Clear Sky Science · it
SAT: shift alignment transformer per il denoising video senza stima del flusso
Video più nitidi da scene rumorose
Chiunque abbia provato a filmare al chiuso di notte o con uno smartphone in condizioni di luce scarsa conosce il risultato: video granosi e tremolanti in cui i dettagli sembrano scivolare e i colori risultano alterati. Questo articolo presenta un nuovo metodo per ripulire tali video, trasformandoli in sequenze più nitide e stabili senza fare affidamento sui pesanti software di tracciamento del movimento che normalmente rendono possibile questo risultato. Il metodo, chiamato Shift Alignment Transformer, è progettato per preservare i dettagli fini mantenendo al contempo un’efficienza sufficiente per essere pratico.
Perché pulire i video è così difficile
Rimuovere il rumore da una singola fotografia è già una sfida; farlo per i video è ancora più complesso. Da un lato, ogni fotogramma è corrotto da puntini casuali e spostamenti di colore. Dall’altro, i fotogrammi sono collegati nel tempo: gli oggetti si muovono, la camera trema e i dettagli appaiono e scompaiono. I metodi tradizionali di denoising video si sono spesso basati sulla stima del movimento tra fotogrammi, spesso tramite uno strumento chiamato optical flow, che cerca di tracciare dove ogni pixel si sposta da un fotogramma al successivo. Pur essendo potenti, queste stime del movimento possono facilmente fallire quando il video è estremamente rumoroso o il movimento è veloce e complesso, e aggiungono inoltre un notevole carico computazionale che può rallentare i sistemi.
Un nuovo modo di allineare senza tracciare
Invece di cercare esplicitamente di seguire ogni pixel, lo Shift Alignment Transformer (SAT) segue una strada diversa: permette alla rete di scoprire implicitamente come i fotogrammi sono correlati mediante spostamenti e confronti accurati delle feature. Il modello è costruito attorno a un’architettura moderna