Clear Sky Science · it
MDI-YOLO: un modello di fusione di feature multidimensionali leggero basato su transformer e CNN per il rilevamento di piccoli oggetti
Occhi più acuti nel cielo
Dal monitoraggio del traffico alla risposta alle emergenze, droni e satelliti osservano sempre di più il nostro mondo. Tuttavia le cose che contano maggiormente in queste immagini—piccole auto, persone, barche e velivoli—spesso compaiono come pochi pixel. L’articolo su MDI‑YOLO affronta una domanda semplice ma cruciale: come possono i computer individuare in modo affidabile questi oggetti minuscoli in tempo reale, anche su dispositivi a bassa potenza trasportati dagli stessi droni?
Perché i piccoli oggetti sono difficili da individuare
In viste aeree e satellitari, gli oggetti d’interesse sono di solito molto piccoli, spesso molto vicini tra loro e parzialmente nascosti da edifici, alberi o ombre. I sistemi di rilevamento standard affrontano un compromesso: i modelli leggeri sono veloci sui dispositivi edge come i computer di bordo dei droni ma perdono molti piccoli bersagli; i modelli più pesanti e accurati sono troppo lenti e affamati di risorse per essere pratici sul campo. I piccoli oggetti tendono inoltre a confondersi con sfondi complessi—pensate a automobili grigie su strade grigie—così le loro caratteristiche distintive possono facilmente scomparire quando le immagini vengono compresse e elaborate da reti profonde.
Una nuova miscela di visione globale e locale
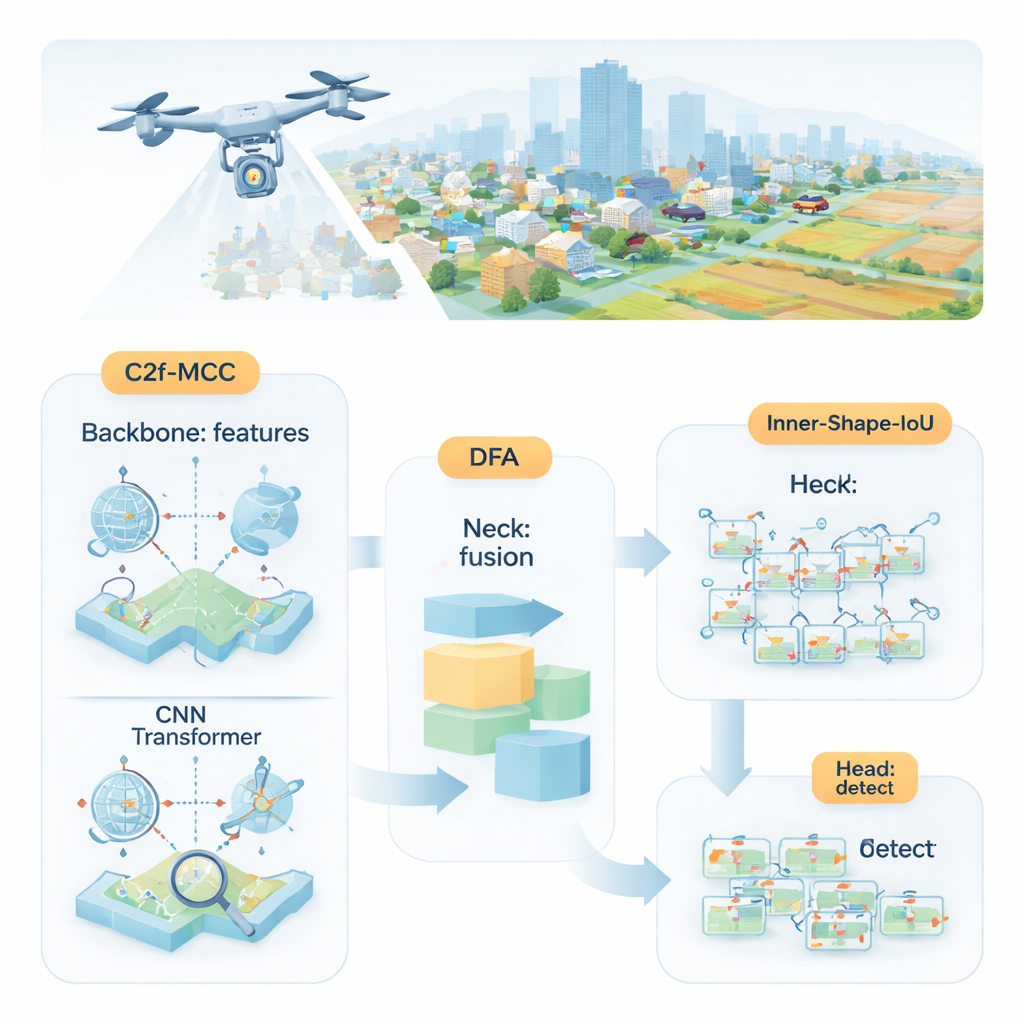
I ricercatori propongono MDI‑YOLO, una versione riprogettata del popolare rilevatore YOLOv8 che mantiene il modello compatto rafforzando la capacità di trovare bersagli minuscoli. Al centro c’è un nuovo blocco di costruzione chiamato C2f‑MCC, che divide le informazioni visive che scorrono nella rete in due percorsi. Un percorso usa elaborazione in stile Transformer, che è efficace nel catturare relazioni