Clear Sky Science · it
Esplorare l’interazione insegnante-studente attraverso modelli linguistici multimodali di grande scala: un’indagine empirica
Perché osservare le aule con l’IA è importante
Chiunque sia stato in un’aula sa che il modo in cui insegnanti e studenti interagiscono può fare la differenza tra noia e apprendimento reale. Eppure è sorprendentemente difficile studiare questi scambi momento per momento: gli osservatori si stancano, i giudizi umani variano e i dati video diventano rapidamente travolgenti. Questo articolo esplora come un nuovo tipo di intelligenza artificiale — modelli linguistici multimodali in grado di “guardare” le immagini e “leggere” il testo — possa aiutare ricercatori e scuole a comprendere la vita complessa dell’aula in modo più rapido e oggettivo.
Trasformare lezioni reali in dati di ricerca
I ricercatori hanno iniziato con video di aula ordinari provenienti da scuole primarie e secondarie cinesi, disponibili pubblicamente su una piattaforma educativa nazionale. Da 30 lezioni hanno estratto quasi 2.400 immagini fisse che catturavano momenti chiave di insegnamento e apprendimento. Ogni immagine è stata etichettata secondo cinque pattern di interazione facili da comprendere: guidata (insegnante che spiega), collaborativa (studenti che lavorano insieme), interrogativa (domande e risposte), indipendente (studenti che lavorano da soli) e esibitiva (studenti che presentano alla classe). Esperti in tecnologia educativa hanno contribuito a perfezionare queste categorie in modo che corrispondessero a ciò che osservatori esperti cercano nelle aule reali.
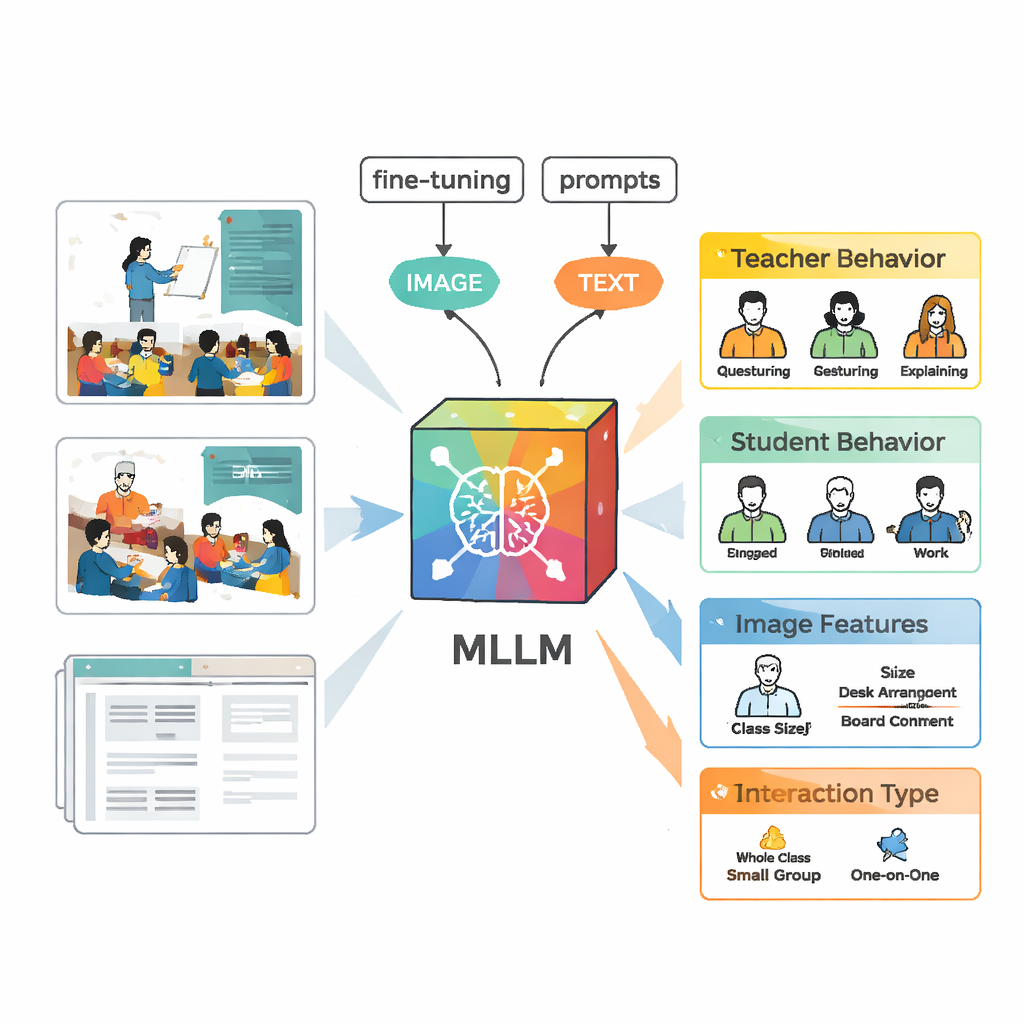
Insegnare a un’IA a vedere la dinamica dell’aula