nota come Transformer, che eccelle nell’individuare connessioni a lungo raggio nei dati. All’interno di questo quadro, gli autori introducono un Modulo di Shift Spazio-Temporale che mescola delicatamente le informazioni sia nel tempo sia nello spazio. Nel tempo, il modello ruota ciclicamente le feature dei fotogrammi in modo che, strato dopo strato, ogni fotogramma possa “vedere” più lontano nel passato e nel futuro. Nello spazio, suddivide le feature in molti piccoli gruppi e sposta ciascun gruppo in direzioni diverse. Questa combinazione imita efficacemente come gli oggetti possono muoversi attraverso il video, permettendo alla rete di allineare informazioni provenienti da fotogrammi diversi senza mai calcolare un campo di moto esplicito.
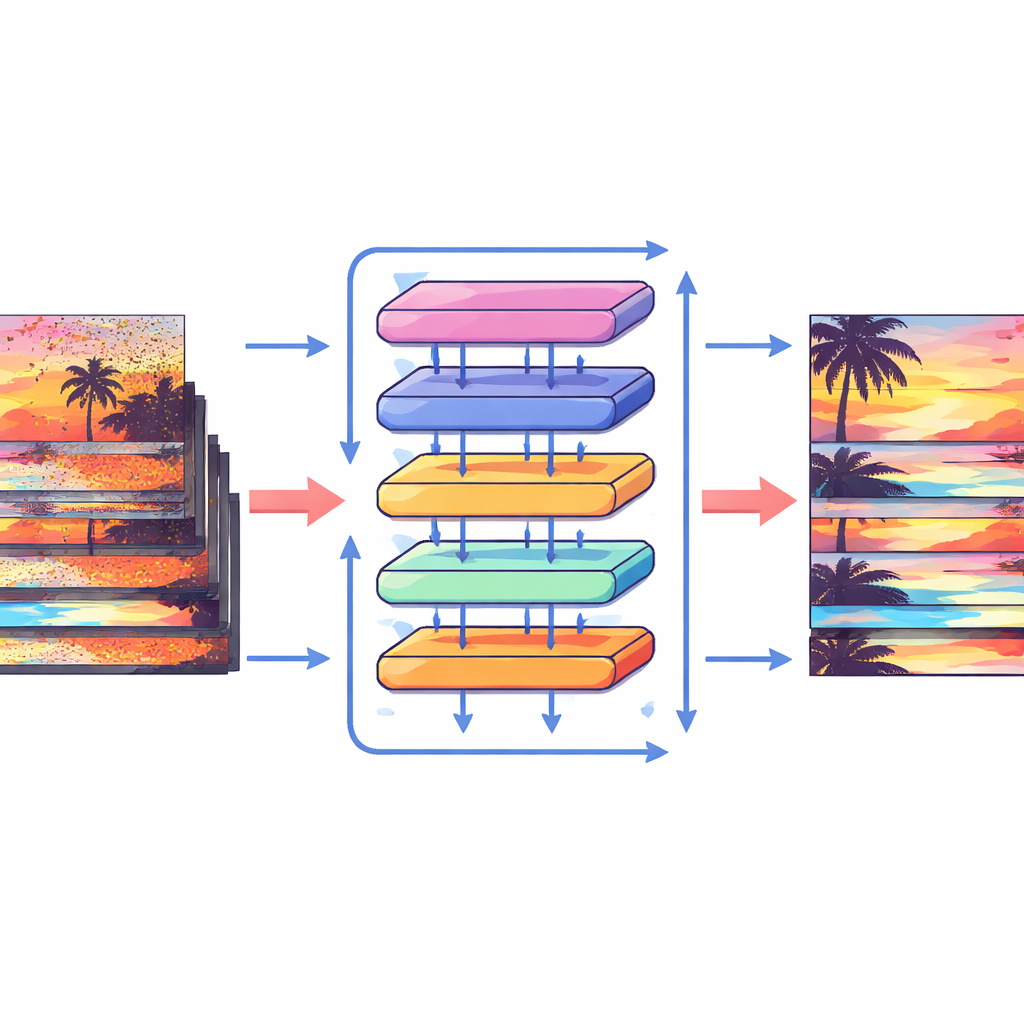
Come funzionano i nuovi blocchi costitutivi
Per sfruttare al meglio questi spostamenti, gli autori progettano un blocco di attenzione speciale che mescola informazioni all’interno e tra i fotogrammi. Prima, le feature spostate dai fotogrammi vicini vengono riunite e confrontate tramite un’operazione di cross-attention: il modello impara quali regioni in altri fotogrammi supportano meglio il fotogramma corrente in ogni posizione. Allo stesso tempo, un’operazione di attenzione separata si concentra sulle relazioni all’interno di ciascun fotogramma, rinforzando struttura e texture locali. Questi due flussi vengono poi uniti e passati attraverso semplici strati di elaborazione in una rete a forma di U multi-scala, che va da risoluzioni grossolane a fini e ritorno. Questa disposizione consente al sistema di gestire sia grandi movimenti della camera sia dettagli minuscoli come bordi sottili o piccoli pattern, ricostruendo gradualmente una versione pulita di ogni fotogramma.
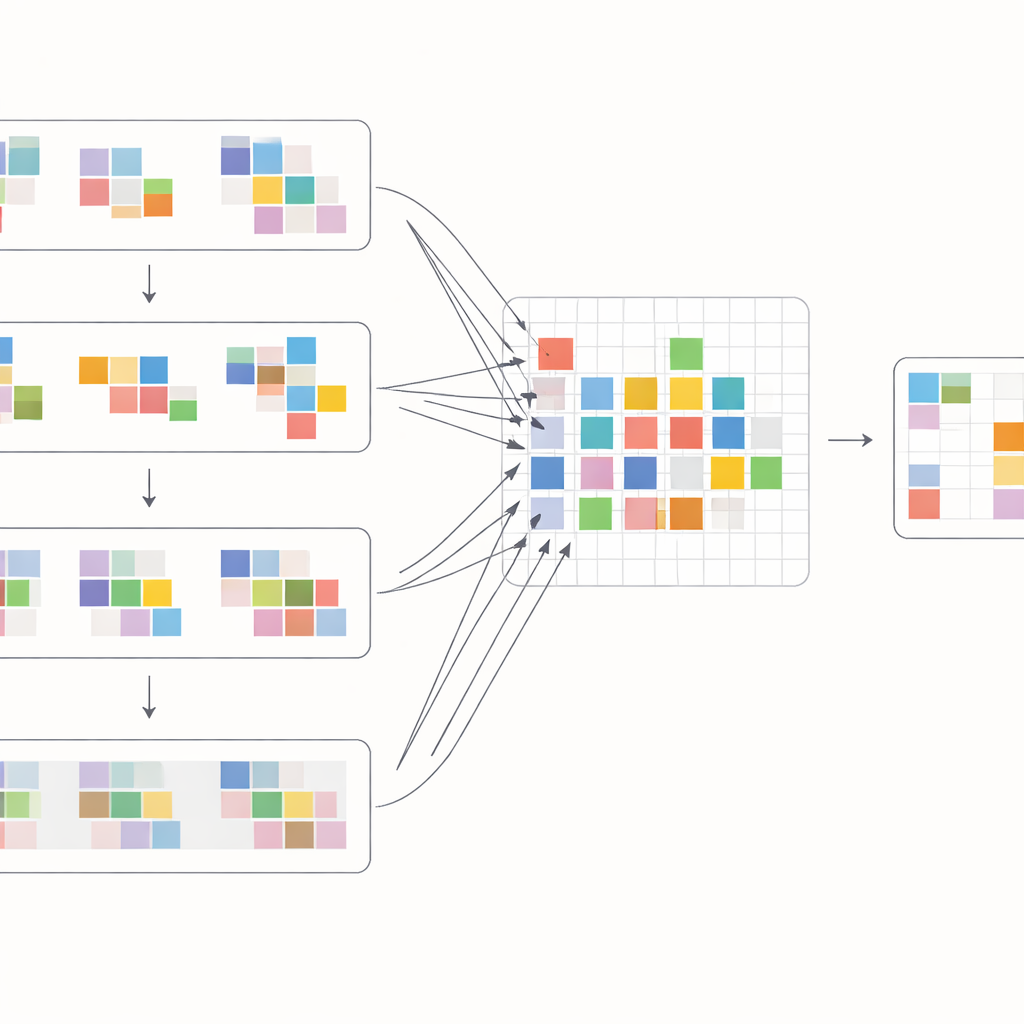
Quanto funziona bene in pratica
