Clear Sky Science · it
Migliorare il rilevamento delle frodi nelle sottoscrizioni tramite l’ensemble learning: il caso di Ethio Telecom
Perché la frode telefonica riguarda tutti
Ogni volta che facciamo una chiamata, inviamo un messaggio o usiamo i dati mobili, diamo per scontato che la bolletta rifletta ciò che abbiamo effettivamente consumato. Ma i criminali possono sfruttare le reti telefoniche aprendo linee con identità false, accumulando costi enormi non pagati e persino usando quelle linee per altri reati. Questo studio si concentra su Ethio Telecom, l’operatore nazionale etiope, e mostra come metodi avanzati basati sui dati possano individuare sottoscrizioni sospette molto più accuratamente degli strumenti tradizionali, contribuendo a mantenere i servizi telefonici accessibili e sicuri per milioni di utenti.
Il costo nascosto dei conti telefonici falsi
La frode da sottoscrizione avviene quando qualcuno si registra a un servizio telefonico con dati falsi o rubati e non intende pagare. A livello globale questa è una delle forme più dannose di frode nelle telecomunicazioni, costando all’industria decine di miliardi di dollari all’anno. Solo per Ethio Telecom, si stima che la frode sottragga circa un miliardo di dollari annuali, con le sottoscrizioni fasulle responsabili di circa il 40% di quella perdita. Oltre alla perdita di ricavi, queste linee possono essere usate per truffe, rivendita di chiamate internazionali o altre attività illecite, creando rischi sia per i clienti sia per la sicurezza nazionale.
Da regole artigianali a sistemi che apprendono dai dati
Come molti operatori, Ethio Telecom si è tradizionalmente affidata ad esperti che definivano regole fisse per segnalare comportamenti sospetti — ad esempio bloccare una linea dopo troppe chiamate internazionali in breve tempo. Questi sistemi basati su regole sono facili da comprendere ma faticano quando i frodatori cambiano tattica o quando i modelli di utilizzo sono complessi. Gli autori sostengono che il machine learning, che apprende i pattern direttamente dai dati passati, possa reagire più rapidamente e con maggiore sensibilità. Invece di dipendere da un singolo modello, esplorano metodi di “ensemble” che combinano più modelli, e metodi “adattivi” che si aggiornano continuamente con l’arrivo di nuovi dati.
Cosa hanno costruito i ricercatori partendo da registri reali di chiamate
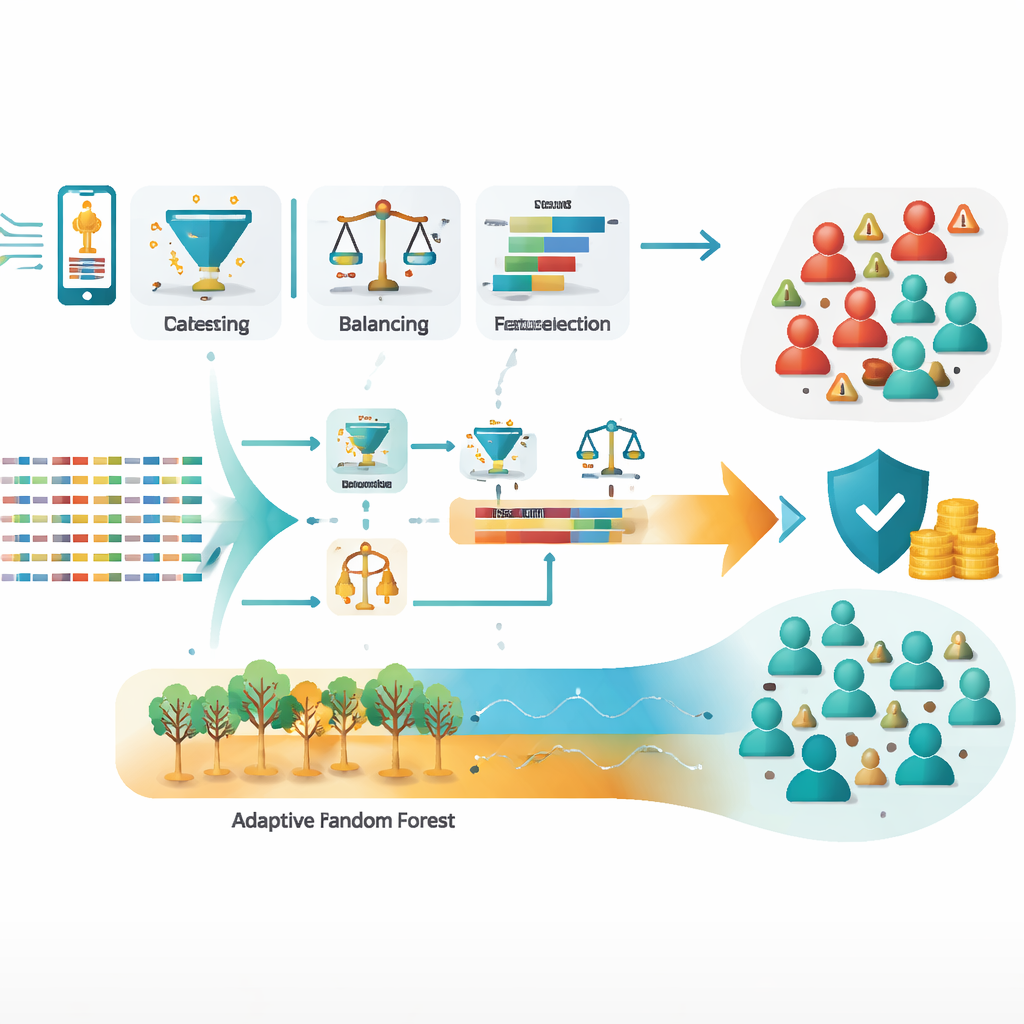
Il team ha lavorato su un ampio insieme di registri dettagliati delle chiamate — log di chi ha chiamato chi, per quanto tempo e in quali condizioni — relativi a un periodo di due mesi noto per un’intensa attività fraudolenta. Partendo da circa un milione di record grezzi, hanno pulito i dati, rimosso errori e duplicati, bilanciato classi fortemente sbilanciate (molti più utenti onesti che frodatori) e ingegnerizzato nuove feature che catturano meglio i comportamenti sospetti. Particolarmente importanti sono state misure come quante numerazioni internazionali ha composto un abbonato, la quota di chiamate internazionali sul totale e il rapporto tra numeri unici chiamati e chiamate totali. Questi segnali distillati spesso distinguono l’uso normale dall’abuso organizzato molto meglio di semplici conteggi o dati demografici.
