Clear Sky Science · it
Potatura della foresta di alberi e riecampionamento per problemi di classi sbilanciate
Perché i casi rari contano nelle previsioni intelligenti
Molte decisioni basate sull’intelligenza artificiale dipendono dall’individuazione dell’evento raro: una transazione con carta di credito fraudolenta, un primo segno di malattia o un guasto pericoloso in una macchina. In questi casi, gli esempi importanti sono molto meno numerosi di quelli ordinari, e la maggior parte degli algoritmi di apprendimento tende a trascurarli. Questo articolo presenta un modo per rendere un metodo popolare, le Random Forest, molto più attento a quei casi rari ma decisivi—rendendo al contempo il modello più snello e più veloce.
Il problema degli esempi non equilibrati
L’apprendimento automatico standard funziona meglio quando i dati sono ben bilanciati—quando ci sono numeri simili di esempi per ciascun risultato. Nella realtà, però, gli eventi rari dominano molti compiti. Per esempio, solo una piccola frazione delle scansioni mediche mostra un tumore e solo una quota minima delle transazioni è fraudolenta. Questo sbilanciamento rende facile per un algoritmo apparire efficace sui fogli di calcolo predicendo per lo più l’esito comune, anche se manca ripetutamente quello raro. Man mano che il divario tra casi comuni e rari cresce, la frontiera decisionale del modello si sposta verso la maggioranza e la classe rara diventa più difficile da riconoscere.
Riequilibrare le scale con campionamento intelligente
I ricercatori spesso cercano di riequilibrare questi dati prima di addestrare i modelli. Un’opzione è ridurre la classe di maggioranza (under-sampling), scartando alcuni casi comuni per pareggiare il numero di rari. Un’altra è copiare o generare esempi rari aggiuntivi (over-sampling), aumentandone la presenza senza perdere dati originali. Un terzo approccio, ibrido, mescola le due idee, eliminando alcuni esempi della maggioranza mentre si potenziano quelli della minoranza. Ogni tattica ha compromessi: ridurre rischia di buttare informazioni utili, mentre duplicare molti esempi può rallentare l’addestramento e provocare overfitting. Gli autori sfruttano tutte e tre le strategie per creare insiemi di addestramento più bilanciati e adattati ai dati a disposizione.
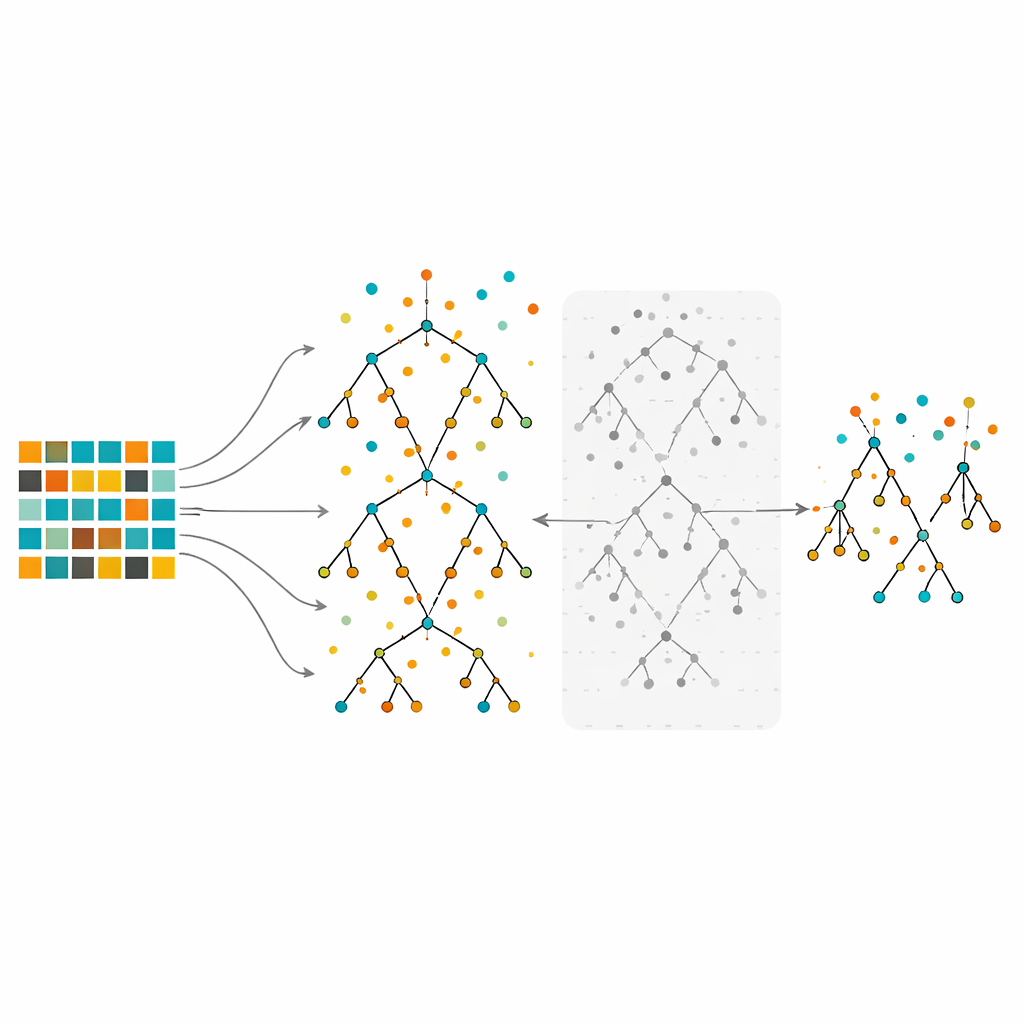
Insegnare e potare una foresta di alberi decisionali