I ricercatori testano il loro approccio su due benchmark impegnativi. Il primo riguarda video puliti artificialmente corrotti con diversi livelli di rumore casuale, permettendo di misurare con precisione quanto i fotogrammi ripristinati si avvicinino agli originali. Qui, il nuovo metodo eguaglia o supera costantemente la qualità delle precedenti reti convoluzionali e ricorrenti, e si avvicina ai migliori modelli basati su Transformer esistenti utilizzando meno calcolo. Il secondo benchmark utilizza filmati reali catturati dai sensori d’immagine in condizioni di scarsa illuminazione, dove il rumore è non uniforme, colorato e molto meno prevedibile. In questo test più realistico, lo Shift Alignment Transformer supera in modo deciso i precedenti metodi all’avanguardia, producendo video che appaiono più puliti, più nitidi e più stabili nel tempo, con meno scostamenti cromatici e meno artefatti residui.
Cosa significa per i futuri strumenti video
In termini semplici, gli autori mostrano che è possibile denoising video in modo efficace senza tracciare esplicitamente il movimento, combinando spostamenti intelligenti nel tempo e nello spazio con l’abbinamento di feature basato sull’attenzione. Il loro Shift Alignment Transformer offre un buon equilibrio tra accuratezza ed efficienza, specialmente per filmati reali in condizioni di scarsa illuminazione, dove la stima del movimento tradizionale è fragile. Man mano che i modelli basati sull’attenzione diventano più efficienti, metodi di questo tipo potrebbero arrivare nelle fotocamere di uso quotidiano e nei servizi di streaming, aiutando a trasformare clip rumorosi e difficili da guardare in video fluidi e nitidi con il minimo sforzo per l’utente.
Citazione: Zhang, X., Fan, S., Zhang, H. et al. SAT: shift alignment transformer for video denoising without flow estimation. Sci Rep 16, 8207 (2026). https://doi.org/10.1038/s41598-026-38431-9
Parole chiave: denoising video, trasformatore, rumore dell'immagine, video in condizioni di scarsa illuminazione, computer vision