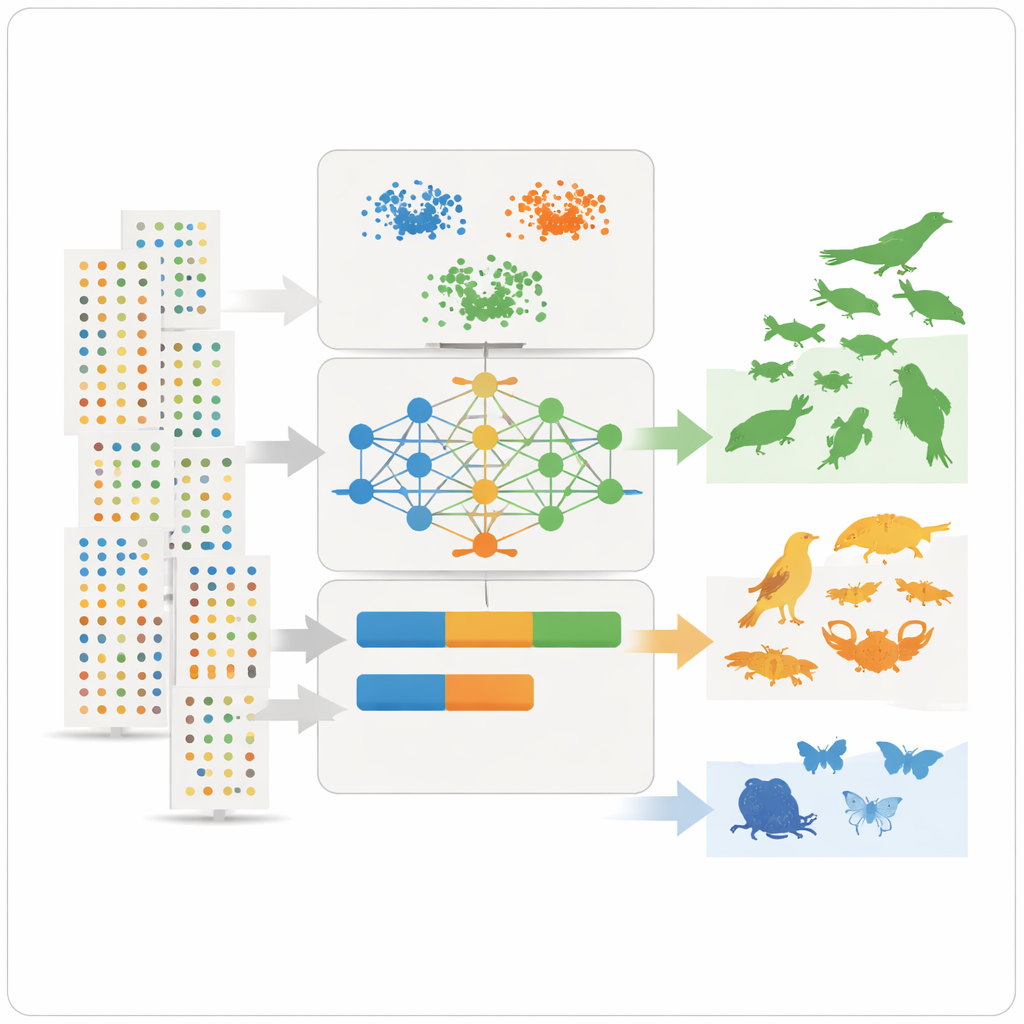
Imparare dai disaccordi e dai bias nascosti
Non tutti i casi coincidevano perfettamente. Alcune specie note dagli esperti come abbondanti intorno al lago risultavano rare nei dati, spesso perché sono elusive, sotto-segnalate o osservate con maggiore attenzione in alcune zone umide rispetto ad altre. Questo ha messo in luce un limite chiave: i grandi database riflettono dove e come la gente cerca la natura, non soltanto dove le specie si trovano realmente. Un’analisi di sensibilità ha mostrato quali caratteristiche erano più rilevanti per le classificazioni, con la media dei record per dataset, l’abbondanza per avvistamento e la coerenza delle osservazioni nel corso degli anni che emergono come particolarmente informative. Nonostante i bias residui, il metodo ha prodotto stime di prevalenza chiare e riproducibili e può essere tarato per usare classi più fini o più ampie a seconda delle esigenze di modellizzazione.
Cosa significa questo per le previsioni sulla natura
Per i non specialisti, il messaggio principale è che ora possiamo usare i dati di biodiversità esistenti in modo più intelligente per valutare quali specie sono probabilmente comuni, intermedie o rare in un dato contesto, senza dover regolare manualmente ogni singolo caso. Trasformando record di osservazione rumorosi in stime di prevalenza trasparenti e guidate dai dati, il quadro aiuta i modelli ecologici a produrre previsioni più realistiche sull’idoneità dell’habitat e sulle tendenze future della biodiversità. Ciò può a sua volta supportare una migliore pianificazione per zone umide come Massaciuccoli e per molti altri ecosistemi nel mondo, anche quando i dati di campo sono incompleti e il tempo degli esperti è limitato.
Citazione: Bove, P., Bertini, A. & Coro, G. Estimating species commonness and prevalence through unsupervised methods. Sci Rep 16, 8331 (2026). https://doi.org/10.1038/s41598-026-38900-1
Parole chiave: prevalenza delle specie, modellizzazione della biodiversità, ecosistemi palustri, machine learning in ecologia, comunezza delle specie