Clear Sky Science · it
Un metodo di fusione end-to-end multiscala per il miglioramento di immagini visibili e infrarosse
Visione notturna più nitida per persone e macchine
Chiunque abbia provato a scattare una foto di notte sa quanto rapidamente il buio cancelli i dettagli: le scene appaiono granulose, sfocate e piene di colori innaturali. Eppure molte tecnologie critiche — dalle telecamere stradali e la sicurezza domestica alle auto a guida autonoma e i droni di soccorso — devono vedere chiaramente proprio in queste condizioni. Questo articolo presenta un nuovo modo di combinare le fotocamere a colori ordinarie con sensori a infrarossi termici in modo che i computer, e in ultima istanza le persone, possano ottenere immagini luminose e dettagliate del mondo anche nel quasi totale buio.
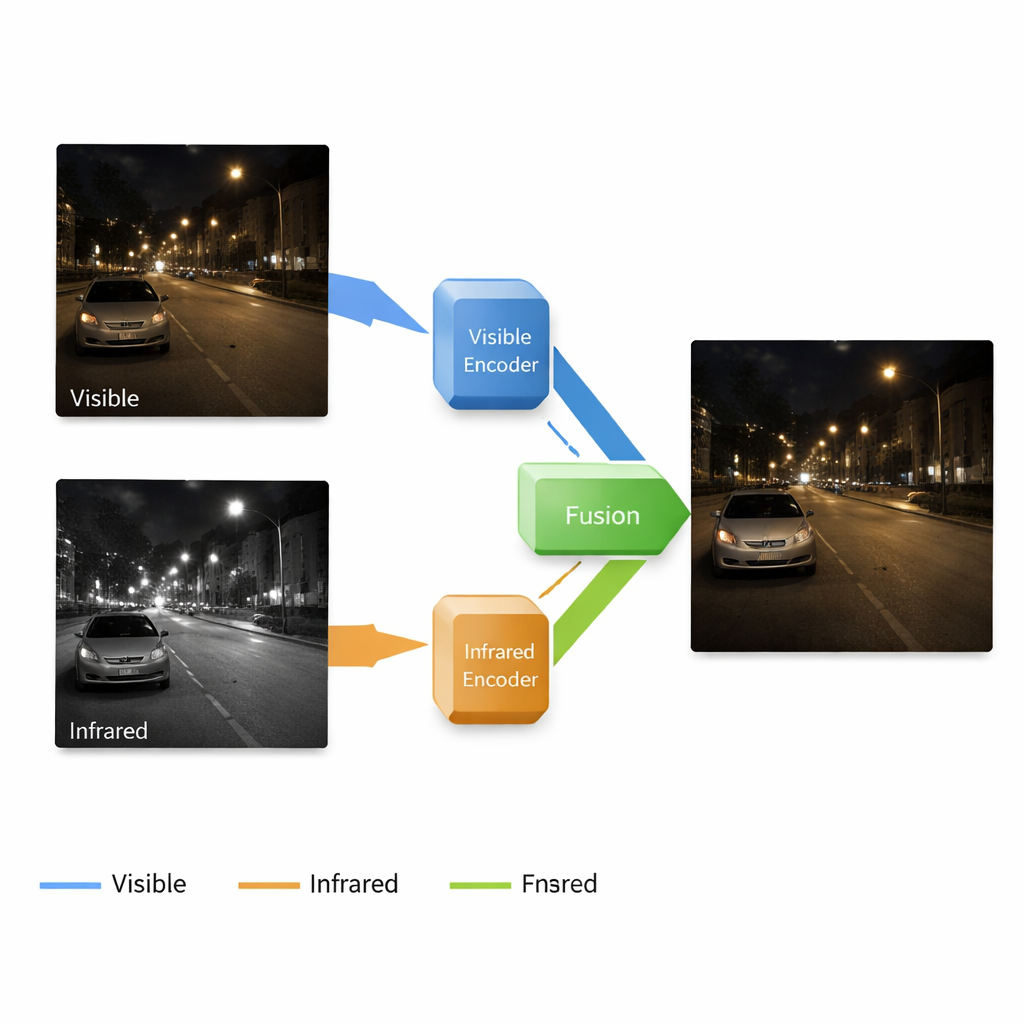
Perché due tipi di fotocamere sono meglio di una
Le fotocamere standard catturano lo stesso tipo di luce che vedono i nostri occhi, il che rende le loro immagini facili da interpretare per gli esseri umani, ma peggiorano notevolmente quando la luce scarseggia: le ombre inghiottono i dettagli, compare il rumore e i colori si spostano. Le fotocamere a infrarossi fanno l’opposto: rilevano i modelli di calore, rivelando persone, animali e veicoli al buio o attraverso una leggera foschia, ma le loro immagini mancano di texture fini e di un aspetto naturale. I ricercatori hanno a lungo cercato di fondere queste due viste in una singola immagine che assomigli a una foto a colori chiara ma che evidenzi comunque gli oggetti caldi nascosti. I metodi esistenti, tuttavia, spesso trattano ogni fase — l’illuminazione delle immagini scure, la pulizia dal rumore e l’integrazione delle informazioni infrarosse — come compiti separati. Questo approccio a pezzi può causare incoerenze feature e risultati di fusione deludenti.
