Clear Sky Science · it
Un modello di apprendimento automatico interpretabile che utilizza dati clinici di routine per la previsione precoce della recidiva nel carcinoma epatocellulare
Perché questo è importante per pazienti e familiari
Per le persone sottoposte a intervento chirurgico per rimuovere un tumore al fegato, una delle domande più pressanti è: «Il cancro tornerà presto?». Oggi i medici possono offrire solo stime approssimative, spesso basate su sistemi di stadiazione generici che trattano molti pazienti come se fossero uguali. Questo studio presenta un nuovo modo di usare informazioni che gli ospedali raccolgono già — esami del sangue di routine e risultati di imaging — insieme a un’intelligenza artificiale interpretabile per dare a ogni paziente un quadro più chiaro e personalizzato del rischio a breve termine che il cancro ricompaia.
Un cancro comune con un tasso di recidiva ostinato
Il carcinoma epatocellulare è il tipo più comune di tumore primario del fegato ed è una delle principali cause di morte per cancro nel mondo. Anche quando i chirurghi rimuovono completamente i tumori visibili, più del 70% dei pazienti vede la malattia riemergere entro cinque anni. La recidiva precoce — entro circa due anni dall’intervento — è particolarmente preoccupante, perché di solito riflette cellule tumorali aggressive che si sono già diffuse all’interno del fegato e peggiora nettamente la sopravvivenza. I sistemi di stadiazione clinica esistenti, come TNM o il Barcelona Clinic Liver Cancer (BCLC), possono classificare i pazienti in categorie ampie, ma spesso non riescono a identificare con precisione chi è davvero ad alto rischio di una recidiva precoce.
Trasformare i risultati degli esami di routine in un punteggio di rischio
I ricercatori hanno utilizzato i dati di 1.120 pazienti sottoposti a chirurgia apparentemente curativa del fegato in due grandi ospedali cinesi tra il 2014 e il 2024. Si sono concentrati solo sulle informazioni disponibili prima dell’operazione: età e sesso, caratteristiche radiologiche come la dimensione del tumore più grande e la presenza di tumori multipli, e un ampio pannello di esami di laboratorio standard eseguiti nei giorni precedenti l’intervento. Da questi hanno selezionato nove predittori chiave legati alla probabilità di recidiva. Invece di affidarsi a una singola formula matematica, hanno combinato tre diversi approcci di apprendimento automatico e hanno mediato i loro output in un unico punteggio di rischio compreso tra 0 e 1. I pazienti sono stati quindi raggruppati in categorie a basso, medio e alto rischio sulla base di questo punteggio. 
Superare i sistemi di stadiazione standard
Per testare l’efficacia del modello, il team lo ha prima valutato su un campione di pazienti «tenuto fuori» (hold-out) dall’ospedale di origine e poi su un gruppo indipendente del secondo ospedale. In entrambi i casi, il nuovo modello si è dimostrato chiaramente migliore dei sistemi di stadiazione tradizionali nel distinguere chi sarebbe rimasto libero da malattia e chi avrebbe avuto una recidiva entro 24 mesi. Nel gruppo di test interno, l’accuratezza del modello nel tempo, misurata da una statistica standard chiamata area sotto la curva, è stata di circa 0,76, rispetto a circa 0,55–0,64 per i metodi di stadiazione comuni. Le persone nel gruppo ad alto rischio hanno avuto la peggiore sopravvivenza libera da recidiva; quelle nel gruppo a rischio moderato hanno visto il rischio di recidiva ridursi di circa il 60%, mentre il gruppo a basso rischio ha avuto un rischio di circa il 90% inferiore rispetto al gruppo ad alto rischio. Queste marcate differenze sono state confermate anche nell’ospedale esterno e sono rimaste coerenti nella maggior parte dei sottogruppi, come pazienti più giovani e più anziani, uomini e donne, e persone con tumori grandi o piccoli.
