Clear Sky Science · it
Pre-addestramento su ImageNet e apprendimento per trasferimento in due fasi nella classificazione delle immagini cromosomiche
Visioni più nitide dei nostri cromosomi
I nostri cromosomi contengono le istruzioni per costruire e far funzionare i corpi, e i medici osservano la loro forma per individuare disturbi genetici e alcuni tumori. Oggi i computer possono aiutare a interpretare le immagini dei cromosomi, ma insegnare loro a farlo bene è difficile perché le immagini mediche sono scarse e molto diverse dalle foto di tutti i giorni. Questo studio pone una domanda semplice dal grande impatto pratico: i computer possono imparare meglio da immagini mediche correlate, invece che solo da enormi raccolte di foto di gatti, cani e auto?
Perché le immagini dei cromosomi sono importanti
Negli ospedali gli specialisti dispongono i 46 cromosomi di una persona in una mappa chiamata cariotipo, raggruppati in 24 tipi (22 coppie numerate più X e Y). Sottili bande chiare e scure lungo ogni cromosoma aiutano a rivelare pezzi mancanti o in più legati a condizioni come la sindrome di Down o certe leucemie. Tradizionalmente gli esperti classificano queste bande a occhio, un processo lento e soggettivo. Il deep learning offre un modo per automatizzare il lavoro, ma questi sistemi spesso partono da modelli addestrati su ImageNet, un enorme dataset di immagini quotidiane. Quel salto—da foto vacanziere a viste al microscopio dei cromosomi—è enorme, e non è chiaro quanto quell’esperienza si trasferisca davvero.
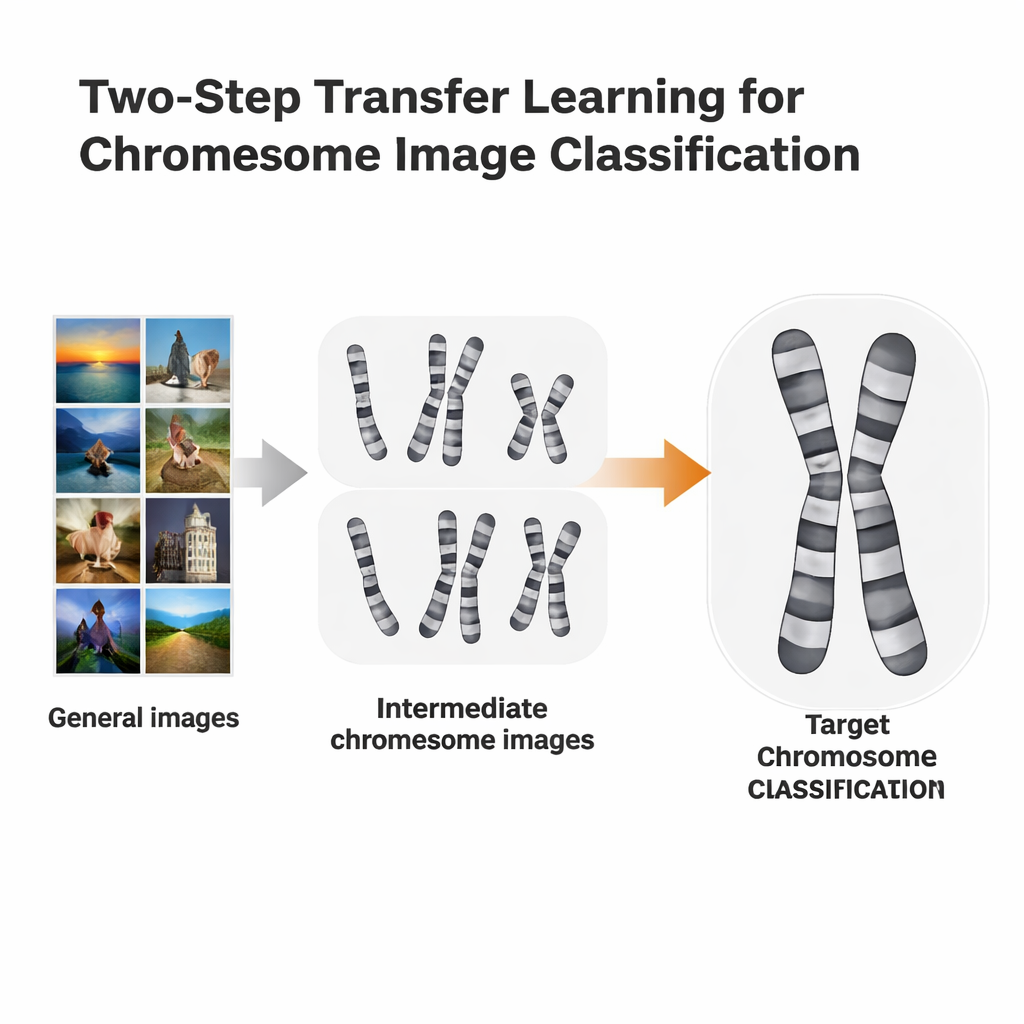
Un percorso di apprendimento in due fasi
I ricercatori hanno testato una via di addestramento più mirata chiamata apprendimento per trasferimento in due fasi. Invece di passare direttamente da ImageNet a un compito cromosomico specifico, hanno prima rifinito modelli addestrati su ImageNet con immagini cromosomiche ottenute con un metodo di colorazione, poi hanno effettuato una seconda rifinitura su un metodo leggermente diverso. Hanno usato due dataset aperti: immagini Q-band, di qualità inferiore e più difficili da leggere, e immagini G-band, più pulite e dettagliate. Ogni dataset ha fatto a turno il ruolo di «tappa intermedia» per l’altro. L’idea è simile all’apprendimento delle lingue: se già conosci lo spagnolo, può essere più facile imparare l’italiano che partire direttamente dall’inglese.
