Clear Sky Science · it
Predizione accurata e interpretabile della domanda chimica di ossigeno tramite algoritmi di boosting spiegabile con analisi SHAP
Perché osservare l’ossigeno di un fiume è importante
I fiumi sono l’elemento vitale di città e campagne, ma quando si riempiono di rifiuti organici provenienti da fabbriche, fognature o campi, l’acqua può restare priva di ossigeno e diventare pericolosa per le persone e gli ecosistemi. Un controllo comune dello stato di salute dei fiumi è la «domanda chimica di ossigeno» (COD), una misura di quanto ossigeno è necessario per decomporsi l’inquinamento. Misurare la COD in laboratorio è lento e costoso, dunque questo studio esplora se strumenti avanzati ma interpretabili di machine learning possano prevedere in modo affidabile la COD a partire da dati sensoriali di routine — e mostrare chiaramente cosa sta causando l’inquinamento. 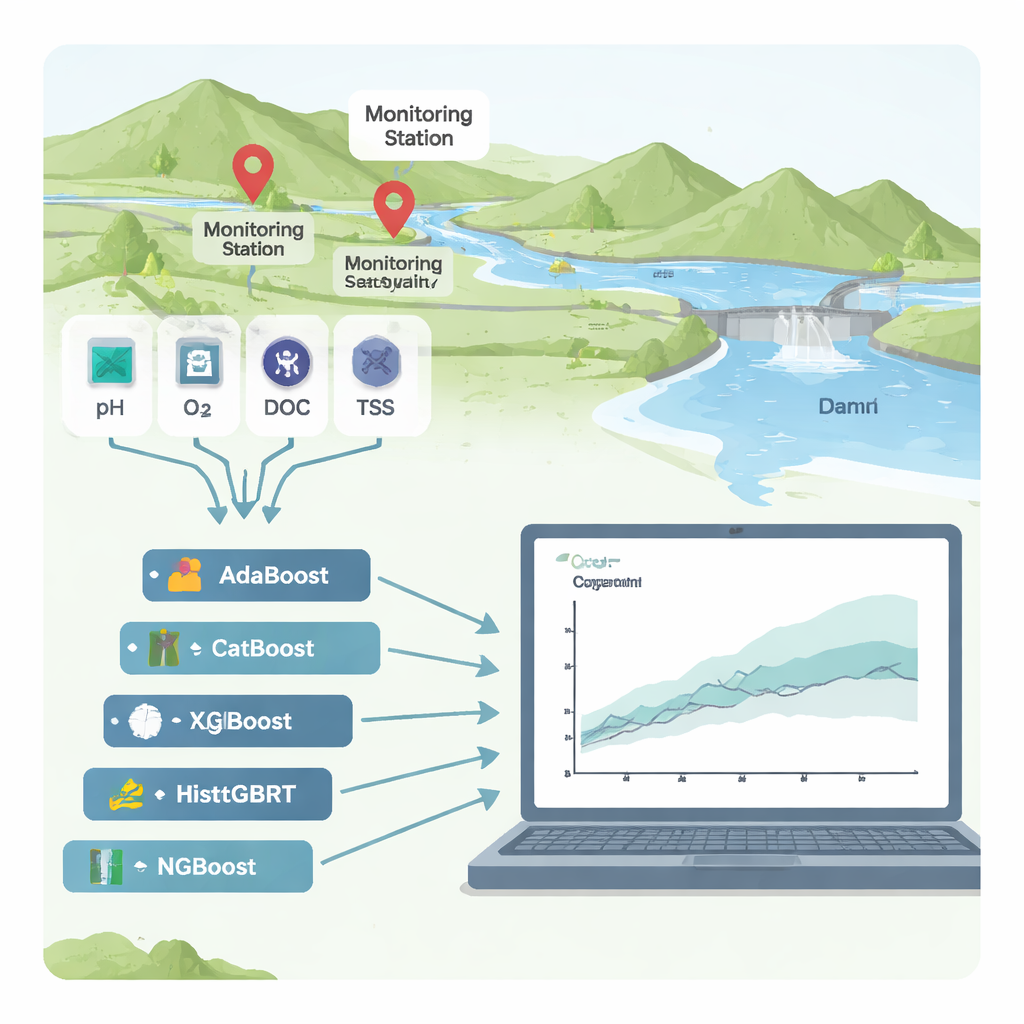
Modelli intelligenti per un mondo inquinato
I ricercatori si sono concentrati su due stazioni di monitoraggio fluviale in Corea del Sud, Hwangji e Toilchun, appena a monte della diga multifunzionale di Yeongju. In queste stazioni esistono decenni di registrazioni per indicatori comuni della qualità dell’acqua: acidità (pH), ossigeno disciolto, solidi sospesi (particelle fini nell’acqua), nutrienti come azoto e fosforo, carbonio organico totale (TOC), domanda biochimica di ossigeno (BOD₅), temperatura dell’acqua, conducibilità elettrica e portata del fiume. Invece di costruire un modello tradizionale basato sulla fisica — che può essere difficile da trasferire da un fiume all’altro — hanno testato sei algoritmi di “boosting”, una potente famiglia di metodi di apprendimento automatico che combinano molti alberi decisionali semplici in un predittore robusto.
