Clear Sky Science · it
Valutazione della suscettibilità alle inondazioni mediante tre tecniche di machine learning e confronto delle loro prestazioni
Perché il rischio di alluvione in un bacino etiope è importante
Le inondazioni uccidono migliaia di persone ogni anno nel mondo, distruggono colture e danneggiano case e strade. Nel bacino idrografico di Choke, in Etiopia, una regione di altopiano che alimenta il Nilo Azzurro, le inondazioni lampo arrivano rapidamente e spesso senza preavviso. Questo studio mostra come tecniche informatiche moderne possano trasformare immagini satellitari, mappe e registri pluviometrici in mappe dettagliate del rischio di inondazione, aiutando comunità e pianificatori a decidere dove costruire, dove coltivare e dove proteggere le persone prima che arrivi la prossima tempesta.

Un paesaggio montano sotto pressione
Il bacino di Choke si trova negli altopiani del nord-ovest dell’Etiopia, dove montagne ripide danno origine a oltre 60 fiumi e a centinaia di sorgenti. Questo terreno accidentato sostiene agricoltura, energia idroelettrica, approvvigionamento idrico e persino turismo, ma convoglia anche forti piogge stagionali in valli strette e piane d’inondazione. Nell’ultimo decennio inondazioni ripetute hanno danneggiato campi, strade, ponti, scuole e abitazioni, soprattutto durante la stagione delle piogge principale da giugno a settembre. Crescita della popolazione, deforestazione e l’espansione dei centri urbani hanno modificato la superficie del suolo, rendendola spesso meno capace di assorbire l’acqua e più incline a trasferire improvvisi picchi di deflusso a valle.
Trasformare mappe e misure in una storia delle inondazioni
Per capire dove le inondazioni colpiscono più spesso, i ricercatori hanno prima costruito un “inventario” delle inondazioni per il bacino. Hanno combinato rapporti governativi sulle catastrofi, informazioni di campo e immagini radar dei satelliti Sentinel-1, in grado di rilevare aree allagate anche attraverso le nuvole. Per cinque anni con inondazioni significative tra il 2005 e il 2020, hanno confrontato immagini prese prima e dopo gli eventi per individuare le zone sommerse. Hanno inoltre utilizzato dati di elevazione per rimuovere laghi permanenti e pendii ripidi che non ospiterebbero acque stazionarie. Da questo hanno assemblato un insieme bilanciato di luoghi che erano stati allagati e altri rimasti asciutti, formando il materiale di apprendimento per i loro modelli computazionali.
Leggere il territorio per prevedere le inondazioni future
Successivamente, il team ha raccolto undici tipi di informazioni che influenzano dove l’acqua si accumula, inclusi altezza del terreno, pendenza, curvatura dei versanti, tendenza all’umidità del suolo, reti fluviali, distanza dai canali, precipitazioni, tipo di suolo e uso del territorio. Tutti questi elementi sono stati elaborati in strati cartografici corrispondenti in un sistema informativo geografico. I modelli sono stati addestrati a riconoscere pattern che collegano questi strati alle inondazioni passate. In vari test, tre caratteristiche sono emerse come particolarmente importanti: elevazione, pendenza e un indice di umidità che riflette quanto facilmente l’acqua si accumula in determinati punti. Le aree basse con pendenze dolci e alti valori di umidità si sono rivelate chiare zone calde per le inondazioni, mentre l’esposizione (la direzione del versante) e persino la variabilità delle piogge hanno avuto meno peso in questo particolare contesto montano.