Testare molti “occhi” informatici
Per capire quando questo passo aggiuntivo aiuta, il team ha addestrato 66 classificatori diversi, combinando 11 architetture neurali popolari con tre strategie: partire da zero, rifinire solo da ImageNet e usare il trasferimento in due fasi. Hanno misurato le prestazioni con la Macro-F1, una score che tratta equamente tutti i tipi cromosomici, compresi quelli rari. Prima hanno confermato che le immagini Q-band e G-band sono statisticamente più simili tra loro che non a foto di ImageNet, il che le rende promettenti come tappe intermedie. Poi hanno confrontato quanto bene i diversi modelli imparavano con ciascuna strategia su entrambi i dataset, il più facile (G-band) e il più difficile (Q-band).
Quando il passo in più ripaga
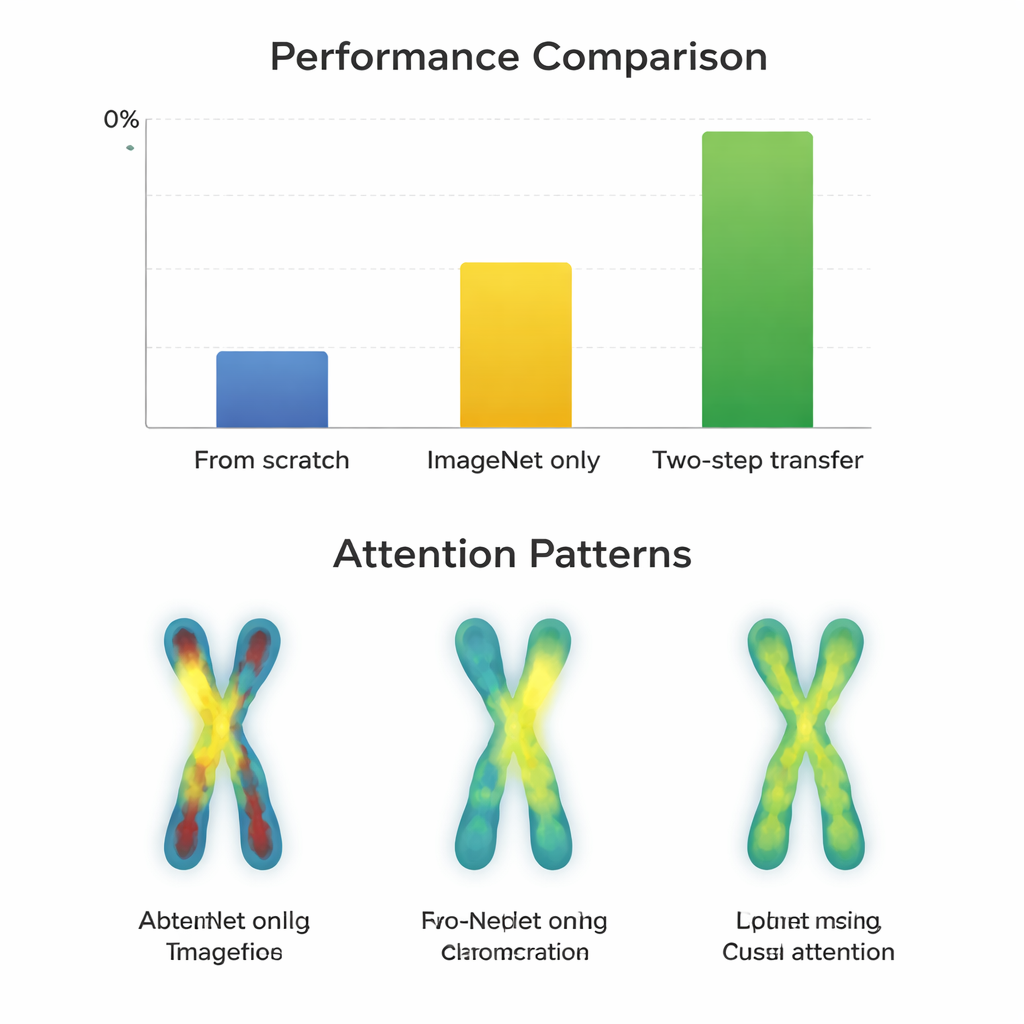
Sulle immagini G-band, di qualità superiore, quasi tutti i modelli avevano già prestazioni eccellenti dopo la semplice rifinitura da ImageNet, con punteggi intorno al 97–98 percento. Qui il doppio passaggio di addestramento ha portato solo piccoli miglioramenti—spesso meno di un punto percentuale—and talvolta ha penalizzato architetture più datate. Al contrario, sulle immagini Q-band più impegnative la situazione è cambiata. Architetture moderne e compatte come ConvNeXt, Swin Transformer, Vision Transformer e MobileNetV3 hanno tratto un chiaro beneficio dal percorso in due fasi, migliorando di circa 0,8–3,3 punti percentuali rispetto a ImageNet da solo. Mappe visive di dove i modelli «guardavano» hanno spiegato il motivo: con il trasferimento in due fasi le reti si concentravano in modo più uniforme lungo le bande dei cromosomi su entrambi i bracci, invece di fissarsi solo sui contorni o su una singola regione. Tuttavia reti molto grandi e più vecchie, come VGG, non hanno tratto vantaggio e in alcuni casi sono peggiorate, suggerendo che un progetto più intelligente può battere la sola grandezza.