a lungo raggio su tutta l’immagine—per esempio come un gruppo di pixel si inserisce in una strada o una pista più ampia. L’altro percorso resta sui filtri convoluzionali classici, ottimi per cogliere dettagli locali come bordi e texture. Raggruppando i canali e inviando solo una parte dei dati attraverso il percorso Transformer più pesante, il modello acquisisce consapevolezza globale senza aumentare eccessivamente le dimensioni né rallentare.
Aiutare la rete a concentrarsi sulle cose importanti
Anche con blocchi migliorati, la rete deve ancora decidere dove porre attenzione. Per guidarla, gli autori introducono un meccanismo chiamato Directional Fusion Attention (DFA). Questo modulo osserva pattern lungo larghezza e altezza dell’immagine, oltre a un riassunto complessivo della scena, e impara a pesare diverse regioni e canali di feature. In pratica, DFA spinge il modello a concentrarsi sulle aree più probabili per gli oggetti—come macchie a forma di veicolo sulle strade—e a ridurre l’importanza di texture di sfondo ripetitive o fuorvianti. Questa combinazione di attenzione spaziale e per canale facilita la separazione di piccoli bersagli da ambienti affollati o da regioni di sfondo simili.
Tracciare box più precisi attorno ai bersagli minuscoli
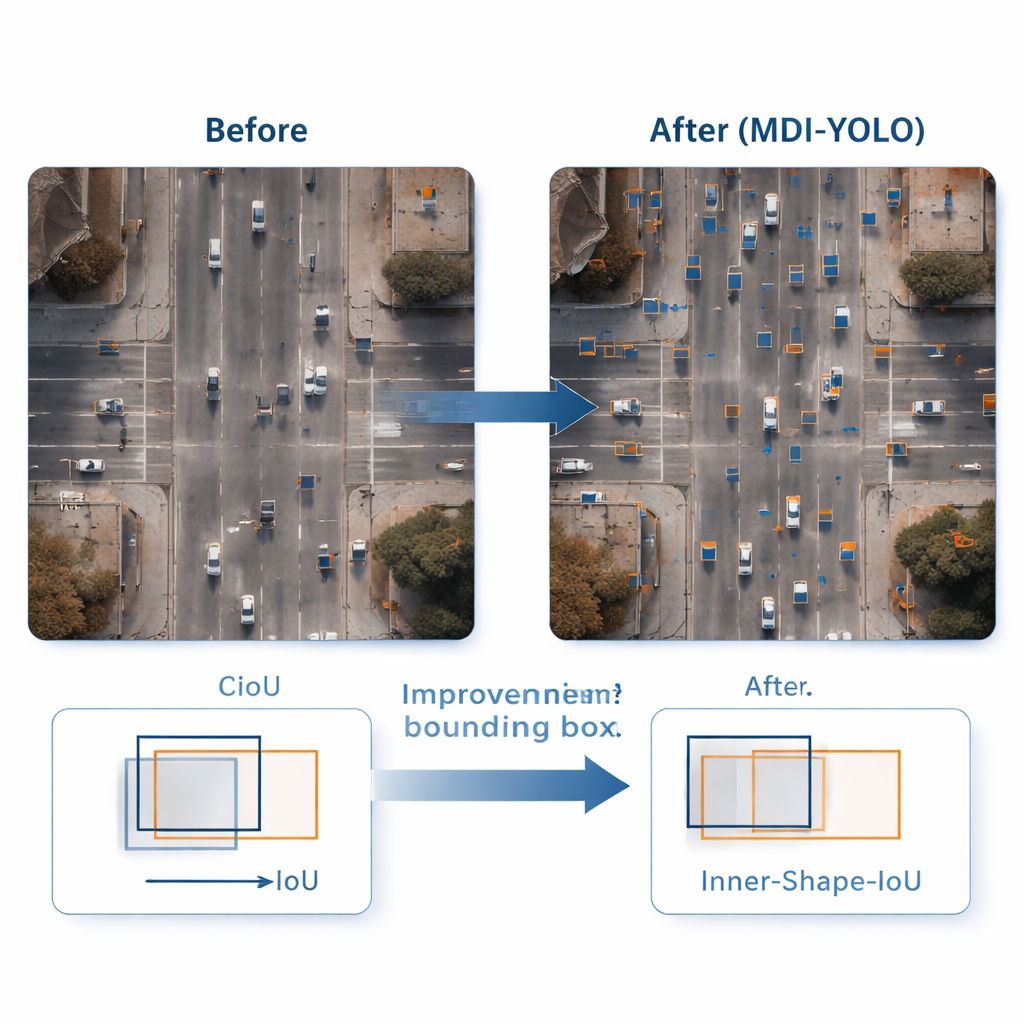
Individuare un oggetto è solo metà del lavoro; il rilevatore deve anche delinearlo con precisione. I metodi di addestramento standard confrontano i rettangoli predetti con quelli reali usando un punteggio di “overlap”, ma questo può essere poco sensibile quando gli oggetti sono piccoli o di forma irregolare. Gli autori progettano una nuova funzione di perdita, Inner‑Shape‑IoU, che valuta i box non solo in base all’area di sovrapposizione, ma anche a quanto bene forma, dimensione e regione centrale corrispondono all’oggetto reale. Combinando due misure complementari, penalizza i box che corrispondono solo ai contorni ma perdono il nucleo del bersaglio, portando a contorni più precisi—soprattutto per oggetti piccoli, affollati o allungati.
