Clear Sky Science · it
Classificazione dei testi delle canzoni basata su reti profonde ibride adattive a cascata seriale usando un approccio di ottimizzazione
Perché filtri più intelligenti per le canzoni sono importanti
La musica entra nelle nostre vite quasi senza soluzione di continuità e gran parte di ciò che ascoltiamo è scelto da algoritmi. Eppure molti di questi sistemi faticano ancora a rispondere a una domanda semplice: cosa dicono davvero le parole di una canzone e a chi sono adatte? Questo articolo affronta il problema costruendo un modello avanzato di intelligenza artificiale (IA) che legge automaticamente i testi delle canzoni e li classifica per umore, genere, sentiment e perfino tipo di interprete. L’obiettivo è contribuire a creare playlist più sicure per i bambini, raccomandazioni basate sull’umore più accurate e strumenti migliori per i ricercatori musicali.
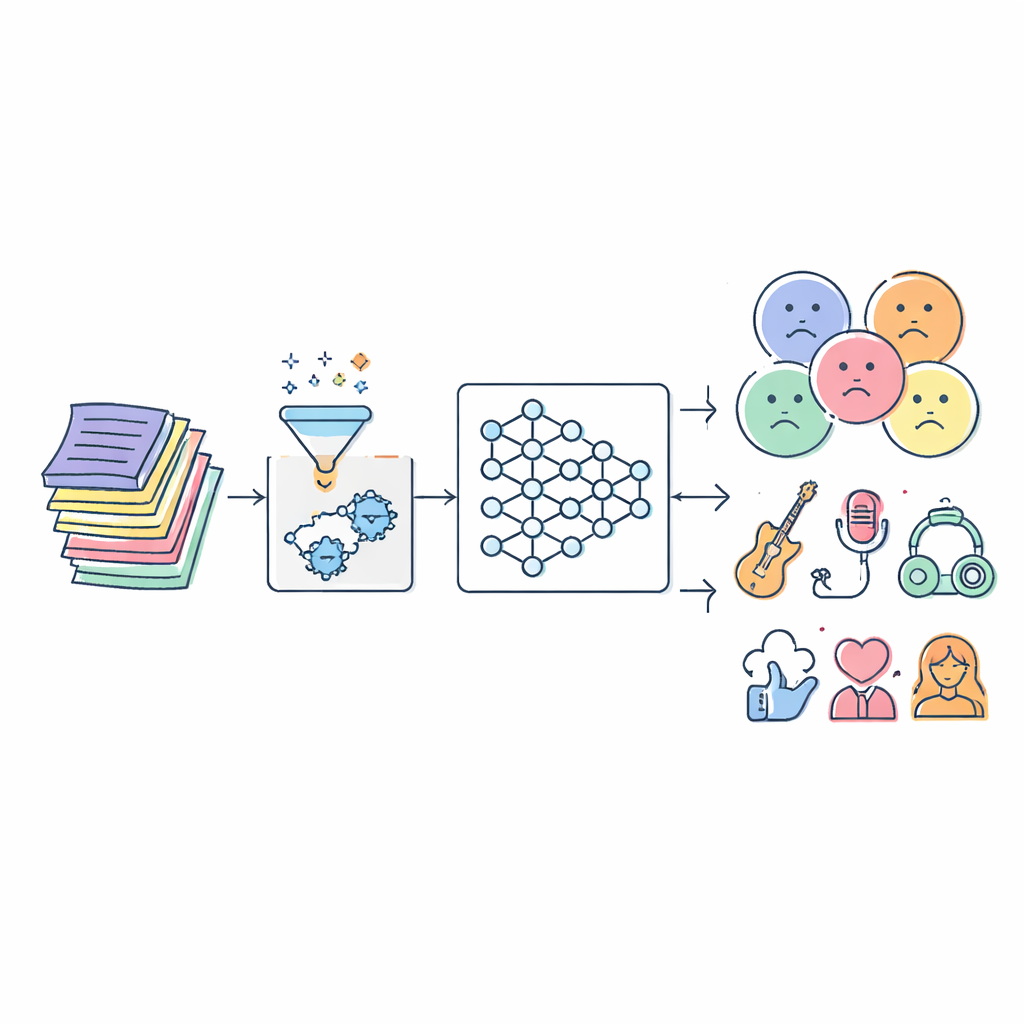
La sfida nascosta nelle parole delle canzoni
I testi sono molto più complessi di una lista di parole buone o cattive. La stessa frase può suonare tenera in una canzone e minacciosa in un’altra, e gli ascoltatori portano con sé esperienze personali che influenzano l’interpretazione. I filtri tradizionali si basano di solito su elenchi statici di termini offensivi o su semplici tecniche statistiche. Questi approcci perdono il contesto, non riescono a stare al passo con lo slang in evoluzione e spesso etichettano erroneamente i brani. Allo stesso tempo, l’esplosione della musica digitale significa che ci sono milioni di tracce da analizzare, in molte lingue e stili, il che sovraccarica la classificazione manuale e gli algoritmi più vecchi.