I limiti imposti dai dati
I ricercatori hanno anche esaminato gli errori sulle immagini G-band. Alcuni insuccessi non derivavano dalla strategia di apprendimento ma da input difettosi, come cromosomi tagliati male durante la separazione di forme sovrapposte. In questi casi tutte le metodologie di addestramento hanno faticato, e le mappe di attenzione risultavano disperse o fissate su bordi fuorvianti. Questo mette in evidenza un messaggio pratico per cliniche e sviluppatori: nemmeno la migliore pipeline di addestramento può superare completamente una scarsa qualità delle immagini o errori di preprocessing, soprattutto quando si lavora con dataset di dimensioni modeste come quelli disponibili per l’imaging cromosomico.
Cosa significa per la diagnosi nella pratica
Per i non specialisti, il punto chiave è che il riutilizzo intelligente di immagini mediche correlate può rendere la lettura automatica dei cromosomi più accurata—soprattutto quando i dati target sono rumorosi o scarsi e quando si usano reti neurali moderne e ben progettate. Per immagini di alta qualità, l’addestramento standard basato su ImageNet può già essere sufficiente. Ma quando i patologi lavorano con dataset più difficili, un passo di apprendimento in più usando un tipo di immagine strettamente correlato può affinare il «viso» del computer, portando le prestazioni nella fascia del 93–98 percento. Questo approccio potrebbe estendersi oltre i cromosomi a molte aree dell’imaging medico dove i dati annotati sono limitati, aiutando a rendere gli strumenti di IA affidabili più prossimi alla pratica clinica quotidiana.
Citazione: Chen, T., Xie, C., Zhang, W. et al. ImageNet pre-training and two-step transfer learning in chromosome image classification. Sci Rep 16, 7572 (2026). https://doi.org/10.1038/s41598-026-38662-w
Parole chiave: classificazione dei cromosomi, IA per l'imaging medico, apprendimento per trasferimento, modelli di deep learning, cariotipo