Clear Sky Science · it
Assegnazione delle risorse assistita da DT tramite apprendimento per imitazione generativo-aversario in scenari complessi cloud-edge-end
Autostrade dei dati più intelligenti per l’Internet delle cose
Man mano che città, fabbriche e abitazioni si riempiono di sensori e dispositivi connessi, generano torrenti di dati che devono essere elaborati rapidamente e con affidabilità. Inviare tutto a server cloud lontani può essere troppo lento, mentre i dispositivi minori all’“edge” spesso non dispongono di potenza di calcolo sufficiente. Questo articolo esplora un nuovo modo per instradare e allocare automaticamente risorse di calcolo, storage e rete tra dispositivi, server edge vicini e cloud, in modo che le applicazioni intelligenti rimangano veloci e robuste anche quando le condizioni reali sono disordinate e imprevedibili.
Perché i metodi odierni faticano
I sistemi moderni spesso si basano su deep reinforcement learning, dove un algoritmo impara per tentativi ed errori usando segnali di ricompensa dall’ambiente. Tuttavia, in reti complesse e rumorose quelle ricompense sono difficili da definire e misurare. Se la funzione di ricompensa è errata o distorta da interferenze, il sistema può apprendere comportamenti insicuri o dispendiosi. Molti metodi esistenti assumono inoltre una ricca conoscenza a priori sui modelli di traffico e sul comportamento dei dispositivi, cosa raramente disponibile nelle reti industriali in esercizio. Inoltre, la maggior parte delle soluzioni ottimizza solo un tipo di risorsa alla volta — per esempio la potenza di calcolo — ignorando storage o larghezza di banda della rete, sebbene tutti e tre collaborino a determinare le prestazioni reali.
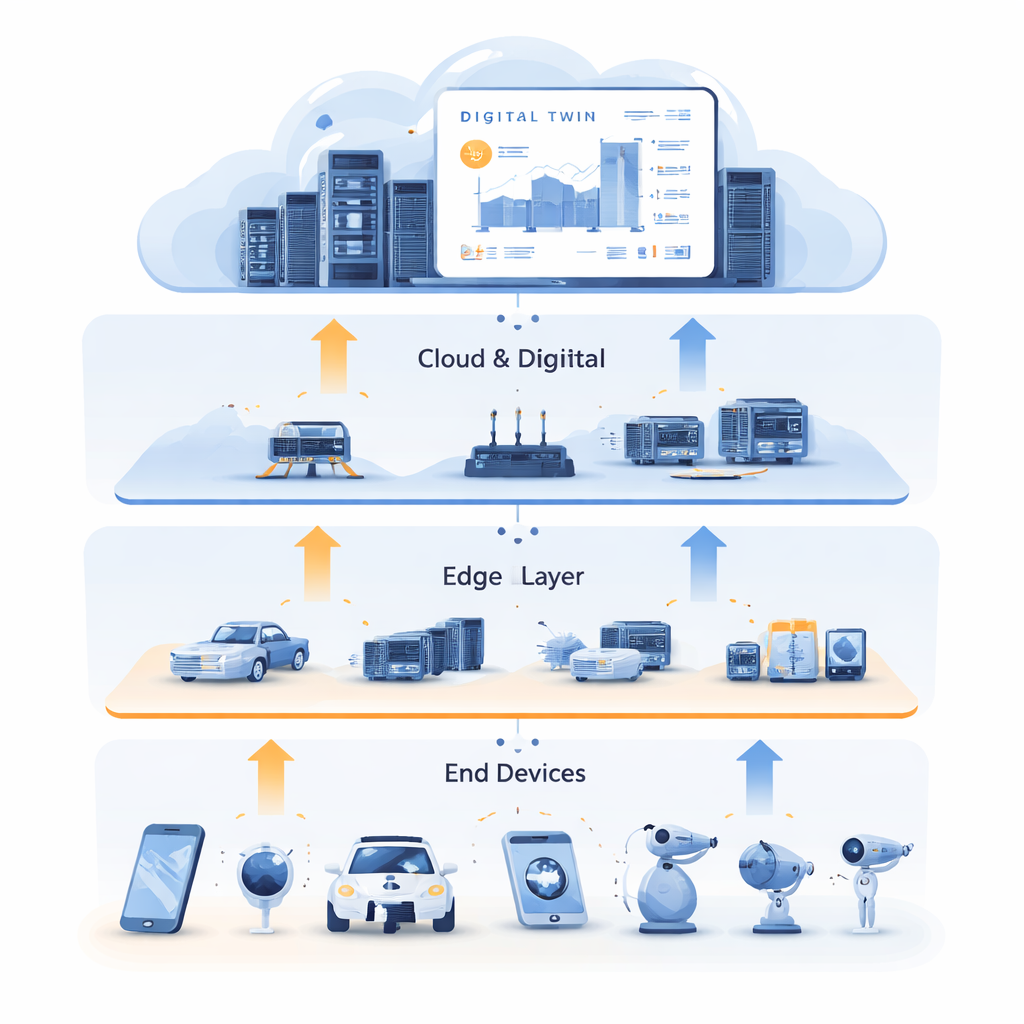
Imparare da un doppio digitale
Per sbloccare questa situazione, gli autori combinano l’allocazione delle risorse con la tecnologia del Gemello Digitale. Un Gemello Digitale è una replica virtuale dettagliata della rete fisica, mantenuta nel cloud. Rispecchia lo stato dei server edge, dei link e dei task nel tempo, usando dati storici ricchi provenienti da sensori e log. In questo lavoro, il Gemello Digitale non è solo una dashboard; diventa un terreno di addestramento. Il sistema usa dati passati