Una pipeline unica che illumina e fonde
Gli autori propongono un sistema end-to-end che migliora e fonde le immagini in un’unica pipeline continua. È costruito attorno a una rete neurale con quattro parti principali: un ramo impara a pulire e schiarire le immagini a colori in condizioni di scarsa luce, un altro ramo impara a rappresentare la scena dalla fotocamera infrarossa, un blocco di fusione combina ciò che ogni ramo ha appreso e un decoder ricostruisce un’immagine finale da questi segnali combinati. È importante che il sistema lavori su più scale, dalle forme grossolane fino alle texture fini. I livelli superficiali preservano i bordi e i dettagli di superficie come mattoni o segnali stradali, mentre i livelli più profondi catturano strutture più ampie — edifici, automobili o alberi — e la posizione dei bersagli caldi nell’immagine infrarossa.
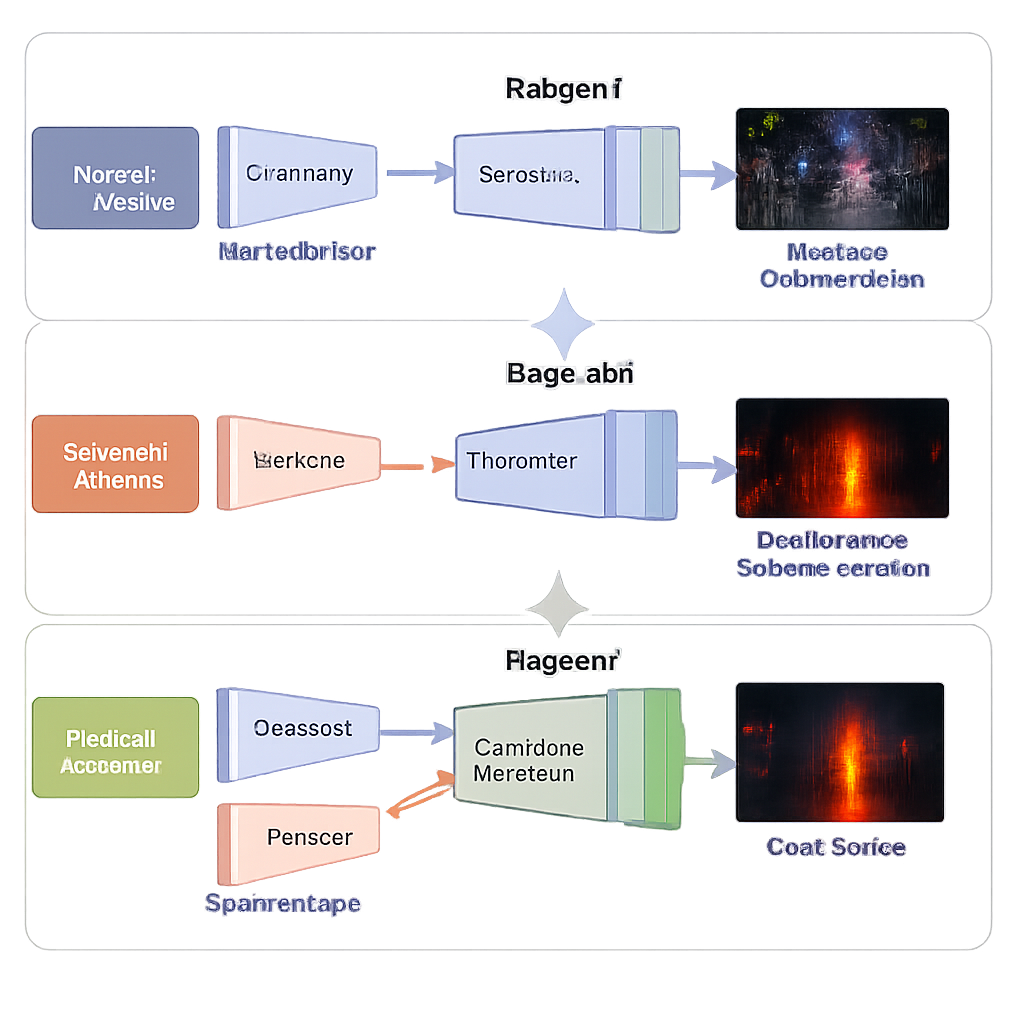
Tre fasi di apprendimento invece di un unico grande salto
Piuttosto che addestrare tutto il sistema in una volta, il team utilizza una strategia di apprendimento in tre fasi progettata per stabilità e accuratezza. Nella prima fase, la rete vede solo foto in luce visibile scure e impara a schiarirle senza immagini di riferimento “perfette” fornite dall’uomo. Termini di perdita scelti con cura spingono l’output ad avere luminosità naturale, colori stabili, regioni lisce senza macchie di rumore e texture preservata. Nella seconda fase, lo stesso decoder viene riutilizzato mentre un nuovo ramo infrarosso impara a ricostruire fedelmente le immagini infrarosse, insegnando alla rete come dovrebbero apparire i pattern di calore. Nella terza fase, tutte quelle parti apprese vengono congelate e viene addestrato solo il blocco di fusione per combinare le due rappresentazioni in un’unica immagine di alta qualità, sia luminosa che ricca di informazioni.
Messa alla prova del metodo
