Clear Sky Science · it
Valutazione della relazione evolutiva della proteina legante la TATA (TBP) con vari schemi di ripiegamento dei domini proteici mediante support vector machine (SVM)
Come una proteina “interruttore” del DNA si collega a molte altre
La proteina legante la TATA, o TBP, è un elemento fondamentale delle nostre cellule: aiuta ad attivare i geni afferrando il DNA in molti promotori. Questo studio pone una domanda apparentemente semplice ma con grandi implicazioni: esistono altre proteine, con compiti molto diversi, che condividono silenziosamente la forma sottostante della TBP? Combinando il confronto di strutture 3D, l’analisi di sequenze e strumenti moderni di apprendimento automatico, gli autori tracciano legami familiari nascosti tra la TBP e proteine coinvolte nel metabolismo, nella chimica dei neurotrasmettitori e persino in vie correlate al cancro.
Una proteina chiave al centro del controllo genico
La TBP si trova alla porta dell’espressione genica in organismi che vanno dal lievito all’uomo. Riconosce una breve sequenza di DNA chiamata TATA box e piega il DNA per favorire l’assemblaggio del grande macchinario di trascrizione che copia i geni in RNA. Poiché questo passaggio è così centrale, il fold — l’organizzazione tridimensionale — del nucleo della TBP è altamente conservato nell’evoluzione. Gli autori si concentrano su una struttura della TBP ben studiata nota come 1tba e la usano come sonda per cercare altre proteine che possano condividere il suo progetto architettonico, anche se le loro sequenze aminoacidiche e le loro funzioni quotidiane appaiono molto diverse a prima vista.
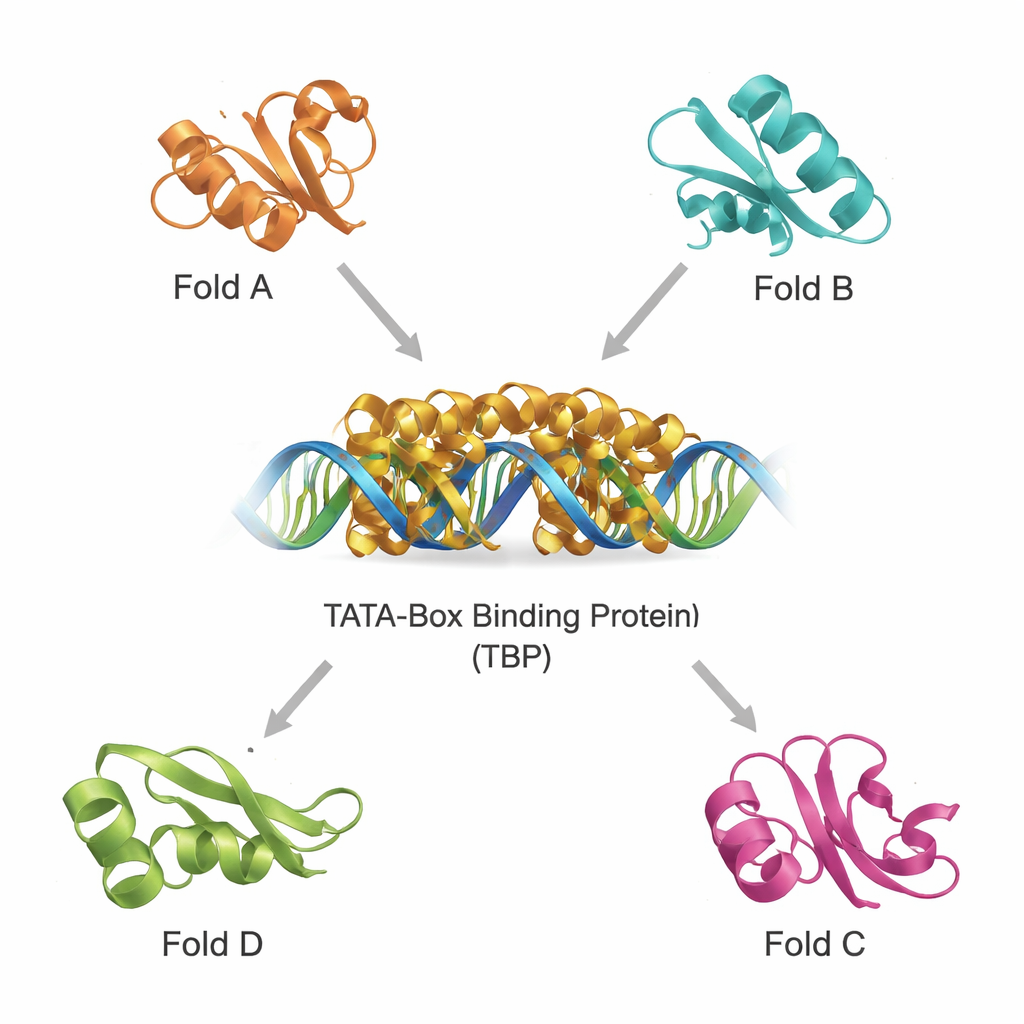
Trovare cugini strutturali in un universo proteico affollato
