Clear Sky Science · it
Classificazione incrementale intelligente mediante una rete neurale dinamica potenziata da grasshopper per flussi di dati
Perché i dati in continuo cambiamento sono importanti
Dalle reti elettriche e dagli impianti industriali ai pagamenti online, i sistemi moderni producono dati ogni secondo. Nelle correnti continue di questi flussi informativi si nascondono avvisi precoci di guasti alle apparecchiature, attacchi informatici o impennate dei prezzi. La difficoltà è che questo fiume di informazioni non si ferma mai e il suo comportamento cambia nel tempo. L’articolo qui riassunto presenta un nuovo modo di addestrare le reti neurali in modo che possano continuare ad apprendere da dati in tempo reale senza rallentare o perdere accuratezza, rendendole più utili per monitoraggio e presa di decisioni nel mondo reale.
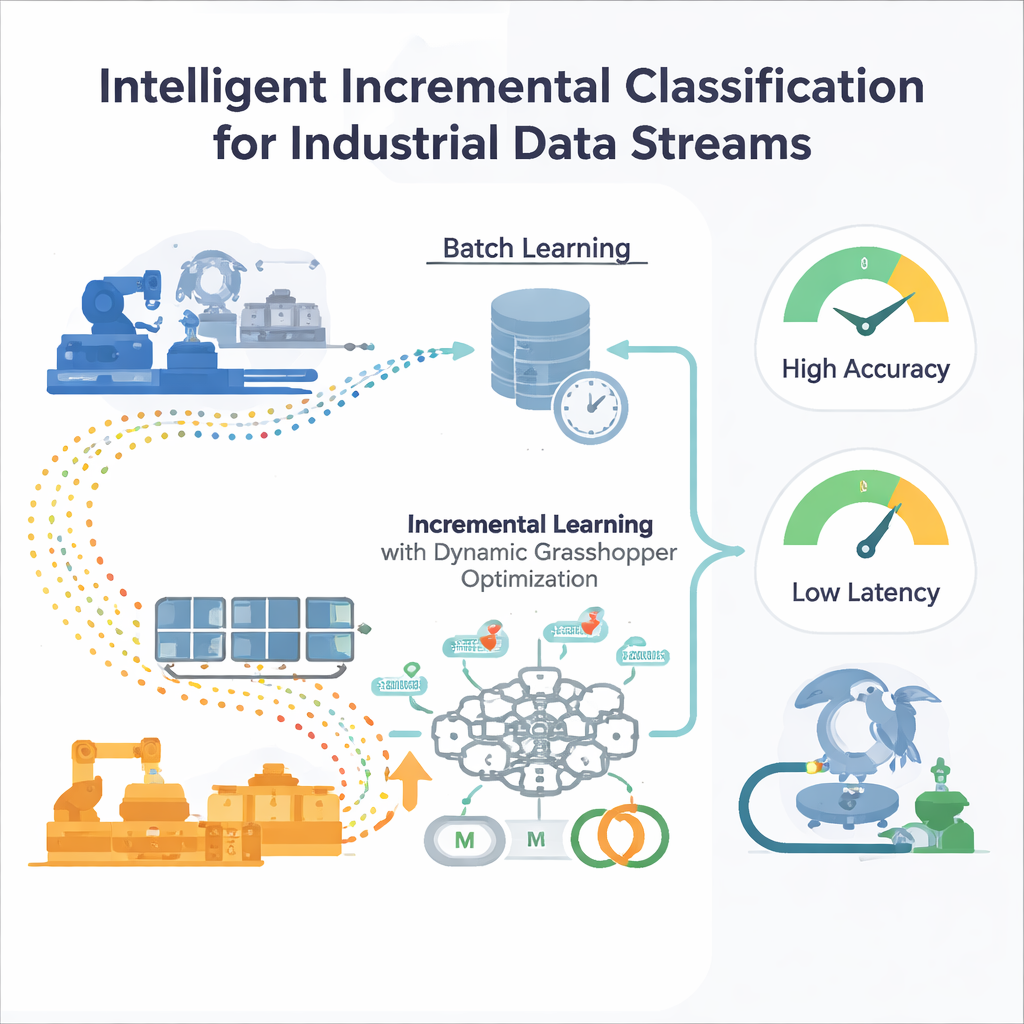
I limiti dell’addestramento una tantum
La maggior parte dei modelli di machine learning tradizionali viene addestrata in “batch”: gli ingegneri raccolgono un ampio set di dati storici, ottimizzano il modello e poi lo distribuiscono. Questo approccio funziona se il mondo resta più o meno invariato. Ma in ambito industriale le condizioni evolvono—i pattern di domanda cambiano, i sensori invecchiano, i mercati oscillano. Un modello congelato nel tempo diventa progressivamente incapace di riconoscere nuovi schemi, e riaddestrarlo da zero su dataset sempre più grandi è costoso e lento. Anche i metodi di ottimizzazione automatica standard come grid search o algoritmi evolutivi assumono dati fissi, il che richiede di riavviarli ogni volta che la distribuzione dei dati si sposta, cosa impraticabile per sistemi sempre attivi.