Lo studio si concentra sulle Random Forest, un metodo ensemble che costruisce molti alberi decisionali su porzioni leggermente diverse dei dati e poi combina i loro voti. Le Random Forest sono note per gestire dati complessi e per evidenziare quali caratteristiche sono più importanti. Tuttavia, quando addestrate su dati fortemente sbilanciati, anche foreste estese possono risultare orientate verso la classe di maggioranza. Nel metodo proposto, gli autori prima riequilibrano i dati usando under-sampling, over-sampling o l’approccio ibrido. Quindi coltivano molti alberi usando la procedura tipica delle Random Forest, ma con una svolta importante: invece di mantenere ogni albero, valutano ciascuno usando le osservazioni out-of-bag—punti dati non impiegati per costruire quell’albero particolare—e scartano la metà con i tassi di errore peggiori. Questo passo di potatura produce una foresta più piccola e selettiva costruita dagli alberi più affidabili.
Test su numerosi dataset reali
Per valutare le prestazioni di questa foresta potata, gli autori la testano su dieci dataset pubblici che riflettono un’ampia gamma di applicazioni, dalle misure mediche e biologiche al filtraggio di spam e alla classificazione di suoni. Ogni dataset ha due classi, con una chiaramente più rara dell’altra, e variano per dimensione, numero di caratteristiche e grado di sbilanciamento. Il nuovo metodo viene confrontato con diverse tecniche largamente usate: k-nearest neighbors, un singolo albero decisionale, una Random Forest standard, una variante Balanced Random Forest e macchine a vettori di supporto. Attraverso differenti strategie di campionamento, la foresta potata raggiunge costantemente errori di classificazione inferiori rispetto alle alternative nella maggior parte dei dataset. La combinazione di campionamento ibrido più potatura offre i migliori risultati complessivi, sia in termini di accuratezza sia di prestazioni stabili su tutti e dieci i compiti.
Modelli più affilati che sprecano meno risorse
Oltre all’accuratezza, l’approccio migliora anche l’efficienza. Eliminando gli alberi meno efficaci, l’ensemble finale è più piccolo e richiede meno calcolo per l’addestramento e per le previsioni, senza sacrificare—e spesso migliorando—la capacità di rilevare i casi rari. Test statistici confermano che i guadagni rispetto ai metodi concorrenti non sono dovuti al caso. Per i praticanti che si confrontano con dati sbilanciati, questo lavoro mostra che bilanciare con cura il set di addestramento e poi potare una Random Forest basandosi sulle prestazioni out-of-bag può produrre modelli sia più accurati sia più efficienti. In termini pratici, il metodo aiuta i nostri algoritmi a prestare la giusta attenzione ai segnali rari ma importanti nascosti in un mare di esempi ordinari.
Citazione: Faiz, N., Iftikhar, S., Jan, S. et al. Pruning tree forest and re-sampling for class imbalanced problem. Sci Rep 16, 8087 (2026). https://doi.org/10.1038/s41598-026-38320-1
Parole chiave: sbilanciamento delle classi, random forest, riecampionamento, apprendimento automatico, metodi ensemble