Trovare il miglior “previsore” del fiume
Per confrontare i sei metodi di boosting (AdaBoost, CatBoost, XGBoost, LightGBM, HistGBRT e NGBoost), il team ha addestrato i modelli su circa il 70% dei dati storici e ha valutato le prestazioni sul restante 30%. Hanno giudicato l’accuratezza usando diverse statistiche che catturano quanto le previsioni siano vicine alle misurazioni reali della COD e quanto i modelli si generalizzino a condizioni non viste. Alla stazione di Toilchun, il modello NGBoost — che non prevede solo un valore singolo ma un’intera distribuzione di probabilità per la COD — è risultato il vincitore netto, catturando quasi tutta la variabilità della COD con errori molto piccoli. A Hwangji, sito più complesso, CatBoost ha offerto il miglior equilibrio tra accuratezza e stabilità. Alcuni modelli, in particolare XGBoost, sembravano quasi perfetti sui dati di addestramento ma hanno arrancato sui dati di test: un classico segno di «overfitting», quando un modello memorizza il rumore invece di apprendere pattern reali.
Aprire la scatola nera dell’IA
Un obiettivo centrale dello studio non era solo prevedere la COD, ma anche spiegare perché i modelli avevano fatto quelle previsioni. A questo scopo gli autori hanno usato SHAP (Shapley Additive Explanations), una tecnica che assegna a ogni variabile di input un contributo — positivo o negativo — a ciascuna previsione individuale. In entrambi i fiumi e nella maggior parte degli algoritmi, tre variabili sono emerse costantemente come i principali fattori determinanti della COD: carbonio organico totale (TOC), domanda biochimica di ossigeno (BOD₅) e solidi sospesi (SS). In termini semplici, più materiale organico e particelle fini ci sono nell’acqua, maggiore è la domanda di ossigeno. I modelli hanno anche