Come la combinazione di modelli migliora il rilevamento
I ricercatori hanno testato tre modelli standard — alberi decisionali, regressione logistica e reti neurali artificiali — insieme a diverse strategie di ensemble come bagging (Random Forest), boosting (XGBoost), voting e stacking, oltre a modelli adattivi progettati per flussi di dati continui (Hoeffding Tree e Adaptive Random Forest). Dopo un’attenta messa a punto dei parametri di ciascun modello, l’approccio di stacking, che impara a fondere i punti di forza di più modelli di base, ha raggiunto circa il 99,3% di accuratezza su dati non visti. L’Adaptive Random Forest è stato quasi altrettanto performante, con circa il 99,2% di accuratezza, potendo inoltre adattarsi man mano che i pattern di frode cambiano nel tempo. Entrambi gli approcci hanno ridotto nettamente l’errore più pericoloso — non rilevare frodi reali — rispetto ai singoli modelli.
Tenere il passo con i trucchi che cambiano in tempo reale
Poiché i frodatori cambiano continuamente le loro metodologie, un modello statico può rapidamente diventare obsoleto. Per gestire questo problema, gli autori hanno usato una tecnica di selezione delle feature online che rivaluta continuamente quali segnali sono più importanti, senza dover ricostruire il sistema da zero. Sottolineano anche l’importanza della privacy: tutti gli identificatori personali nei dati sono stati anonimizzati prima dell’analisi e raccomandano rigorosi controlli di accesso e tracce di audit. Per un’implementazione pratica, lo studio delinea un’architettura in tempo reale in cui nuovi record di chiamata scorrono attraverso strumenti come Apache Kafka verso modelli adattivi che si aggiornano al volo monitorando al contempo per cambiamenti improvvisi nel comportamento.
Cosa significa tutto questo per utenti e fornitori telefonici
In termini semplici, lo studio dimostra che lasciare che più modelli intelligenti “votino” insieme e consentire loro di apprendere continuamente può catturare le sottoscrizioni false con un’accuratezza notevole mantenendo i falsi positivi a livelli gestibili. Per Ethio Telecom, questo potrebbe tradursi in risparmi sostanziali, prezzi più stabili e una protezione più forte contro l’uso criminale della rete. Per i clienti, significa che un utilizzo insolito ma legittimo è meno probabile che venga interpretato come frode, mentre le linee veramente a rischio vengono rilevate e chiuse più rapidamente. Gli autori concludono che l’ensemble e l’apprendimento adattivo, fondati su indicatori scelti con cura e contestualizzati, offrono un progetto potente e scalabile per il rilevamento moderno delle frodi nelle telecomunicazioni.
Citazione: Desta, E.A., Azale, K.W., Hailu, A.A. et al. Enhancing subscription fraud detection through ensemble learning the case of Ethio telecom. Sci Rep 16, 7867 (2026). https://doi.org/10.1038/s41598-026-38790-3
Parole chiave: frode nelle telecomunicazioni, frode da sottoscrizione, ensemble learning, random forest adattivo, registri dettaglio chiamate