I ricercatori hanno valutato il loro approccio su dataset pubblici contenenti immagini visibili e infrarosse accoppiate scattate in condizioni di illuminazione difficili, come strade notturne. Lo hanno confrontato con diverse tecniche di fusione di punta, incluse quelle basate su trasformate classiche dell’immagine, reti convoluzionali standard e modelli generativi più complessi. Il loro metodo ha generalmente fornito dettagli più nitidi, luminosità più uniforme e bersagli termici più chiari, oltre a ottenere punteggi superiori su misure quantitative di contenuto informativo, nitidezza dei bordi, similarità strutturale e contrasto. Esperimenti aggiuntivi, in cui hanno rimosso selettivamente componenti chiave del sistema, hanno mostrato che ciascuna parte — il blocco di fusione multiscala, l’addestramento a fasi e la ponderazione adattiva delle caratteristiche visibili rispetto a quelle infrarosse — contribuisce in modo misurabile alla qualità finale.
Cosa significa questo per i sistemi di visione nel mondo reale
Per i non specialisti, la conclusione è semplice: questo lavoro mostra che una singola rete accuratamente addestrata può sia schiarire scene scure sia fondere in modo intelligente viste di calore e colore in un’unica immagine coerente. Le immagini fuse preservano le texture fini pur evidenziando gli oggetti caldi, rendendole molto più utili per compiti come la sorveglianza notturna, l’assistenza alla guida e la realtà aumentata o virtuale in ambienti poco illuminati. Sebbene gli autori osservino alcune questioni ancora aperte — come il contrasto ridotto in regioni molto luminose e la necessità di modelli più veloci e leggeri — il loro approccio rappresenta un passo significativo verso sistemi di fotocamere che vedono in modo affidabile nel buio, in modo che appaia naturale e interpretabile per gli utenti umani.
Citazione: Xin, Y., Huang, J., Sun, C. et al. A multi-scale end-to-end visible and infrared image enhancement fusion method. Sci Rep 16, 7135 (2026). https://doi.org/10.1038/s41598-026-38323-y
Parole chiave: miglioramento di immagini in condizioni di scarsa illuminazione, fusione di immagini infrarosse, visione notturna, imaging multisensore, visione con apprendimento profondo