I database moderni contengono centinaia di migliaia di strutture proteiche, rendendo possibile scansionare parenti lontani per forma 3D piuttosto che solo per sequenza. Usando due potenti strumenti, DALI e TOP‑search, il team ha prima estratto proteine i cui fold somigliavano a quello della TBP. Hanno poi classificato questi candidati con un catalogo evolutivo di domini e li hanno ridotti a un piccolo insieme di esempi strutturalmente simili ma funzionalmente diversi. Tra questi figurano un enzima che sintetizza glutamina importante nel metabolismo, un dominio presente in diversi enzimi che trattano tRNA, un enzima con il caratteristico fold a “hot‑dog” coinvolto nella chimica degli acidi grassi, e proteine che partecipano alla produzione di tetraidrobiopterina, una molecola cruciale per la funzione cerebrale. Sovrapponendo le loro strutture a quella della TBP è emerso che, nonostante i diversi compiti, condividono motivi core riconoscibili.
Addestrare macchine a riconoscere famiglie proteiche nascoste
Per andare oltre l’ispezione caso per caso, gli autori hanno costruito modelli di apprendimento automatico in grado di segnalare automaticamente i fold simili alla TBP. Hanno assemblato grandi insiemi di sequenze proteiche note per appartenere alla TBP o a ciascuno dei fold correlati, insieme a un ampio insieme di “sfondo” di proteine non correlate. Ogni proteina è stata convertita in semplici riassunti numerici: la frequenza di ciascun amminoacido e la frequenza di ogni possibile coppia di amminoacidi nella sequenza. Questi profili sono stati usati per alimentare support vector machine (SVM) e modelli random‑forest, che hanno imparato a separare un tipo di fold da tutti gli altri. Usando una valida procedura di cross‑validazione, i modelli hanno raggiunto un’accuratezza molto elevata — spesso oltre il 95 percento — anche quando addestrati solo su parti delle sequenze corrispondenti a regioni conservate.
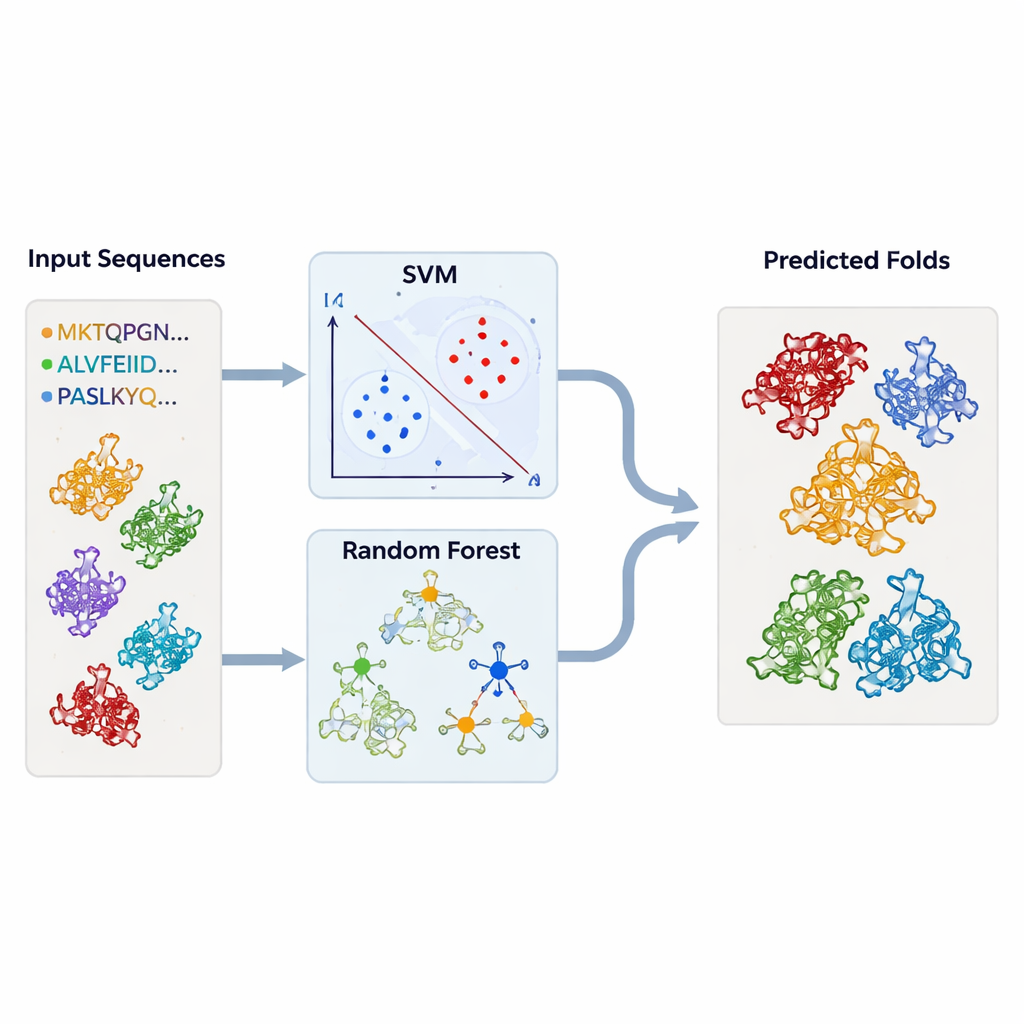
Testare i modelli su migliaia di strutture non caratterizzate
