Clear Sky Science · it
FedSCOPE: Raccomandazione sequenziale federata cross-dominio con apprendimento contrastivo decoupled e miglioramento semantico preservante la privacy
Perché raccomandazioni più intelligenti e più sicure sono importanti
Ogni volta che sfogli film, fai acquisti online o leggi recensioni, i sistemi di raccomandazione decidono silenziosamente cosa mostrarti dopo. Man mano che la nostra vita digitale si diffonde su molte app e siti, quei sistemi potrebbero funzionare molto meglio se potessero imparare da tutte le tue attività contemporaneamente—senza mai esporre i tuoi dati privati. Questo articolo presenta FedSCOPE, un nuovo modo per piattaforme diverse di collaborare alle raccomandazioni che sono sia più accurate sia più rispettose della privacy degli utenti.
I problemi degli engine di raccomandazione odierni
La maggior parte dei sistemi di raccomandazione attuali risiede all’interno di una singola app o sito web e vede solo una fetta ristretta del tuo comportamento. Questo significa che faticano con utenti “cold-start” che hanno poca storia, o con prodotti di nicchia con cui poche persone interagiscono. Quando le aziende cercano di combinare dati tra domini—come libri e film, o cibo e utensili da cucina—si imbattono in tre grandi problemi: i dati sono spesso sparsi, le piattaforme hanno tipi di utenti e attività molto diversi, e regole di privacy rigorose rendono rischioso aggregare dati grezzi in un unico luogo. Soluzioni semplici, come aggiungere la stessa quantità di rumore preservante la privacy per tutti, tendono o a indebolire la protezione o a danneggiare gravemente l’accuratezza.
Lasciare che i modelli linguistici colmino le lacune
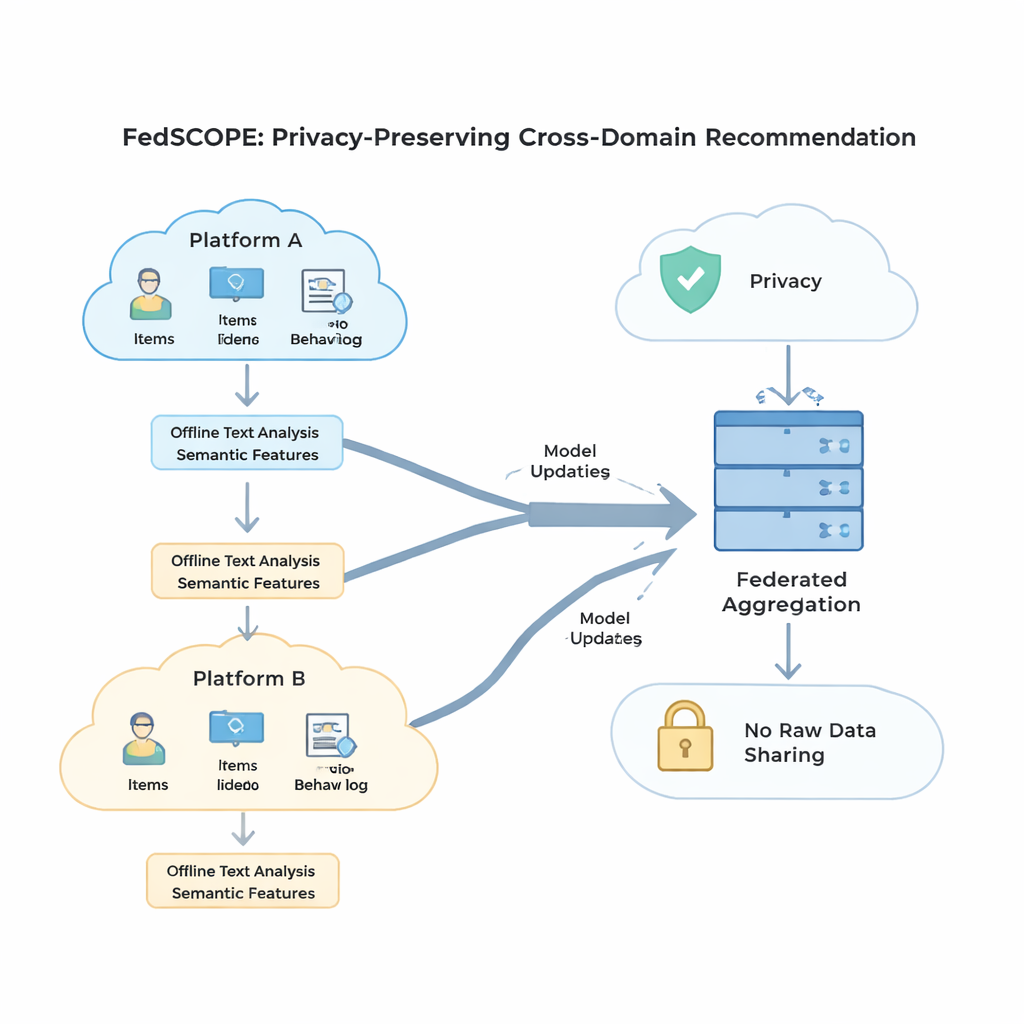
FedSCOPE affronta il problema della scarsità dati facendo sì che ogni piattaforma arricchisca i propri dati usando un grande modello linguistico (LLM), ma in modo insolito e attento alla privacy. Invece di inviare le storie utente a un servizio AI remoto durante ogni raccomandazione, ogni client esegue un processo offline una tantum: fornisce titoli e informazioni di base sugli oggetti (per esempio nome e genere di un film) a un LLM e chiede descrizioni strutturate, come temi probabili, abitudini di visione o