Clear Sky Science · it
Rete di fusione multi-livello guidata dall'entropia per il recupero di immagini basato sul contenuto ad alta precisione
Trovare l'immagine giusta, in fretta
Ogni giorno creiamo e archiviamo un numero impressionante di foto — dalle scansioni mediche e immagini satellitari alle riprese di sorveglianza e agli scatti personali. Etichettare e cercare manualmente queste immagini è lento e poco affidabile. Questo articolo presenta un modo più intelligente per far “guardare” direttamente le immagini ai computer e trovare quelle desiderate con alta precisione, anche in raccolte molto grandi e variegate.
Perché guardare solo i pixel non basta
La ricerca di immagini tradizionale spesso si basa su nomi di file o tag semplici come “gatto” o “edificio”. Ma le persone non etichettano sempre le immagini con cura, e i computer vedono solo pixel grezzi, non il significato ricco che gli umani attribuiscono. I sistemi basati sul contenuto precedenti cercavano di colmare questo divario usando indizi visivi semplici come colore, texture e forma. Questi indizi aiutavano, ma venivano di solito combinati con livelli di importanza fissi. Ciò significa che il sistema trattava alcune caratteristiche come sempre più importanti di altre, anche quando una ricerca particolare avrebbe beneficiato di una combinazione diversa. Di conseguenza, la precisione soffriva quando cambiavano i tipi di immagine, l’illuminazione o le scene.
Fondere molti modi di vedere
Gli autori propongono un nuovo framework di recupero che fonde due principali tipi di evidenza visiva. Innanzitutto usa modelli di deep learning — reti ben conosciute come ResNet50 e VGG16 — che hanno imparato a riconoscere pattern complessi nelle immagini. In secondo luogo, aggiunge descrittori “artigianali” classici che catturano