Clear Sky Science · it
Valutazione delle prestazioni di grandi modelli linguistici negli esami di reumatologia in persiano: accuratezza e ragionamento clinico di GPT-4o vs. GPT-5.1
Perché questo è importante per medici e pazienti
L’intelligenza artificiale sta rapidamente entrando nelle aule e nelle cliniche mediche, ma la maggior parte dei test su questi strumenti riguarda l’inglese. Questo studio pone una domanda che interessa milioni di parlanti persiano: come se la cavano i chatbot avanzati, in particolare GPT‑4o e GPT‑5.1, con domande complesse di esame di reumatologia scritte in persiano? La risposta aiuta educatori, specializzandi e pazienti a comprendere dove questi strumenti possono supportare in sicurezza l’apprendimento e dove rimane essenziale l’esperienza umana.
Mettere l’IA alla prova
I ricercatori hanno raccolto 204 domande a scelta multipla dagli esami ufficiali del Board di Reumatologia iraniano del 2023 e 2024, gli stessi esami che gli specialisti devono superare per essere certificati. Dopo aver eliminato sette domande difettose, sono rimaste 197 voci utilizzabili. Ogni domanda, comprese eventuali immagini o grafici allegati, è stata inserita in persiano in GPT‑4o e GPT‑5.1 in chat separate e nuove. Ai modelli è stato chiesto di scegliere la risposta migliore e di spiegare il loro ragionamento, rispecchiando il modo in cui uno specializzando potrebbe interrogare uno strumento di IA durante lo studio.
Verificare risposte e ragionamento
La performance è stata valutata in due modi. Primo, le opzioni scelte dai modelli sono state confrontate con la chiave di risposta ufficiale, producendo una semplice misura di accuratezza corretto/errato. Secondo, sei reumatologi con certificazione di board hanno valutato indipendentemente la qualità di ciascuna spiegazione su una scala di cinque punti, da ragionamento chiaramente errato a ragionamento completo e clinicamente solido. Le risposte di ciascun modello sono state valutate da due reumatologi diversi, che erano in cieco rispetto alle valutazioni reciproche e alla chiave di risposta ufficiale. Questo ha permesso ai ricercatori di osservare non solo se l’IA “indovinava” la risposta giusta, ma anche se la sua logica somigliava a quella degli specialisti.
Come si è comportato il modello più recente
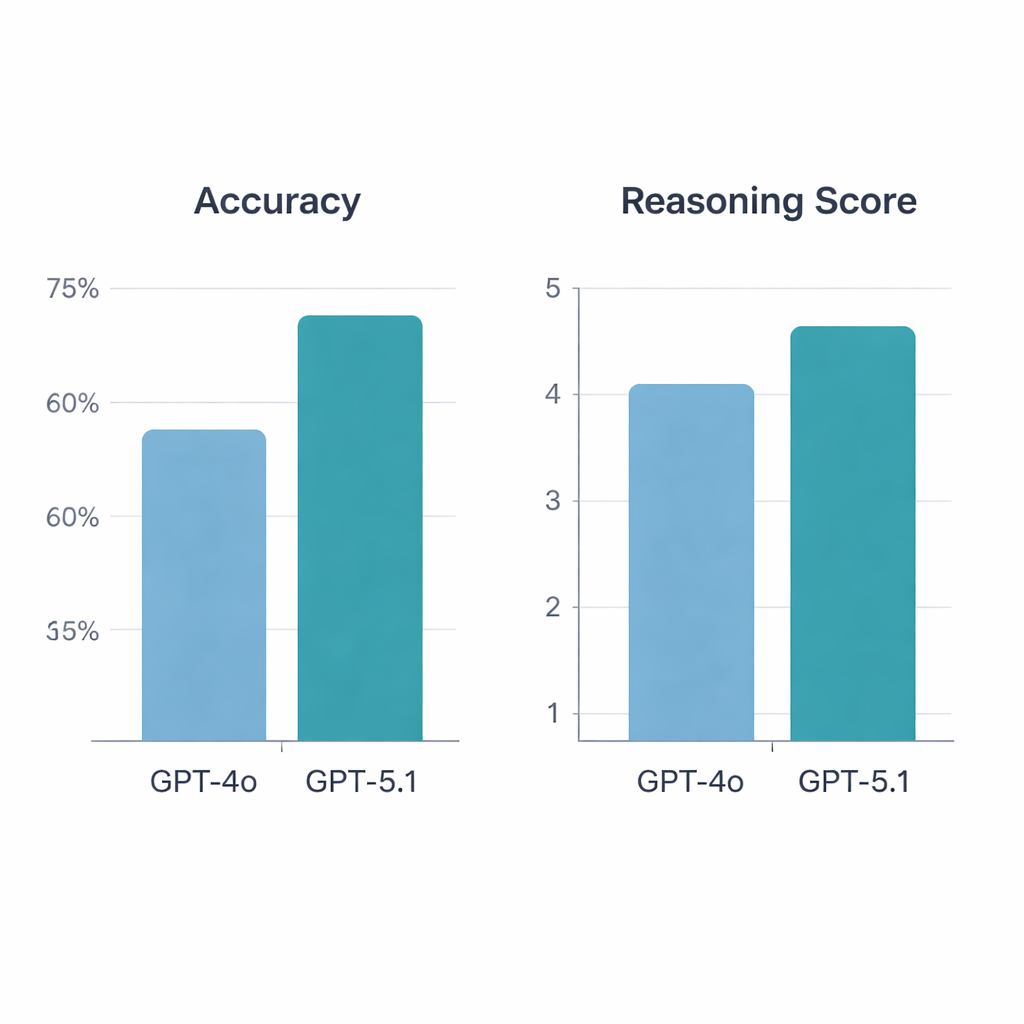
