Clear Sky Science · it
Un modello ibrido CNN–transformer spiegabile per il riconoscimento della lingua dei segni su dispositivi edge usando fusione adattiva e distillazione della conoscenza
Perché gli strumenti per la lingua dei segni in piccolo sono importanti
Miliardi di conversazioni quotidiane si basano su movimenti delle mani, espressioni facciali e linguaggio del corpo più che su parole pronunciate. Eppure la maggior parte di telefoni, tablet e dispositivi pubblici non è ancora in grado di comprendere le lingue dei segni, soprattutto al di fuori dei paesi anglofoni. Questo articolo presenta TinyMSLR, un sistema compatto e spiegabile per il riconoscimento della lingua dei segni progettato per funzionare in tempo reale su dispositivi piccoli e a basso consumo. L’obiettivo è trasformare hardware comune in ausili di comunicazione accessibili e affidabili per le persone sorde e con problemi di udito in tutto il mondo.
Portare più lingue nella conversazione
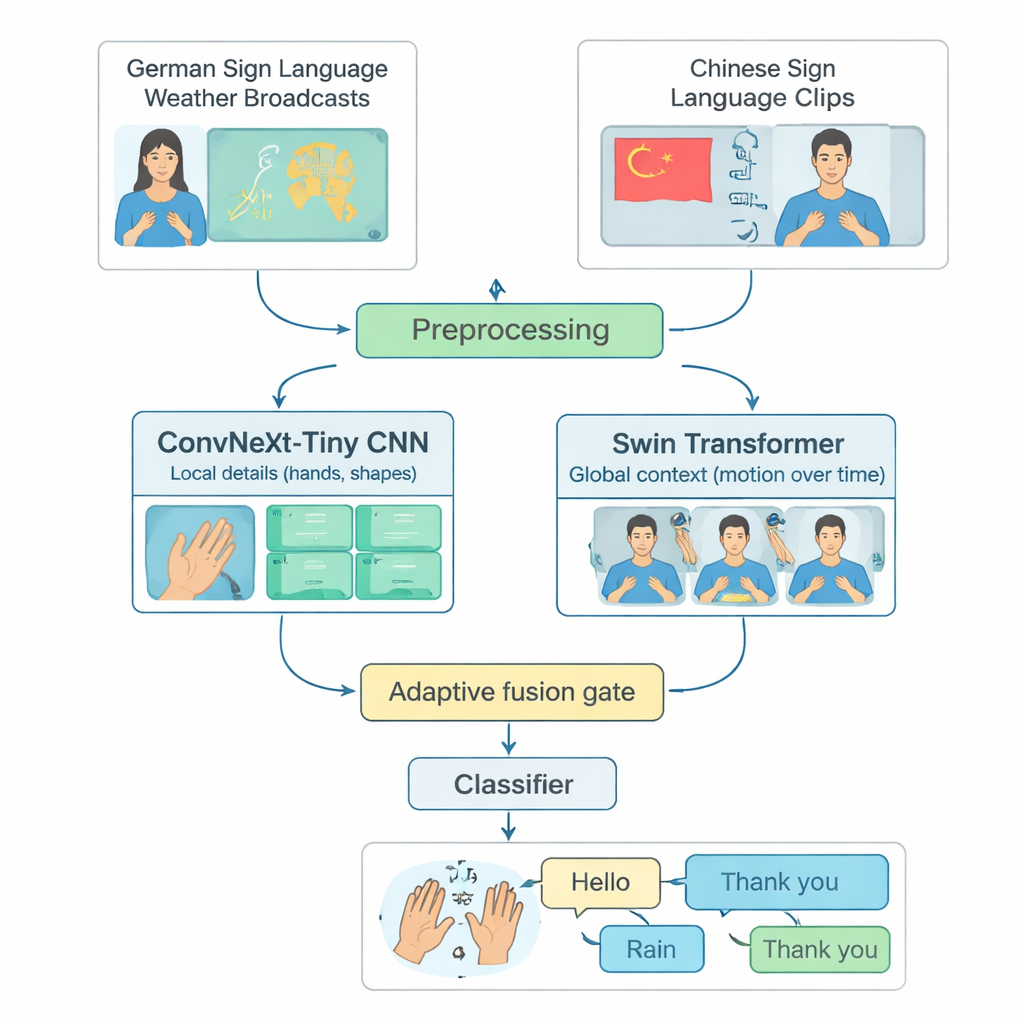
Molti sistemi avanzati di riconoscimento della lingua dei segni si concentrano su una sola lingua, spesso l’American Sign Language, e girano solo su computer potenti. Ciò esclude persone che usano altre lingue dei segni o che vivono in regioni con risorse computazionali limitate. Gli autori affrontano questo divario costruendo un banco di prova condiviso a partire da due lingue diverse: trasmissioni meteo in lingua dei segni tedesca e una grande raccolta di lingua dei segni cinese. Selezionano con cura 20 segni comuni della vita quotidiana — come Ciao, Meteo, Pioggia, Felice, Sì e Grazie — che esistono in entrambe le lingue. Accorciando video lunghi in clip brevi contenenti un solo segno e bilanciando il numero di esempi per classe e per firmatario, creano un modo equo e riproducibile per valutare quanto bene un modello riconosce segni isolati attraverso le lingue.