distribuzioni di colore, bordi e texture in modo più controllato. Invece di presumere in anticipo quanto debba contare ogni tipo di caratteristica, il sistema lascia che siano i dati a decidere. Valuta quanto informativa è ciascuna caratteristica per una data ricerca e ne regola l’influenza dinamicamente. Questa fusione multi-livello di indizi di alto e basso livello aiuta il computer a formare una comprensione più ricca e flessibile di ciò che è presente in un’immagine.
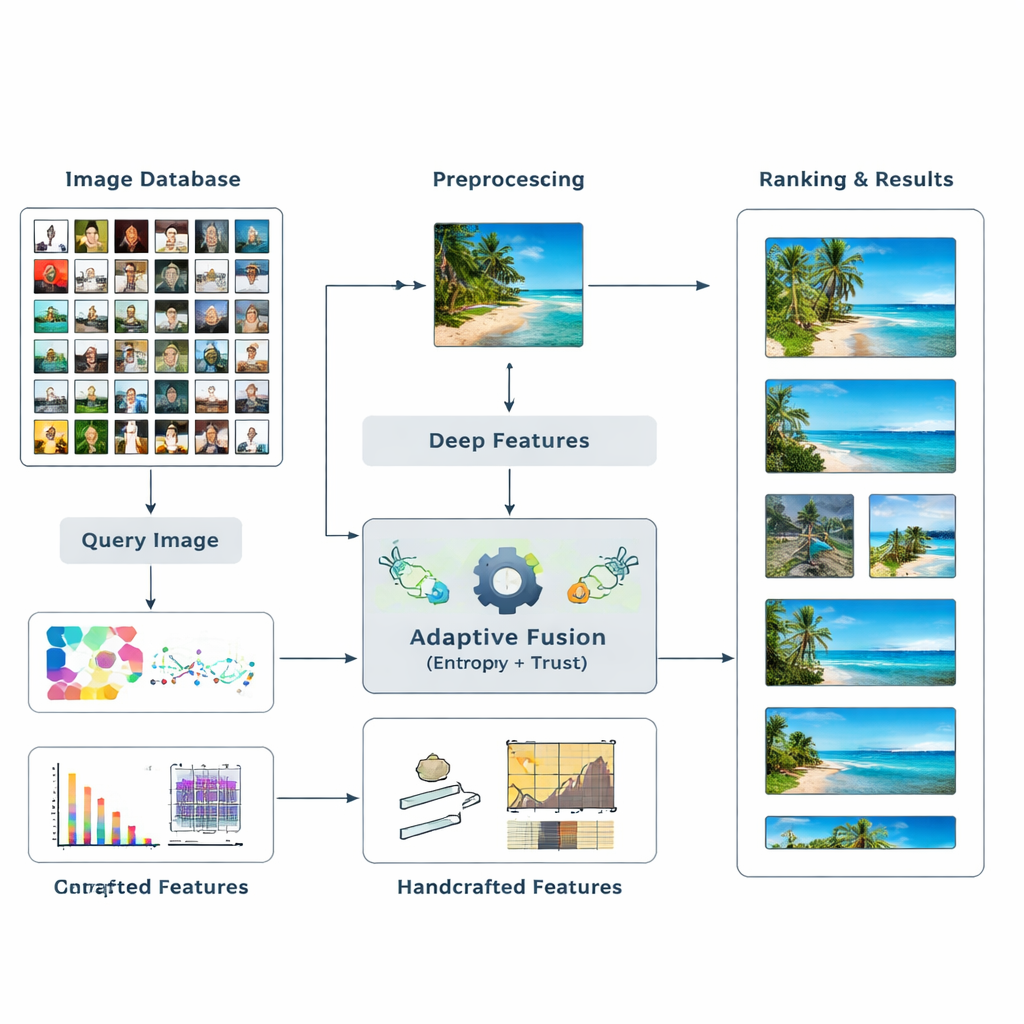
Lasciare che informazione e fiducia fissino i pesi
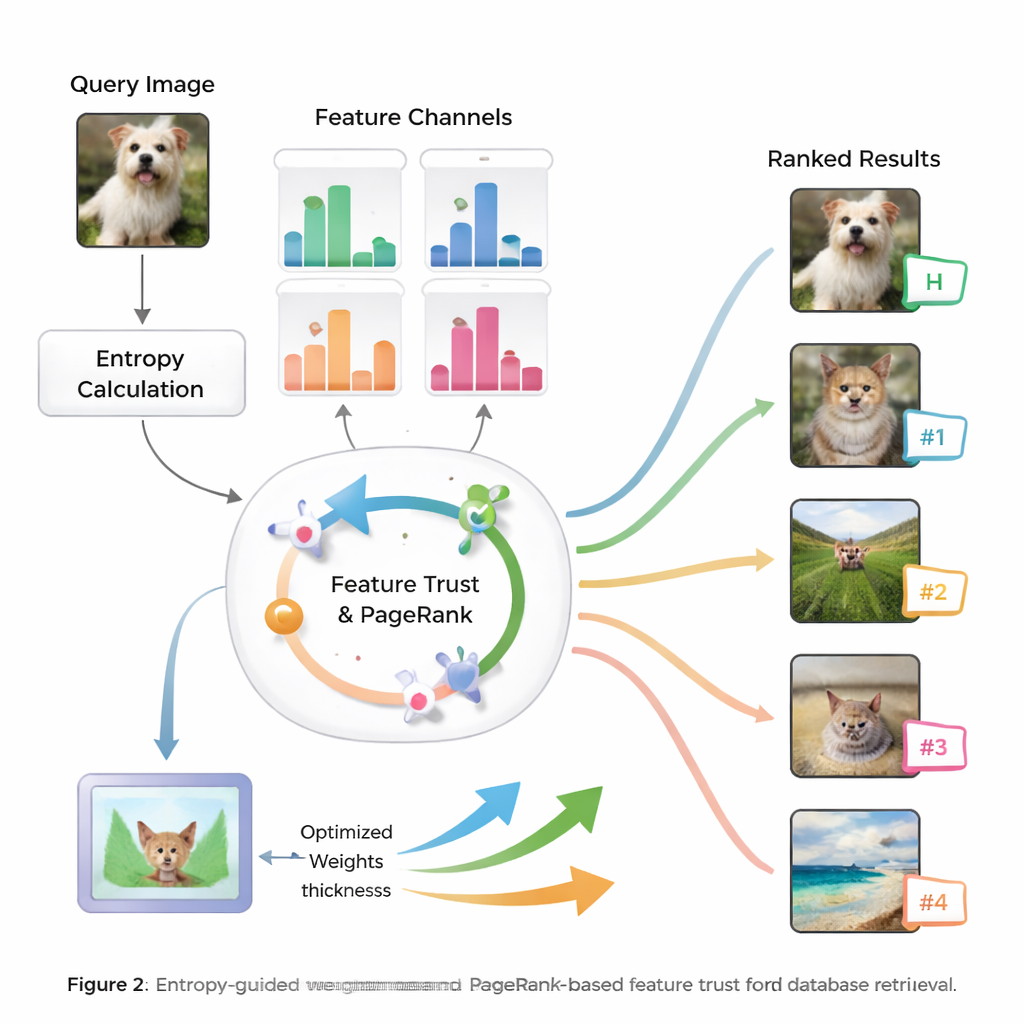
Al centro del metodo c’è l’idea di entropia, una misura di quanto l’informazione sia incerta o distribuita. Le caratteristiche che separano costantemente immagini rilevanti da irrilevanti hanno entropia più bassa e sono trattate come più “discriminative”. Per una nuova query, il sistema valuta come si comporta ogni caratteristica attraverso il database e le assegna un punteggio di importanza iniziale. Poi esamina quanto siano affidabili i risultati di ricerca di ciascuna caratteristica — se le corrispondenze in cima corrispondono davvero alla query — costruendo una nozione di “fiducia” per ogni tipo di indizio. Questi punteggi di fiducia vengono inseriti in un processo simile a PageRank, analogo a come i primi motori di ricerca web decidevano quali pagine fossero più importanti, per raffinare i pesi delle caratteristiche tramite una rete di trasferimento di probabilità.
Da pesi intelligenti a ranking migliori
Una volta che il sistema ha appreso quanto fidarsi di ogni caratteristica per la query corrente, combina i loro punteggi di similarità in una misura complessiva per ogni immagine del database. Le immagini vengono quindi ordinate in base a questo punteggio comprensivo, in modo