interessi correlati. Questi attributi generati restano sul dispositivo o server locale e vengono fusi con le usuali cronologie di clic e visualizzazioni mediante una rete neurale leggera. Questo dà al sistema una rappresentazione più ricca sia degli utenti sia degli oggetti, particolarmente utile quando le interazioni registrate sono poche. Poiché il processo è offline e locale, i comportamenti grezzi non lasciano mai la piattaforma e non c’è dipendenza continua da servizi AI esterni.
Separare ciò che è personale da ciò che è condiviso
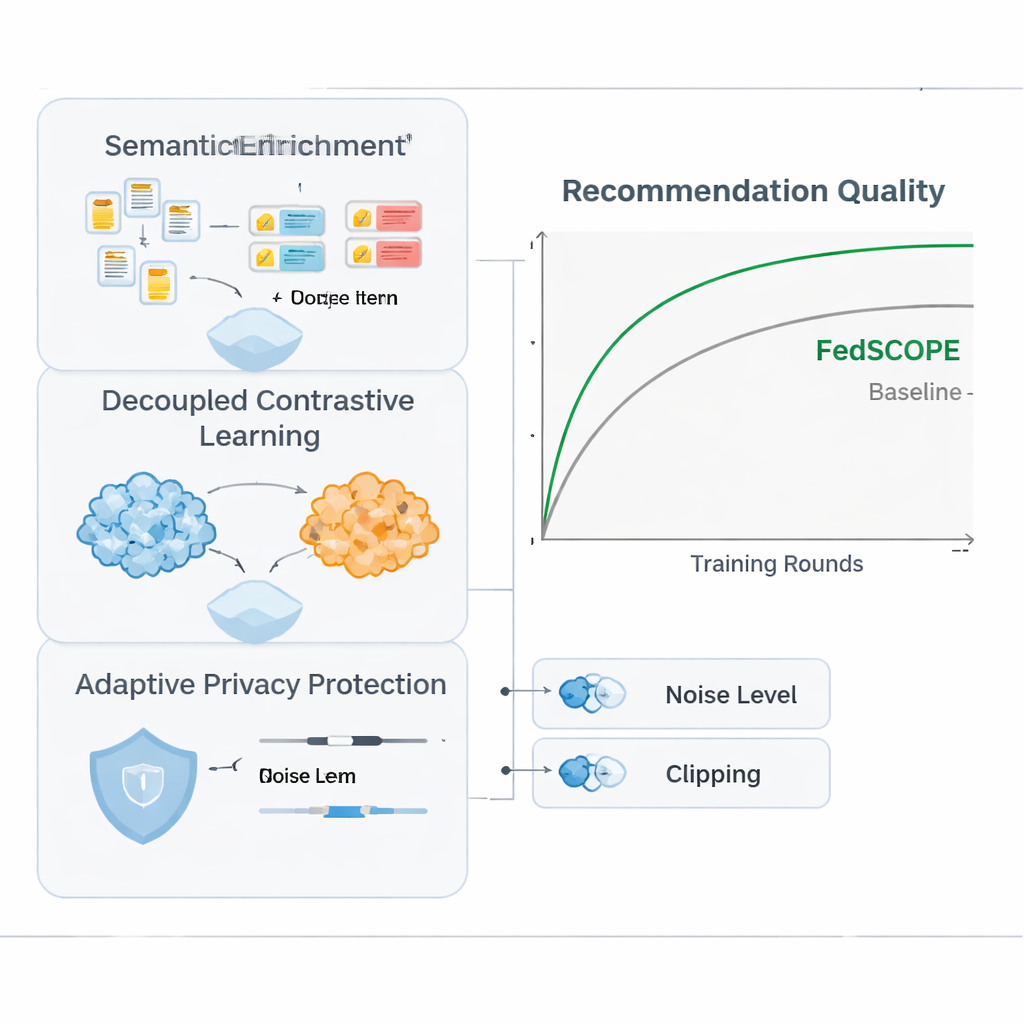
Per sfruttare i comportamenti provenienti da più domini senza mescolare segnali in modo dannoso, FedSCOPE introduce una strategia di training chiamata apprendimento contrastivo decoupled. In termini semplici, il sistema impara due cose contemporaneamente. Primo, all’interno di ciascun dominio—per esempio solo la parte film—avvicina utenti che si comportano in modo simile e allontana quelli che non lo sono, affinando il senso del gusto personale in quell’ambiente. Secondo, tra domini, allinea le rappresentazioni dello stesso utente mantenendo distinti utenti diversi, così che ciò che guardi possa aiutare a prevedere cosa potresti leggere o comprare, senza confondere la tua identità con quella di altri. Gestendo separatamente questi obiettivi “all’interno del dominio” e “tra domini”, il metodo evita un problema comune in cui forzare tutto in un unico modello condiviso distrugge le preferenze a livello fine.
Proteggere la privacy senza buttare via l’utilità
La privacy matematica forte, nota come privacy differenziale, di solito implica aggiungere rumore casuale agli aggiornamenti del modello prima che vengano condivisi con un server centrale. Molti sistemi precedenti usavano gli stessi parametri di privacy per tutti i partecipanti, che è una soluzione inadeguata quando alcuni client hanno milioni di utenti e altri solo poche migliaia. FedSCOPE invece assegna a ogni client un budget di privacy personalizzato e adatta quanto taglia e perturba i propri aggiornamenti in base alla dimensione dei dati e al comportamento passato. Le piattaforme grandi e ricche di dati possono contribuire con informazioni più precise senza essere eccessivamente disturbate dal rumore, mentre quelle più piccole vengono protette in modo più aggressivo. Tutti gli aggiornamenti vengono quindi aggregati usando una tecnica di aggregazione sicura, così il server non vede mai alcun contributo individuale in chiaro.