rivelato differenze specifiche per sito: a Toilchun la portata e il fosforo totale hanno avuto un ruolo più marcato, suggerendo un’influenza maggiore di sorgenti diffuse come il deflusso agricolo; a Hwangji, i pattern nella conducibilità e nei solidi sospesi hanno indicato sorgenti più localizzate o industriali. 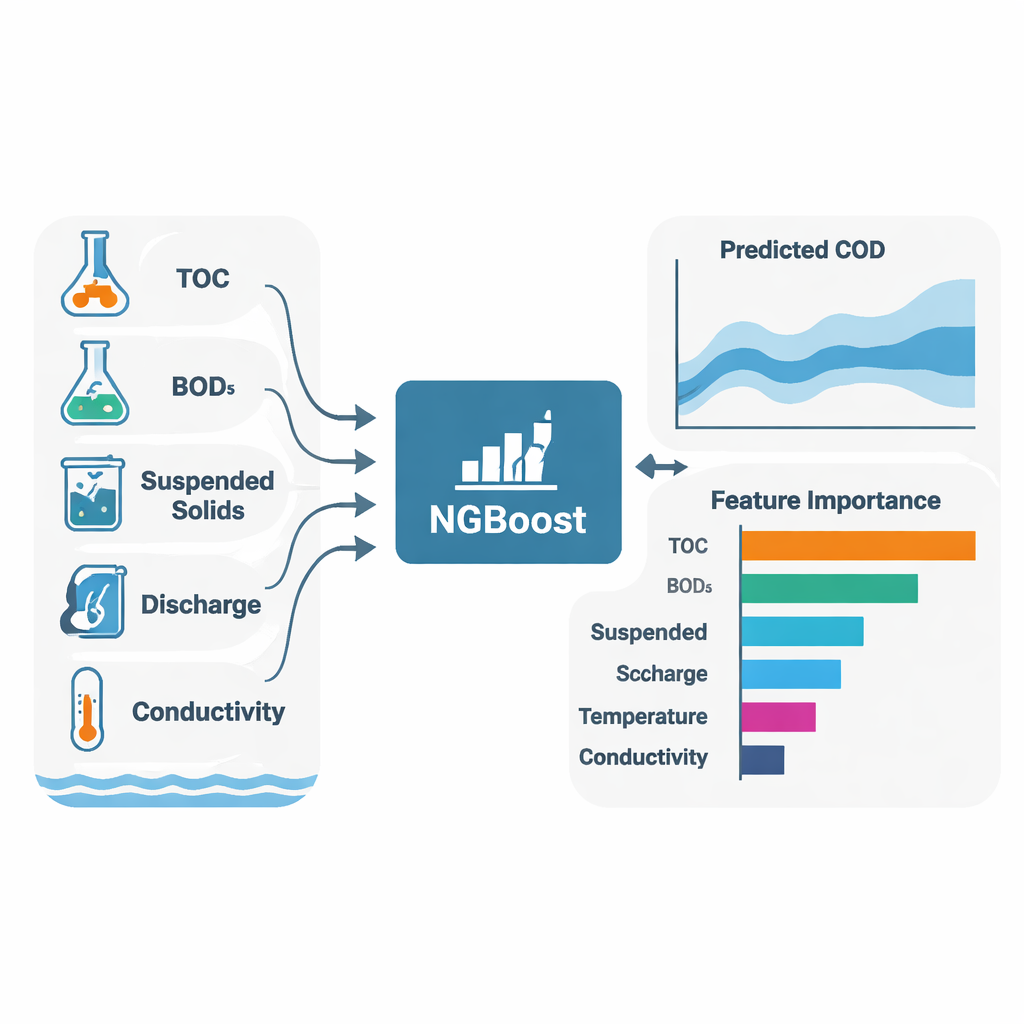
Cosa significano i risultati per i fiumi reali
Queste intuizioni dimostrano che i modelli di boosting, se accoppiati a SHAP, possono andare oltre il ruolo di opache «scatole nere». Forniscono sia previsioni precise della domanda di ossigeno dei fiumi sia una spiegazione coerente dal punto di vista fisico su cosa stia guidando l’inquinamento in ciascun sito. Questo è rilevante per i gestori di dighe e bacini fluviali che devono stabilire priorità su cosa monitorare e dove intervenire: se TOC e BOD₅ sono le leve più forti, allora controllare gli apporti di rifiuti organici può portare al miglioramento maggiore della qualità dell’acqua. Le previsioni probabilistiche di NGBoost forniscono inoltre una misura dell’incertezza, cruciale per i sistemi di allerta precoce e le decisioni basate sul rischio. In breve, lo studio dimostra che un’IA spiegabile e progettata con cura può contribuire a proteggere i serbatoi d’acqua potabile e la vita acquatica trasformando le letture dei sensori di routine in previsioni affidabili e trasparenti della salute dei fiumi.
Citazione: Merabet, K., Kim, S., Heddam, S. et al. Accurate and interpretable prediction of chemical oxygen demand using explainable boosting algorithms with SHAP analysis. Sci Rep 16, 6359 (2026). https://doi.org/10.1038/s41598-026-38757-4
Parole chiave: qualità dell'acqua, domanda chimica di ossigeno, apprendimento automatico, inquinamento dei fiumi, IA spiegabile