Una rete neurale che impara al volo
Gli autori propongono un framework di apprendimento incrementale incentrato su un perceptrone multistrato (MLP), un tipo comune di rete neurale. Invece di fornire alla rete tutti i dati passati in una volta, il flusso di dati in arrivo viene suddiviso in finestre gestibili. Ogni nuova finestra diventa un piccolo passo di addestramento che aggiorna i pesi interni della rete e poi viene scartata—una strategia di “addestrare e dimenticare” che mantiene bassa l’occupazione di memoria. Cruciale è che il sistema non si basa su impostazioni di addestramento fisse. Due manopole chiave che controllano il comportamento di apprendimento—il learning rate (quanto è grande ogni aggiornamento) e il momentum (quanto gli aggiornamenti procedono in modo fluido)—vengono continuamente aggiustate mentre il flusso evolve, così il modello può restare reattivo senza diventare instabile.
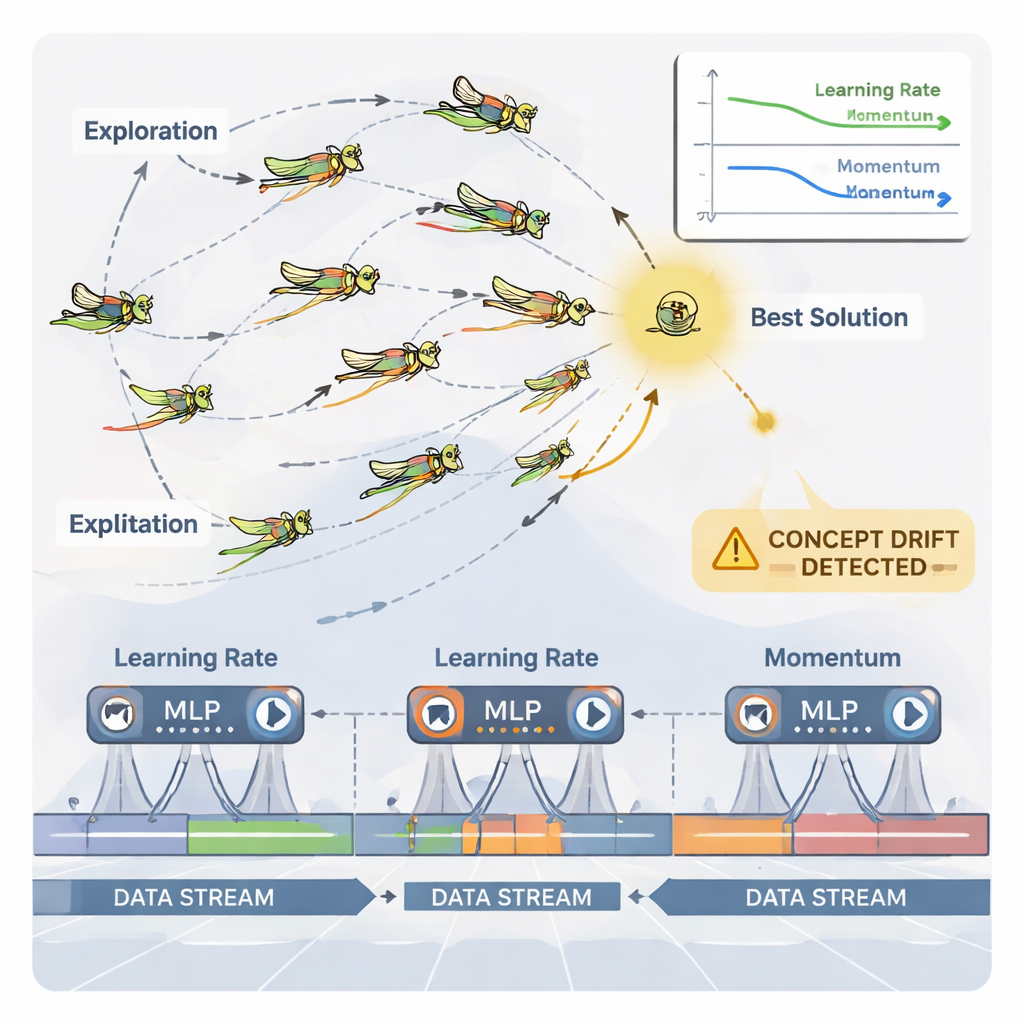
I grasshopper come regolatori intelligenti dei parametri
Per gestire questo continuo aggiustamento, l’articolo utilizza un ottimizzatore ispirato alla natura chiamato Dynamic Grasshopper Optimization Algorithm (DGOA). Immaginate uno sciame di grasshopper virtuali che esplora possibili combinazioni di learning rate e momentum. All’inizio si muovono ampiamente per cercare buone regioni; successivamente restringono i movimenti per perfezionare le scelte promettenti. In questa variante dinamica, la dimensione del passo e l’attrazione verso la migliore soluzione cambiano nel tempo in base a quanto bene sta funzionando la rete neurale. Il sistema monitora anche il “concept drift”—cambiamenti improvvisi negli errori di previsione o nei dati stessi. Quando viene rilevato un drift, alcuni grasshopper vengono resettati e i loro passi diventano temporaneamente più grandi, permettendo all’ottimizzatore di esplorare rapidamente nuove regioni ed eludere impostazioni ormai obsolete.
Mettere il metodo alla prova