Ripulire i testi grezzi
Gli autori iniziano assemblando ampie raccolte di testi da tre dataset pubblici che, insieme, coprono centinaia di migliaia di canzoni in diversi generi e lingue. Prima che qualsiasi IA possa apprendere dal testo, i testi devono essere puliti. Il sistema rimuove punteggiatura, simboli speciali e frammenti ripetuti o irrilevanti, quindi riduce le forme correlate delle parole a una radice comune (per esempio, “cantando”, “canta” e “cantò” diventano tutti “cant”). Questa fase di pre-elaborazione elimina il rumore mantenendo il significato, così che le fasi successive possano concentrarsi sul tono emotivo e sui temi piuttosto che su stranezze di formattazione o variazioni ortografiche.
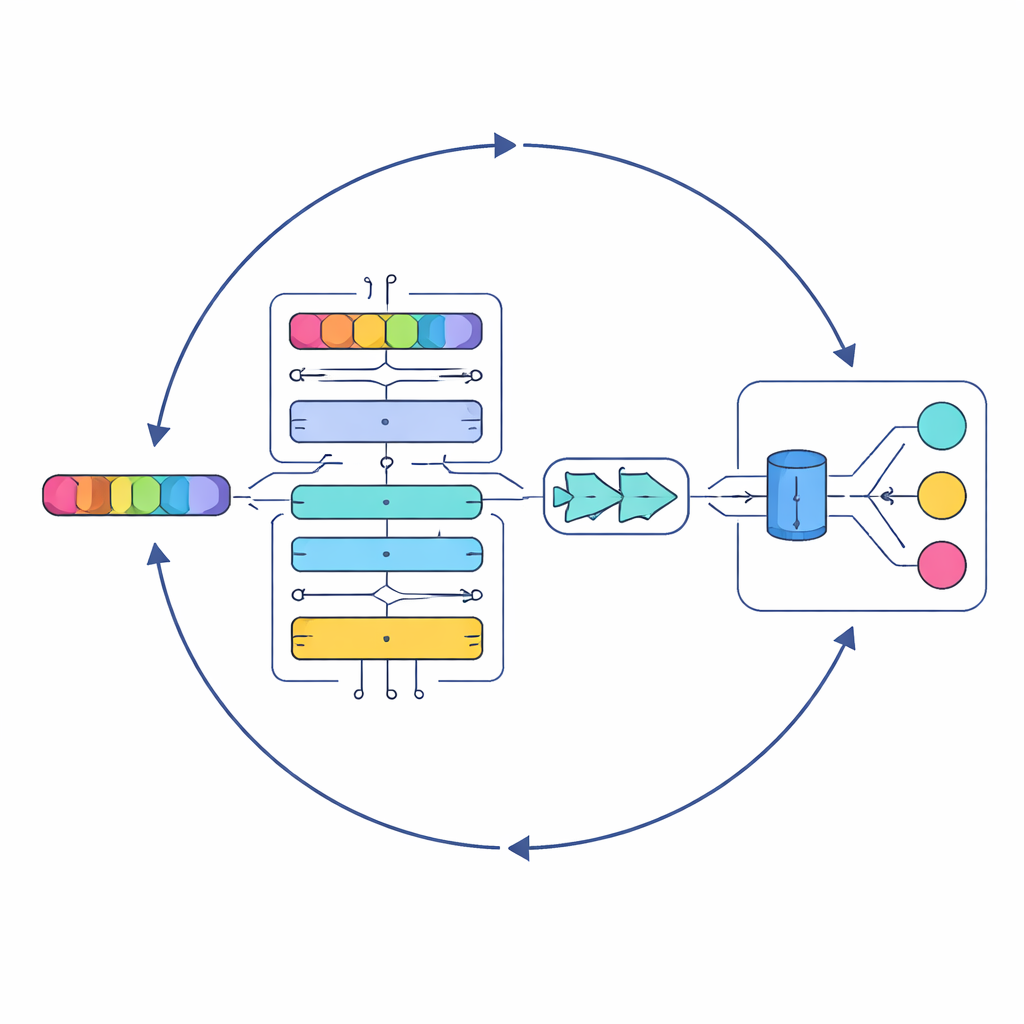
Un’IA stratificata che legge come un ascoltatore attento
Al centro dello studio c’è un nuovo modello chiamato Serial Cascaded Hybrid Adaptive Deep Network, o SCHADNet. Combina tre idee potenti dell’IA del linguaggio moderna. Primo, un encoder basato su transformer cattura come le parole si relazionano su tutto il testo, non solo tra vicini immediati. Secondo, uno strato bidirezionale Long Short-Term Memory legge il testo sia in avanti sia all’indietro nel tempo, aiutando il sistema a capire come le battute precedenti colorino il significato di quelle successive. Terzo, uno strato Gated Recurrent Unit affina queste informazioni in un riassunto compatto adatto alle decisioni finali. Insieme, questi componenti funzionano come un coro di lettori specializzati, ciascuno concentrato su aspetti diversi del testo della canzone.
Prendere in prestito una strategia dal mare
Limitarsi ad impilare strati di deep learning non è sufficiente; le loro impostazioni interne—come il numero di neuroni e la durata dell’addestramento—influiscono fortemente sulle prestazioni. Invece di ottimizzare manualmente queste scelte, gli autori adottano un approccio di ottimizzazione ispirato ai pattern di caccia dei predatori marini. Il loro Improved Marine Predators Algorithm (IMPA) esplora molte possibili combinazioni di parametri, avvicinandosi progressivamente a quelle che danno i risultati migliori. Eliminando parti dell’algoritmo originale che non contribuivano in questo contesto, migliorano la convergenza, ossia il sistema raggiunge soluzioni buone più rapidamente e in modo più affidabile.
