Clear Sky Science · it
Attacco adversariale basato su decisione efficiente in query con basso budget di interrogazioni
Perché piccole imperfezioni nelle immagini possono ingannare macchine intelligenti
L’intelligenza artificiale moderna riconosce volti, animali e oggetti di uso quotidiano con impressionante accuratezza. Tuttavia, questi stessi sistemi possono essere ingannati da modifiche all’immagine così piccole da risultare quasi impercettibili alle persone. Questo articolo esplora un nuovo modo per generare immagini “ingannanti” ponendo al sistema il minor numero possibile di interrogazioni, rivelando sia quanto i modelli attuali possano essere fragili sia come gli aggressori potrebbero sfruttare queste vulnerabilità nel mondo reale.
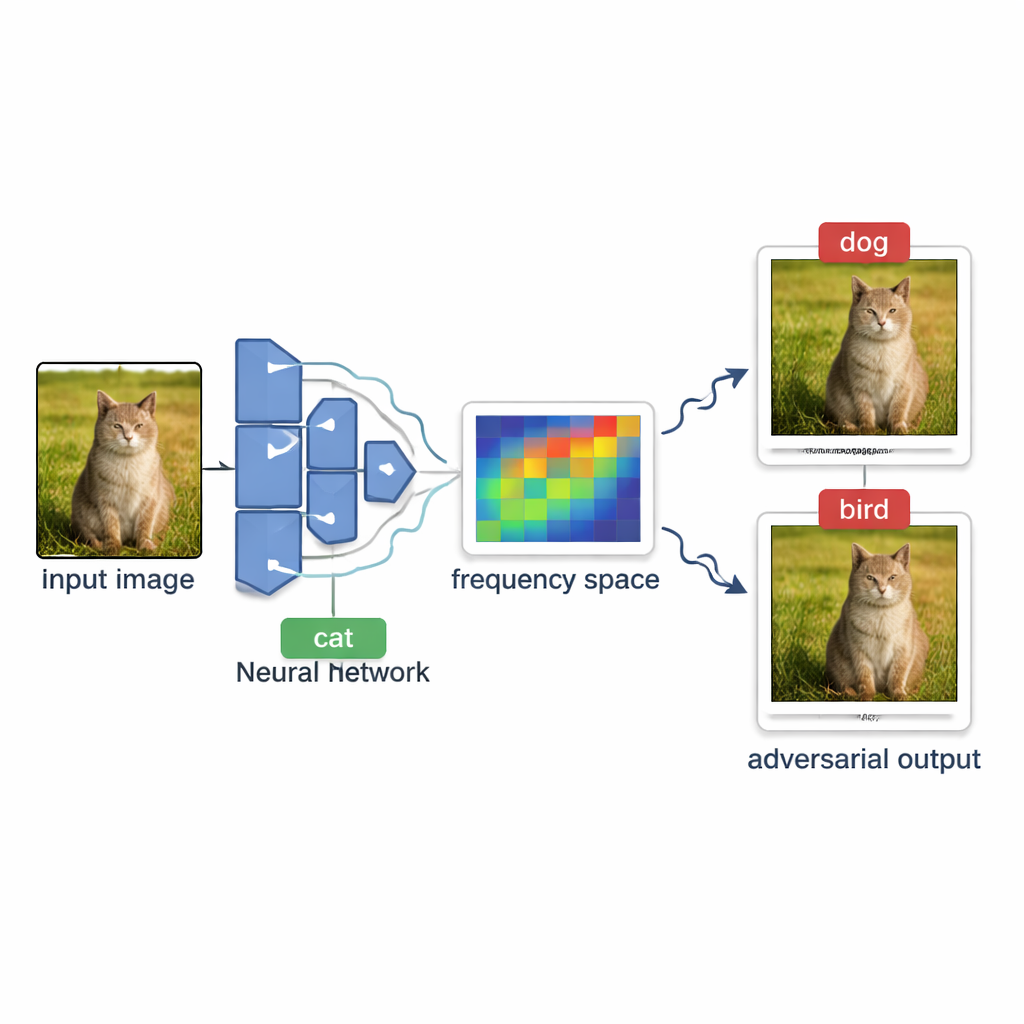
Come gli aggressori sondano i sistemi AI dall’esterno
In molti servizi reali—come il tagging di foto online o i filtri di contenuto—il modello si comporta come una scatola nera. Un estraneo può caricare un’immagine e vedere solo l’etichetta finale, ad esempio “cane” o “segnale di stop”, ma non i punteggi di confidenza interni né la struttura del modello. Creare un’immagine fuorviante in queste condizioni è chiamato attacco black-box basato sulla decisione. La sfida è spingere delicatamente un’immagine normale fino a farle ottenere un’etichetta errata, senza poter vedere quanto sia “vicina” al cambiamento di decisione e senza inviare così tante immagini di prova che il sistema se ne accorga o che le interrogazioni diventino troppo costose.