GPT‑5.1 ha chiaramente superato GPT‑4o. Sulle 197 domande valide, GPT‑4o ha risposto correttamente al 64,5%, mentre GPT‑5.1 ha raggiunto il 76% di accuratezza — un incremento statisticamente significativo. Entrambi i modelli hanno risposto correttamente a 113 domande e ne hanno sbagliate 34, ma GPT‑5.1 ha risolto da solo 36 domande aggiuntive che GPT‑4o aveva mancato; GPT‑4o è stato corretto in via esclusiva solo su 13 quesiti. Quando i reumatologi hanno valutato le spiegazioni, GPT‑5.1 si è confermato superiore, con un punteggio medio di ragionamento di 4,47 su 5 rispetto a 4,13 per GPT‑4o, ottenendo anche più valutazioni al punteggio massimo. Diversamente da GPT‑4o, la cui qualità di ragionamento variava a seconda che la domanda riguardasse scienza di base, casi clinici, diagnosi o trattamento, GPT‑5.1 ha mantenuto una performance più uniforme attraverso tutte le categorie.
Punti di forza, lacune e disaccordi umani
Lo studio ha messo in luce sfumature importanti. Anche quando la risposta finale di un modello era sbagliata, gli specialisti talvolta hanno giudicato il suo ragionamento abbastanza coerente, evidenziando un divario tra la valutazione d’esame e il pensiero clinico del mondo reale. Allo stesso tempo, l’accordo tra i valutatori reumatologi è risultato solo modesto, sottolineando che gli stessi clinici non sempre concordano su cosa costituisca un “buon ragionamento”. Anche la lingua sembra contare: lavori precedenti in inglese e spagnolo hanno riportato punteggi più alti per modelli simili, suggerendo che l’IA gestisce ancora meglio le principali lingue mondiali rispetto al persiano. Gli autori sottolineano che questi chatbot possono generare spiegazioni convincenti che possono mascherare errori fattuali e che le loro prestazioni possono cambiare con gli aggiornamenti dei sistemi.
Cosa significa per il futuro
Per i lettori non specialisti, il messaggio è che la generazione più recente di chatbot IA sta migliorando nella gestione di esami specialistici medici in persiano, ma non è pronta a sostituire una formazione rigorosa o il giudizio esperto. GPT‑5.1 può essere un utile compagno di studio per gli specializzandi in reumatologia — riassumendo argomenti, guidando nell’analisi di casi e offrendo spiegazioni strutturate — ma non dovrebbe essere considerato l’ultima istanza per decisioni ad alto rischio su diagnosi o trattamento. Gli autori chiedono studi più ampi e multilingue, test ripetuti nel tempo e simulazioni cliniche realistiche per determinare come integrare in sicurezza questi strumenti nell’istruzione medica e, in prospettiva, nella cura quotidiana dei pazienti.
Citazione: Rafiei, F., Sadeghipour, S., Sheikhalishahi, S. et al. Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1. Sci Rep 16, 7274 (2026). https://doi.org/10.1038/s41598-026-38716-z
Parole chiave: reumatologia, formazione medica in persiano, grandi modelli linguistici, ragionamento clinico, esami di abilitazione