Quanto bene funziona il sistema
I ricercatori testano SCHADNet con IMPA su tre diversi dataset di testi e lo confrontano con una serie di metodi consolidati, inclusi classificatori classici di machine learning e diversi modelli deep-learning popolari come LSTM semplice, sistemi basati solo su transformer e reti ibride. In termini di accuratezza, richiamo (quante canzoni davvero rilevanti vengono trovate) e altre misure di qualità, il nuovo approccio risulta costantemente superiore. Su un ampio dataset multilingue classifica correttamente circa il 93% delle canzoni e ottiene un valore predittivo negativo particolarmente alto, il che significa che è molto efficace nel riconoscere i testi che non appartengono a una categoria segnalata—cruciale per evitare blocchi e etichettature eccessive o errate.
Cosa significa per ascoltatori e creatori
Per un profano, il messaggio è semplice: gli autori hanno costruito un lettore dei testi più sfumato e affidabile. Invece di affidarsi a rozzi elenchi di parole, il loro sistema considera frasi intere, contesto e pattern attraverso ampie raccolte musicali, quindi assegna automaticamente etichette come umore, stile o idoneità per un pubblico giovane. Pur essendo il modello complesso e computazionalmente esigente, apre la strada a controlli parentali più intelligenti, playlist basate sull’umore più ricche e nuovi modi di studiare le tendenze nella musica popolare. Il lavoro futuro punta a ridurre la sua fame di dati e ad accelerare l’addestramento, ma anche nella sua forma attuale SCHADNet indica un futuro in cui le piattaforme musicali comprendono i testi quasi con la cura di un ascoltatore umano attento.
Citazione: Jasmine, R.L., Mukherjee, S., Robin, C.R.R. et al. Serial cascaded hybrid adaptive deep networks-based lyrics text classification using optimization approach. Sci Rep 16, 8527 (2026). https://doi.org/10.1038/s41598-026-38813-z
Parole chiave: raccomandazione musicale, analisi dei testi, classificazione del testo, apprendimento profondo, moderazione dei contenuti