Benefici dimostrati senza peso aggiuntivo
Per valutare MDI‑YOLO, il team ha condotto esperimenti su due benchmark pubblici impegnativi: VisDrone2019, con filmati da droni di città e traffico, e DOTAv1.0, una grande raccolta di scene aeree con molti oggetti piccoli e densamente raggruppati. Senza fare affidamento su modelli pre‑addestrati, MDI‑YOLO ha migliorato i punteggi di accuratezza standard di diversi punti percentuali rispetto al baseline YOLOv8 mantenendo il numero di parametri quasi invariato e tempi di inferenza rapidi. Rispetto a una gamma di rilevatori popolari—dalle varianti YOLO leggere ai sistemi basati su Transformer più pesanti—ha offerto una combinazione rara di alta accuratezza, basso costo computazionale e robustezza su scene diverse.
Cosa significa per l’uso nel mondo reale
Per i non specialisti, il messaggio è che MDI‑YOLO fornisce ai droni e ai sistemi di telerilevamento “occhi” più nitidi e affidabili senza richiedere computer grandi e energivori. Mescolando in modo intelligente contesto globale, dettaglio locale, attenzione mirata e un modo più discriminante di addestrare i bounding box, il metodo facilita il rilevamento di piccoli oggetti importanti per sicurezza, monitoraggio e mappatura. Questo tipo di visione efficiente e ad alta precisione è un passo chiave verso piattaforme aeree più intelligenti, in grado di operare in modo autonomo, rispondere rapidamente e essere diffuse su larga scala nel mondo reale.
Citazione: Shi, H., Wu, Y., Xu, Y. et al. MDI-YOLO a lightweight transformer-CNN-based multidimensional feature fusion model for small object detection. Sci Rep 16, 7233 (2026). https://doi.org/10.1038/s41598-026-38378-x
Parole chiave: imagery da drone, rilevamento di piccoli oggetti, telerilevamento, YOLO, computer vision