Aprire la scatola nera dell’intelligenza artificiale
Una critica frequente all’apprendimento automatico in medicina è che si comporta come una scatola nera: può predire bene, ma anche gli specialisti non riescono a capire perché. Per affrontare questo problema, gli autori hanno applicato un metodo chiamato SHapley Additive exPlanations, o SHAP, che scompone ogni previsione nelle contribuzioni di ciascun fattore di input. L’analisi ha mostrato che la dimensione del tumore è stata il fattore singolo più importante nell’aumentare il rischio in tutti e tre gli algoritmi, seguita da caratteristiche come il numero di tumori e indicatori ematici della funzione epatica e dell’infiammazione. Interessante notare che il livello di cloruro nel sangue tendeva a spingere il rischio nella direzione opposta, agendo come fattore protettivo in questo dataset. Per i singoli pazienti, il modello può generare semplici grafici a barre che mostrano, ad esempio, come un ampio diametro tumorale e marcatori ematici sfavorevoli aumentino il punteggio di rischio, mentre una migliore funzione epatica lo abbassi. 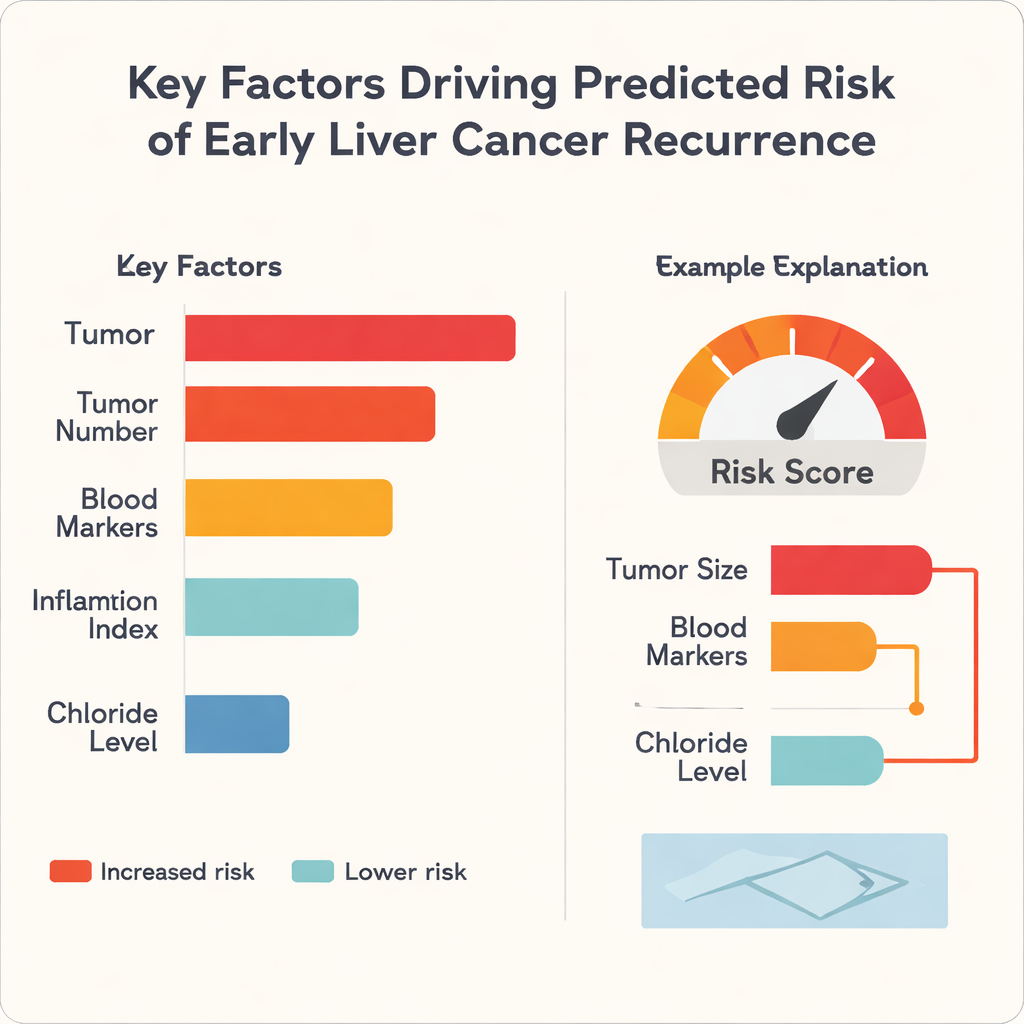
Cosa potrebbe significare in clinica
Poiché il modello si basa su dati che gli ospedali raccolgono già e non richiede esami speciali o test genetici costosi, potrebbe essere implementato in molti contesti assistenziali, compresi quelli con risorse limitate. Prima dell’intervento, i medici potrebbero usarlo per identificare persone che necessitano di programmi di follow-up più intensivi o che potrebbero beneficiare di trattamenti aggiuntivi dopo l’intervento, risparmiando al contempo ai pazienti a rischio realmente basso test e preoccupazioni non necessari. Gli autori osservano che il loro studio è retrospettivo e basato su una popolazione di pazienti specifica, quindi sono ancora necessari studi prospettici in contesti più diversi. Tuttavia, il loro lavoro illustra come un’IA trasparente e spiegabile possa trasformare numeri di laboratorio e referti di imaging familiari in previsioni individuali significative che supportano il processo decisionale condiviso tra pazienti e team di cura.
Citazione: Guo, DF., Wen, Q., Zhang, X. et al. An interpretable machine learning model using routine clinical data for early recurrence prediction in hepatocellular carcinoma. Sci Rep 16, 7520 (2026). https://doi.org/10.1038/s41598-026-38484-w
Parole chiave: recidiva del cancro al fegato, modello di apprendimento automatico, predizione del rischio clinico, IA interpretabile, carcinoma epatocellulare