Cosa mostrano gli esperimenti in pratica
Gli autori hanno testato FedSCOPE su dati di acquisti reali provenienti da Amazon, abbinando domini come Film con Libri e Cibo con Cucina. L’hanno confrontato con una serie di metodi di raccomandazione moderni, inclusi altri approcci preservanti la privacy e cross-dominio. Su molteplici misure di accuratezza, FedSCOPE si è classificato costantemente ai vertici o vicino a essi. Ha convergento più rapidamente durante l’addestramento, ha funzionato meglio per utenti con pochissime interazioni passate e si è mostrato robusto quando cambiava il numero di client partecipanti o la frazione campionata in ogni round. Importante: quando il team ha reso più stringenti i vincoli di privacy, la strategia adattiva di FedSCOPE ha mantenuto prestazioni molto più elevate rispetto ai sistemi che usano privacy differenziale uguale per tutti.
Cosa significa questo per gli utenti di tutti i giorni
Dal punto di vista di un non esperto, FedSCOPE indica un futuro in cui le tue app preferite possono collaborare per comprendere meglio i tuoi gusti senza mai mettere insieme i tuoi dati grezzi. Arricchendo storie scarse con informazioni derivate da modelli linguistici, separando con cura ciò che è specifico del dominio da ciò che è condiviso e regolando i controlli di privacy per ciascun partecipante, il framework offre raccomandazioni più rilevanti e più rispettose delle informazioni personali. In termini pratici, ciò potrebbe tradursi in suggerimenti migliori su cosa guardare, leggere o comprare dopo—senza dover rinunciare alla tua privacy digitale.
Citazione: Zhao, L., Lin, Y., Qin, S. et al. FedSCOPE: Federated cross-domain sequential recommendation with decoupled contrastive learning and privacy-preserving semantic enhancement. Sci Rep 16, 7420 (2026). https://doi.org/10.1038/s41598-026-38628-y
Parole chiave: raccomandazione federata, IA preservante la privacy, personalizzazione cross-dominio, modelli linguistici di grandi dimensioni, privacy differenziale