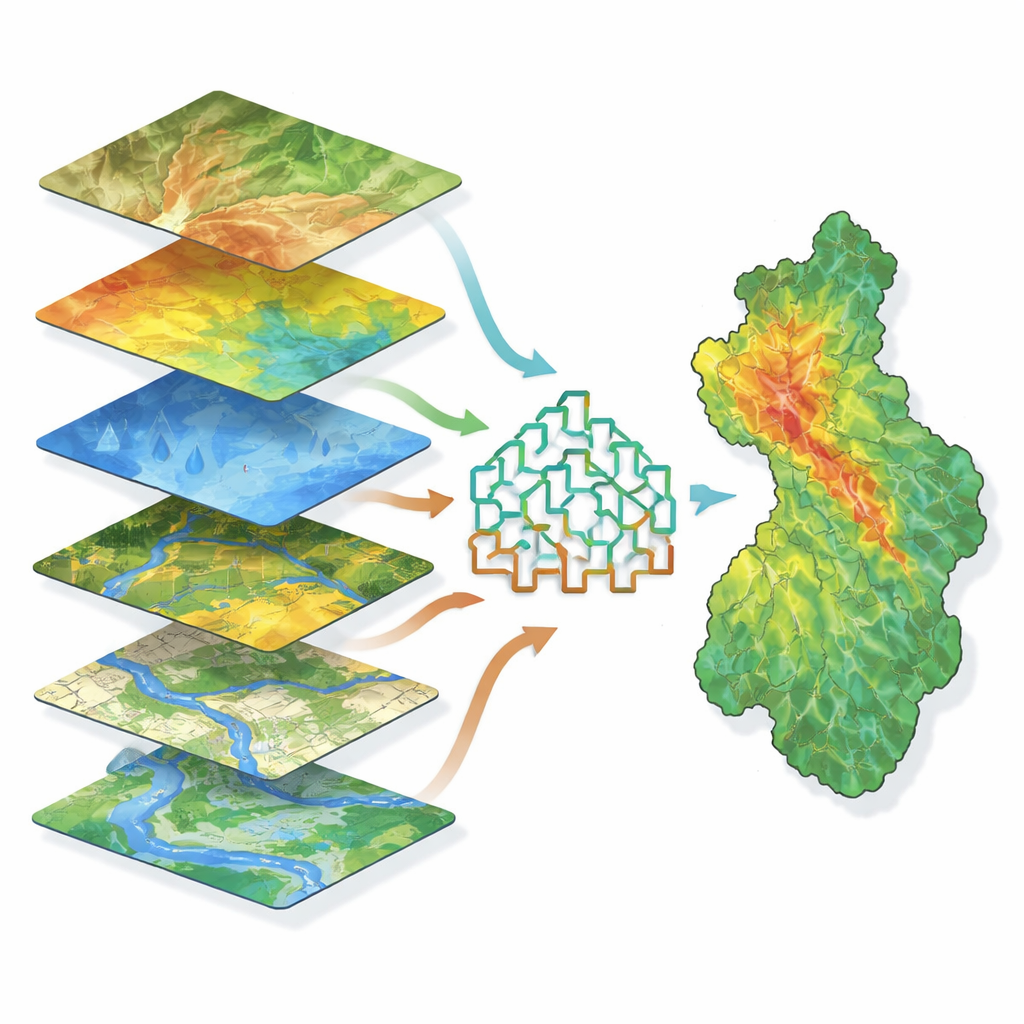
Addestrare le macchine a individuare le zone ad alto rischio
Lo studio ha confrontato tre metodi avanzati di machine learning che si basano tutti su un insieme di numerosi alberi decisionali: Random Forest, Gradient Boosting ed Extreme Gradient Boosting. Questi approcci sono efficaci nel gestire relazioni complesse tra molti fattori senza richiedere dati perfetti o formule semplici. Dopo aver diviso i dati in gruppi per l’addestramento e per il test, gli autori hanno ottimizzato ogni modello e verificato le prestazioni usando diversi punteggi statistici. Due dei metodi, Gradient Boosting ed Extreme Gradient Boosting, si sono dimostrati particolarmente accurati, distinguendo correttamente punti allagati da non allagati in circa il 97% dei casi; Random Forest è risultato subito dopo. Tutti e tre hanno prodotto mappe di suscettibilità alle inondazioni che hanno suddiviso il bacino in cinque classi da rischio molto basso a molto alto, con le sezioni settentrionali e sud-occidentali che mostrano il pericolo maggiore.
Dalle mappe al computer a comunità più sicure
Per i non specialisti, il risultato chiave è che queste mappe generate dalle macchine trasformano registrazioni sparse e immagini satellitari in un quadro chiaro di dove le acque di piena sono più propense a espandersi. Solo una frazione modesta del bacino di Choke ricade nelle zone a rischio più elevato, ma queste aree coincidono con pianure abitate e terreni agricoli importanti. Le autorità locali possono usare i risultati per orientare dove collocare nuove abitazioni, rafforzare ponti e drenaggi o ripristinare la vegetazione per rallentare il deflusso. Pur non potendo i modelli sostituire dettagliate simulazioni idrauliche, offrono un modo rapido ed economico per concentrare risorse limitate nelle aree più vulnerabili e potrebbero essere adattati ad altri rischi come frane o terremoti. In un paese dove dati e bilanci sono spesso scarsi, questa combinazione di satelliti e algoritmi intelligenti offre una strada pratica verso paesaggi e comunità più resilienti.
Citazione: Asrade, T., Abebe, S., Tadesse, K. et al. Flood susceptibility assessment using three machine learning techniques and comparison of their performance. Sci Rep 16, 8099 (2026). https://doi.org/10.1038/s41598-026-38391-0
Parole chiave: suscettibilità alle inondazioni, machine learning, Choke Watershed, telerilevamento, riduzione del rischio di catastrofi