Per analizzare queste scene il team ha utilizzato un modello linguistico multimodale chiamato VisualGLM‑6B, in grado di prendere in input sia immagini sia testo. Poiché il modello originale era stato addestrato in modo generale e non specificamente sulle aule, i ricercatori lo hanno “messo a punto” usando le loro immagini etichettate. Hanno adottato una tecnica chiamata LoRA che modifica solo un piccolo numero di parametri interni del modello, rendendo l’addestramento più efficiente ma comunque potente. Hanno inoltre progettato prompt accurati — istruzioni strutturate che dicono al modello di descrivere il comportamento dell’insegnante, il comportamento degli studenti, le caratteristiche visive e il tipo di interazione in un formato coerente — in modo che l’output fosse più facilmente confrontabile con i giudizi degli esperti umani.
Costruire etichette migliori con umani e macchine
Creare un set di addestramento di alta qualità ha richiesto più che limitarsi a mostrare al modello i video. Per prima cosa, VisualGLM ha prodotto descrizioni di base per ogni immagine. I annotatori umani hanno poi corretto gli errori e integrato il contesto mancante, per esempio chi stava parlando o se gli studenti stavano ascoltando o discutendo. Successivamente queste descrizioni perfezionate sono state fornite a ChatGPT che, guidato da prompt personalizzati, ha generato analisi strutturate seguendo le cinque categorie di interazione. Gli esperti hanno rivisto e modificato nuovamente queste analisi generate dall’IA. Il risultato finale è stato un dataset ricco in cui ogni immagine porta con sé un resoconto dettagliato e affidabile di ciò che insegnanti e studenti stavano facendo.
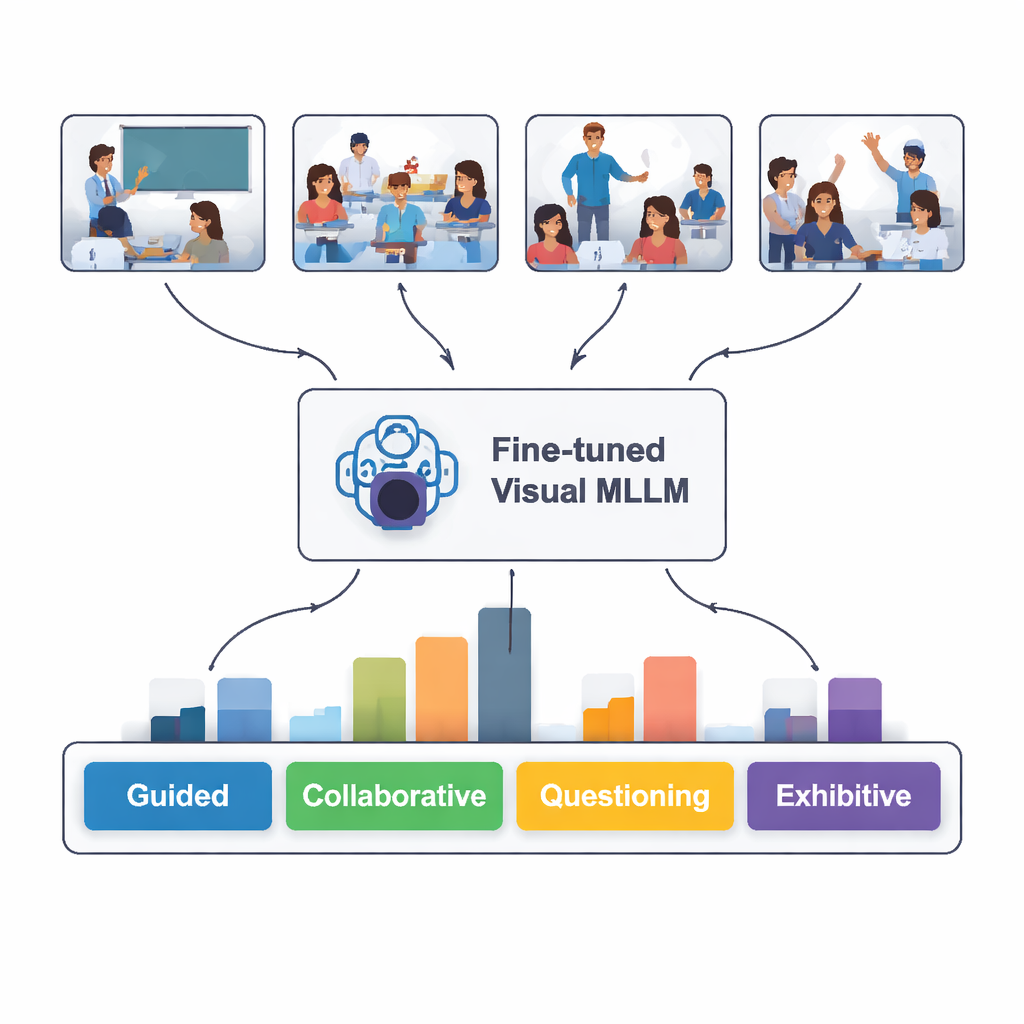
Quanto bene l’IA ha “letto” l’aula?