I ricercatori hanno valutato il loro approccio su un dataset reale del mercato elettrico australiano, con l’obiettivo di prevedere se i prezzi sarebbero saliti o scesi. Rispetto a metodi di tuning comuni come grid search, random search, particle swarm optimization, algoritmi genetici, ant colony optimization e l’algoritmo grasshopper standard, la versione dinamica accoppiata all’apprendimento incrementale ha raggiunto la massima accuratezza (circa 89,5%) utilizzando meno tempo di calcolo e meno iterazioni. Esperimenti aggiuntivi hanno mostrato che il metodo si adatta meglio sia a flussi di dati stabili sia a quelli mutevoli, scala da migliaia a miliardi di campioni mantenendo sotto controllo la memoria ed è competitivo in attività come manutenzione predittiva, rilevamento di anomalie e rilevamento frodi, oltre che su benchmark standard di ottimizzazione matematica.
Cosa significa tutto questo nella pratica
Per i non esperti, il messaggio è che questo lavoro propone un modo per mantenere le reti neurali “vive” e ben calibrate in ambienti dove i dati non si fermano mai e le condizioni mutano costantemente. Invece di fermare ripetutamente il sistema per ricostruire i modelli da zero, il framework proposto permette a una rete leggera di aggiornarsi finestra dopo finestra, mentre un ottimizzatore basato sullo sciame regola continuamente la velocità e la scorrevolezza dell’apprendimento. Il risultato è un adattamento più rapido ai nuovi schemi, una migliore accuratezza a lungo termine e un uso più efficiente delle risorse di calcolo—ingredienti chiave per decisioni affidabili in tempo reale in settori come energia, manifattura e finanza.
Citazione: Darwish, S.M., El-Shoafy, N.A. Intelligent incremental classification using a dynamic grasshopper-enhanced neural network for data streams. Sci Rep 16, 7730 (2026). https://doi.org/10.1038/s41598-026-38571-y
Parole chiave: flussi di dati, apprendimento incrementale, reti neurali, ottimizzazione degli iperparametri, intelligenza degli sciami