che quelle che corrispondono alla query nei modi più significativi risalgano in cima. Gli autori testano il loro approccio su benchmark di immagini ampiamente usati e lo confrontano con diversi metodi esistenti. Riportano incrementi fino all’8,6% nella mean average precision e miglioramenti notevoli nella qualità dei primi dieci risultati, sia in accuratezza sia nella rilevanza dell’ordinamento. Test statistici mostrano che questi miglioramenti difficilmente sono dovuti al caso, suggerendo che il sistema è sia accurato sia stabile su molti tipi di immagini.
Cosa significa questo per la ricerca di immagini di tutti i giorni
In parole semplici, questa ricerca mostra come realizzare motori di ricerca di immagini che si adattano a ogni interrogazione invece di fare affidamento su regole rigide. Lasciando che il contenuto informativo e la fiducia guadagnata decidano quali indizi visivi contano di più, il sistema può trovare più spesso le immagini giuste, sia che si tratti di individuare un’impronta digitale in un enorme database criminale, localizzare un edificio specifico in fotografie satellitari o recuperare la scansione medica corretta. Gli autori riconoscono che il metodo è computazionalmente più pesante rispetto ai sistemi più semplici, ma sostengono che la sua maggiore affidabilità e precisione lo rendono adatto a repository di immagini ampi e critici, dove trovare l’immagine giusta è davvero importante.
Citazione: Lavanya, M., Vennira Selvi, G., Gopi, R. et al. Entropy guided multi level feature fusion network for high precision content based image retrieval. Sci Rep 16, 7449 (2026). https://doi.org/10.1038/s41598-026-38699-x
Parole chiave: recupero di immagini basato sul contenuto, deep learning, fusione delle caratteristiche, ricerca di immagini, pesi basati sull'entropia