Come il modello ibrido vede mani e movimento
TinyMSLR combina due modalità complementari di analisi del video. Un ramo utilizza una rete convoluzionale moderna (ConvNeXt‑Tiny) che eccelle nell’individuare dettagli fini, come la forma delle dita e texture sottili. Il secondo ramo usa uno Swin Transformer, una famiglia di modelli più recente che si distingue nel tracciare pattern nello spazio e nel tempo — come mani, volto e parte superiore del corpo si muovono attraverso i frame. Ogni clip video breve è normalizzata a 32 frame di 224×224 pixel, leggermente aumentata (per esempio con piccole rotazioni o variazioni di luminosità) e poi fornita a entrambi i rami in parallelo. Ciascun ramo produce un riassunto di 768 numeri di ciò che osserva; insieme, queste due sintesi catturano sia dettagli locali nitidi sia movimenti e contesto più ampi.
Lascare che sia il modello a decidere cosa conta di più
Poiché alcuni segni si distinguono principalmente per la forma della mano mentre altri dipendono da movimenti più ampi delle braccia o da indizi facciali, TinyMSLR non fissa una sola ricetta per combinare le due viste. Usa invece una piccola “porte di fusione” che apprende, per ogni clip in input, quanto fidarsi del ramo focalizzato sui dettagli rispetto a quello focalizzato sul contesto. La porta osserva entrambe le sintesi di feature e produce due pesi che sommano sempre a uno; la rappresentazione finale è una miscela pesata dei due. Durante l’addestramento, ogni ramo ottiene anche un piccolo classificatore proprio in modo da imparare a essere utile da solo, e una coppia di reti “insegnante” più grandi (una CNN, un Transformer) guida dolcemente il modello piccolo mostrando non solo l’etichetta corretta ma anche quali etichette alternative appaiono simili. Questa tecnica, chiamata distillazione della conoscenza, aiuta il sistema compatto ad avvicinarsi alla precisione dei modelli più pesanti mantenendo dimensioni e velocità adatte ai dispositivi edge.
Capire perché il sistema prende ogni decisione
Oltre alla pura accuratezza, gli autori sottolineano che utenti e sviluppatori dovrebbero poter ispezionare ciò a cui il modello presta attenzione. Adottano SHAP, una famiglia di strumenti che assegna un valore di importanza a ogni parte dell’input. In pratica, calcolano queste spiegazioni su feature intermedie e le rimappano sui frame come mappe di calore e grafici temporali. Ciò rivela, per esempio, quali frame e regioni guidano la decisione tra segni visivamente simili come Pioggia e Neve o Freddo e Male. Aggregando molte spiegazioni emergono pattern più ampi: segnali non manuali come espressione facciale e movimento della testa, così come l’orientamento del polso e la forma della mano, risultano particolarmente influenti. Queste intuizioni aiutano a verificare che il sistema si basi su aspetti significativi della segnatura piuttosto che su artefatti di sfondo.

Velocità, parsimonia e margini di miglioramento
Sul benchmark bilingue a 20 segni, TinyMSLR raggiunge circa il 99% di accuratezza in addestramento e validazione e un punteggio F1 vicino al 99%, usando meno di 2,7 milioni di parametri e circa 1,9 miliardi di operazioni per clip. Su una GPU moderna elabora un segno in circa 13,5 millisecondi e consuma meno di 30 millijoule di energia; il modello memorizzato occupa solo circa 7,2 megabyte. Questi numeri suggeriscono che il riconoscimento dei segni in tempo reale e on‑device è fattibile su schede a basso costo e sistemi embedded. Gli autori osservano con attenzione che il loro lavoro copre solo segni brevi e isolati e due lingue, e tratta le espressioni facciali in modo implicito piuttosto che come segnale separato. Estendere l’approccio a vocabolari più ricchi, frasi continue, più lingue e una modellazione esplicita dei movimenti del volto e della testa è lasciato ai lavori futuri. Tuttavia, TinyMSLR offre una prova di concetto convincente: strumenti accurati, efficienti e interpretabili per comprendere le lingue dei segni non devono essere confinati al cloud — possono risiedere direttamente sui dispositivi di uso quotidiano.
Citazione: Lamaakal, I., Yahyati, C., Maleh, Y. et al. An explainable hybrid CNN–transformer model for sign language recognition on edge devices using adaptive fusion and knowledge distillation. Sci Rep 16, 7143 (2026). https://doi.org/10.1038/s41598-026-38478-8
Parole chiave: riconoscimento della lingua dei segni, tiny machine learning, edge AI, AI spiegabile, modelli multilingue