Quando testato su 100 nuove immagini di aula mai viste prima, il modello messo a punto ha identificato correttamente il tipo di interazione nell’82 percento dei casi. Ha ottenuto i migliori risultati nel riconoscere situazioni guidate, indipendenti ed esibitive — quando l’insegnante spiega chiaramente, gli studenti lavorano in silenzio da soli o uno studente presenta davanti alla classe. Ha mostrato maggiori difficoltà con il lavoro collaborativo e le situazioni interrogative, dove linguaggio del corpo e disposizione dei posti possono essere ambigui anche per le persone. Un confronto testuale più approfondito ha mostrato che le descrizioni scritte del modello spesso corrispondevano abbastanza da vicino alle analisi degli esperti, sebbene occasionalmente il modello abbia “allucinato” dettagli non presenti nelle immagini o frainteso un gesto sottile.
Cosa significa per le aule future
Per un lettore non specialista, il messaggio centrale è che i sistemi di IA stanno diventando capaci di osservare le aule e riassumere come si svolgono insegnamento e apprendimento, con un livello di struttura e coerenza difficile da mantenere per gli esseri umani su migliaia di scene. Pur non essendo perfetti — soprattutto per forme sottili di discussione e interrogazione — l’approccio dimostra che i modelli linguistici multimodali possono già supportare la ricerca educativa e, in futuro, strumenti di feedback per la didattica. Man mano che questi modelli cominceranno a includere suoni, gesti e dataset più ampi e vari, potrebbero aiutare gli insegnanti a vedere schemi nella loro pratica finora nascosti, offrendo una nuova lente su come le interazioni quotidiane plasmano l’apprendimento degli studenti.
Citazione: Chen, G., Han, G., Niu, J. et al. Exploring teacher-student interaction through multimodal large language models: an empirical investigation. Sci Rep 16, 7602 (2026). https://doi.org/10.1038/s41598-026-38626-0
Parole chiave: interazione insegnante-studente, analisi delle aule, IA multimodale, tecnologia educativa, modelli linguistici di grande scala