per generare esempi “esperti” di buone decisioni, catturando come i compiti dovrebbero essere divisi tra calcolo e caching e dove dovrebbero essere processati per ridurre la latenza. Questo addestramento avviene offline, senza disturbare i servizi live, e sfrutta l’abbondante capacità di calcolo del cloud per esplorare molte possibili situazioni.
Imitazione invece di tentativi ed errori
Piuttosto che imparare direttamente dalle ricompense, il modello proposto E‑GAIL adotta l’apprendimento per imitazione: l’agente cerca di comportarsi come un esperto. Per prima cosa, gli autori costruiscono più politiche esperte usando un framework Actor–Critic potenziato con uno strato NoisyNet. Iniettare rumore controllato nella rete decisionale permette a questi esperti di sperimentare una grande varietà di condizioni — incluse perturbazioni che imitano interferenze wireless reali e carichi di lavoro variabili — in modo che le loro traiettorie siano più realistiche. Successivamente, il sistema fonde diverse traiettorie di singoli esperti in un unico riferimento “multi-esperto” usando strumenti della teoria dei giochi. Cercando un equilibrio di Nash tra gli esperti, si evitano conflitti tra di loro e si ottiene una strategia di consenso con una copertura più ampia di scenari possibili.
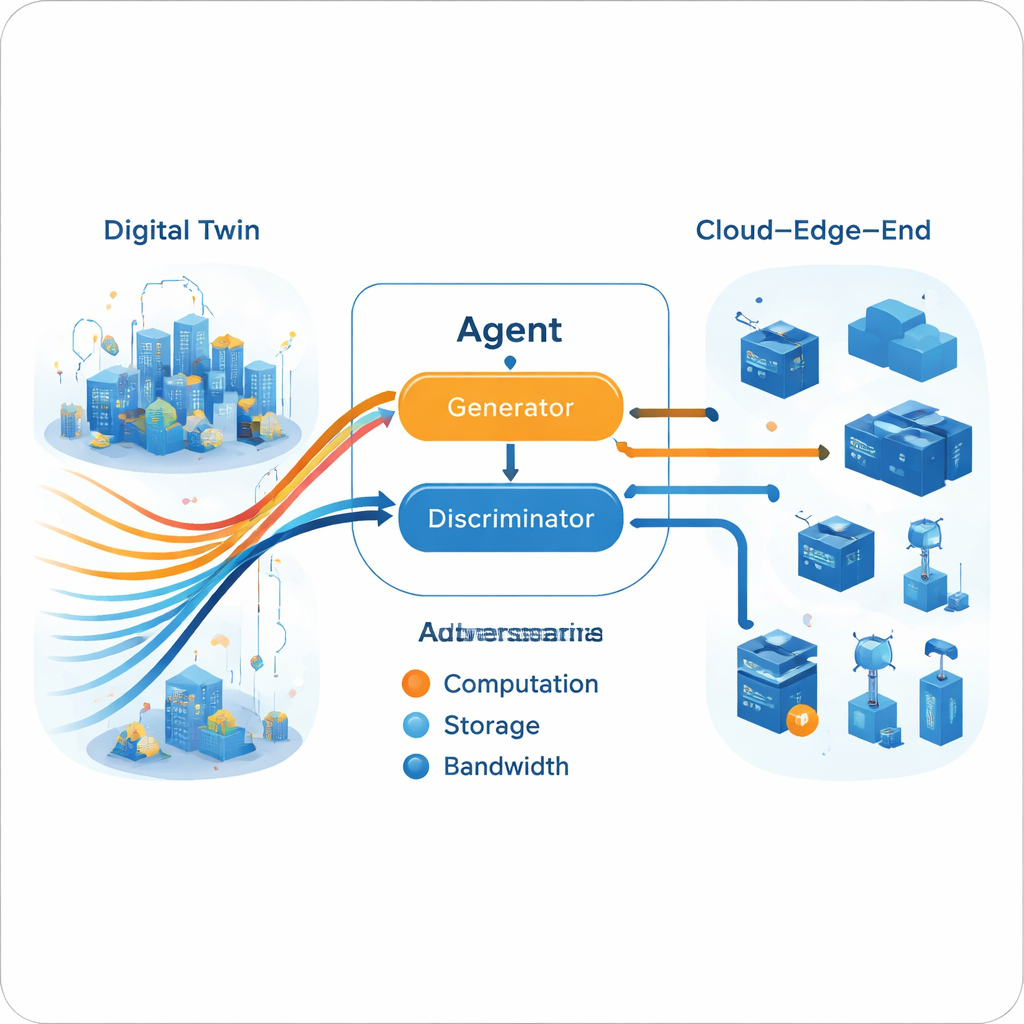
Un motore generativo-aversario per le decisioni
Una volta costruita la traiettoria multi-esperto nel Gemello Digitale, l’agente reale impara a imitarla usando un setup generativo-aversario, simile nello spirito alle reti neurali che generano immagini. Un generatore propone azioni di allocazione delle risorse dato l’attuale stato della rete, mentre un discriminatore cerca di stabilire se una sequenza di azioni provenga dall’agente o dalle traiettorie esperte. Nel tempo, questo gioco avversario spinge il generatore a produrre decisioni che il discriminatore non riesce a distinguere dal comportamento esperto. Crucialmente, questo processo non richiede una funzione di ricompensa esplicita dall’ambiente reale. L’addestramento è suddiviso: un pesante apprendimento offline (nel cloud) affina esperti e generatore, mentre aggiornamenti online più leggeri (all’edge) mantengono il modello allineato con le condizioni correnti, rispettando i limiti pratici dell’hardware edge.