Un nuovo modo di esplorare con pochissime interrogazioni
Gli autori introducono OPOQA (One Plane One Query Attack), un metodo progettato per essere parsimonioso nelle interrogazioni pur generando immagini adversariali di alta qualità. Invece di sondare ripetutamente lungo un’unica direzione ipotizzata, OPOQA opera in round. In ogni round parte da un’immagine già fuorviante e dall’immagine pulita originale, quindi propone diversi nuovi candidati che giacciono in direzioni scelte con cura. Fondamentale è che ogni direzione venga sondato al massimo una volta, il che libera il limitato budget di interrogazioni per esplorare molte più possibilità anziché perfezionare eccessivamente un singolo tentativo.
Cavalcare le onde lente nell’immagine
Per scegliere direzioni promettenti, OPOQA sfrutta l’idea che le modifiche più efficaci e difficili da vedere siano spesso ampie e lisce, piuttosto che rumore brusco a livello di pixel. Il metodo usa uno strumento matematico chiamato trasformata discreta del coseno per spostare l’immagine in una visuale “in frequenza”, dove le variazioni lente e dolci si concentrano in una regione compatta. Campiona casualmente alcuni di questi componenti a bassa frequenza, li converte nuovamente in normali variazioni di pixel e li usa come direzioni di base per l’esplorazione. Ciascuna direzione campionata aiuta a definire una superficie bidimensionale piatta che collega l’immagine originale, l’attuale immagine adversariale e un nuovo candidato. Su ciascuna di queste superfici, OPOQA seleziona un unico punto da testare, bilanciando due obiettivi: avvicinarsi all’immagine originale pur avendo buone probabilità di indurre il modello in una decisione sbagliata.

Scegliere il migliore candidato e adattarsi sul momento
Una volta che OPOQA ha generato un piccolo insieme di immagini candidate, misura quanto ciascuna si discosta dall’immagine originale e le ordina dal cambiamento minore a quello maggiore. Poi interroga il modello in quell’ordine. Nel momento in cui trova un candidato che il modello classifica erroneamente, si ferma e considera quell’immagine il nuovo punto di partenza per il round successivo. Se nessuno dei candidati riesce a ingannare il modello, OPOQA mantiene la migliore immagine adversariale precedente ma regola una manopola interna che controlla quanto conservativi o aggressivi saranno i passi successivi. Questa strategia “greedy”—accettare sempre la migliore immagine mal classificata disponibile e adattare dinamicamente la dimensione del passo—permette all’attacco di avvicinarsi a perturbazioni sottili ed efficaci senza sprecare interrogazioni su direzioni poco promettenti.
Cosa rivelano gli esperimenti sui punti deboli dell’AI
I ricercatori hanno testato OPOQA su 200 immagini del grande benchmark ImageNet e su sei modelli di rete neurale ampiamente usati, tra cui Inception-v3, ResNet, VGG, DenseNet e i transformer per la visione. Con un limite rigido di 1.000 interrogazioni per immagine, OPOQA ha eguagliato o superato diversi metodi d’attacco di punta. Per esempio, su Inception-v3 è riuscito a ingannare il modello sul 94 percento delle immagini, mantenendo le modifiche così piccole da risultare quasi invisibili all’occhio umano, migliorando il metodo precedente di diversi punti percentuali. Nel complesso, OPOQA tendeva a raggiungere tassi di successo elevati prima—usando meno interrogazioni—sebbene alcuni metodi concorrenti lo recuperassero o lo superassero quando venivano concessi budget di interrogazioni molto ampi e tempo per il perfezionamento.
Cosa significa questo per la sicurezza dell’AI nella vita quotidiana
Lo studio mostra che i sistemi di visione odierni possono essere ingannati anche quando gli aggressori vedono solo le decisioni finali e hanno opportunità limitate di sondare il modello. Esplorando in modo intelligente cambiamenti gentili e a bassa frequenza e razionando attentamente ogni interrogazione, OPOQA può creare immagini che appaiono identiche alle persone ma che portano le macchine fuori strada. Per i non esperti, la conclusione è che la “visione” dell’AI è ancora piuttosto fragile: può essere deviata in modi sottili e difficili da notare. Riconoscere e studiare attacchi così efficienti è un passo fondamentale per rafforzare i sistemi reali—come telecamere di sicurezza, strumenti di imaging medico e veicoli autonomi—contro manipolazioni che altrimenti potrebbero passare inosservate.
Citazione: Tuo, Y., Yin, M. & Che, S. Query-efficient decision-based adversarial attack with low query budget. Sci Rep 16, 6886 (2026). https://doi.org/10.1038/s41598-026-38428-4
Parole chiave: esempi adversariali, attacchi black-box, sicurezza del deep learning, classificazione delle immagini, attacco efficiente in query