Muniti di questi classificatori addestrati, il team è tornato ai database strutturali. Hanno passato migliaia di catene proteiche — recuperate da DALI e TOP‑search — attraverso i loro modelli per vedere quali presentavano le impronte statistiche tipiche dei fold simili alla TBP o correlati. Gli approcci SVM e random‑forest sono risultati in larga misura concordi e hanno selezionato molti candidati che anche gli strumenti strutturali avevano indicato come simili. In alcuni casi, enzimi con attività apparentemente non correlate si sono comunque raggruppati saldamente con la TBP o tra di loro, rafforzando l’idea che l’evoluzione può riutilizzare lo stesso quadro di base per molti ruoli biochimici diversi.
Perché queste connessioni nascoste sono importanti
Lo studio conclude che la TBP condivide una profonda discendenza strutturale con diverse famiglie di enzimi, inclusi proteine simili alla glutammina sintetasi e domini di editing di enzimi che processano tRNA. Anche quando le sequenze si sono allontanate e le funzioni si sono diversificate, queste proteine conservano motivi architettonici comuni, suggerendo la discendenza da un antenato condiviso. Per un non specialista, il messaggio chiave è che la natura tende a riciclare progetti di successo: un singolo fold può essere adattato ripetutamente per risolvere problemi molto diversi, dall’attivazione dei geni alla regolazione fine del metabolismo e della chimica cerebrale. Combinando il confronto di strutture 3D con l’apprendimento automatico, gli autori forniscono un kit di strumenti pratico per scoprire tali relazioni, aiutando i biologi a prevedere la funzione di proteine non caratterizzate e indirizzando gli sviluppatori di farmaci verso nuovi target guidati dall’evoluzione in vie rilevanti per le malattie.
Citazione: Selvaraj, M.K., Kaur, J. Evaluating the evolutionary relationship of TATA binding protein (TBP) with various folding patterns of protein domains using support vector machine (SVM). Sci Rep 16, 7696 (2026). https://doi.org/10.1038/s41598-026-38883-z
Parole chiave: Proteina legante la TATA, evoluzione delle proteine, apprendimento automatico, struttura proteica, support vector machine