Quanto funziona bene?
Gli autori testano E‑GAIL rispetto a diversi baselines popolari, inclusi deep Q‑learning, offloading basato su teoria dei giochi, euristiche greedy, elaborazione solo cloud e assegnazione casuale. In molti esperimenti — variando il numero di dispositivi terminali, i canali, le miscele di task, i carichi, le dimensioni dei dati, le distanze e i pattern di rumore — E‑GAIL ottiene costantemente latenze end-to-end molto vicine a quelle della politica esperta e sensibilmente migliori rispetto ad altri metodi automatici. Si adatta bene quando i task oscillano tra carico intensivo di calcolo e carico intensivo di storage, quando la rete si espande o quando l’interferenza si intensifica. Il Gemello Digitale accelera la generazione delle traiettorie esperte e ne migliora la qualità, mentre la fusione multi-esperto amplia gli scenari che l’agente può gestire senza dover riaddestrare da zero.
Cosa significa per i sistemi di tutti i giorni
Per un non-specialista, il messaggio chiave è che questo approccio permette alle reti di autogestirsi in modo più intelligente di fronte all’incertezza. Invece di creare regole a mano o affidarsi a un apprendimento per tentativi ed errori fragile, E‑GAIL impara da esperienze simulate ricche fornite da un Gemello Digitale e da più “esperti” affermati il cui consiglio viene riconciliato matematicamente. Il risultato è un allocatore di risorse che può decidere rapidamente dove eseguire i compiti e dove memorizzare i dati, mantenendo basse le latenze anche quando le condizioni cambiano. Nei futuri sistemi industriali e delle smart city, tali coordinatori autoaddestrati potrebbero gestire silenziosamente calcolo, storage e larghezza di banda dietro le quinte, rendendo il nostro mondo connesso più veloce, più affidabile e più efficiente dal punto di vista energetico.
Citazione: Zhang, X., Xin, M., Li, Y. et al. DT-aided resource allocation via generative adversarial imitation learning in complex cloud-edge-end scenarios. Sci Rep 16, 7657 (2026). https://doi.org/10.1038/s41598-026-38367-0
Parole chiave: gemello digitale, edge computing, apprendimento per imitazione, allocazione delle risorse, Internet industriale delle cose