Clear Sky Science · it
Apprendimento federato per sistemi eterogenei di cartelle cliniche elettroniche con selezione dei partecipanti a costo efficace
Perché è così difficile condividere i dati ospedalieri
Gli ospedali moderni raccolgono enormi quantità di informazioni digitali sui pazienti, da esami di laboratorio e segni vitali a farmaci e procedure. In teoria, combinare questi dati tra molte istituzioni dovrebbe permettere ai medici di costruire modelli informatici più intelligenti per prevedere chi è a rischio e quali trattamenti potrebbero essere più utili. In pratica, però, gli ospedali usano software diversi, archiviano i dati in formati incompatibili e devono tutelare rigorosamente la privacy dei pazienti e i budget. Questo studio esplora come permettere agli ospedali di imparare dai dati altrui senza copiarli o spendere troppo.
Allenarsi insieme senza condividere i record grezzi
Gli autori si basano su un approccio chiamato apprendimento federato, in cui ogni ospedale allena un modello locale sui propri record dei pazienti e condivide soltanto gli aggiornamenti del modello, non i dati grezzi. Un ospedale centrale “host” coordina questo processo e mira a migliorare un modello di previsione per le proprie esigenze, per esempio prevedendo complicazioni in terapia intensiva. Altri ospedali, detti soggetti, partecipano in cambio di compensi. Questa impostazione evita lo spostamento di record sensibili tra istituzioni, ma solleva due problemi difficili: come lavorare con molti sistemi di registrazione diversi e come evitare di pagare partner che in realtà non aiutano il modello.
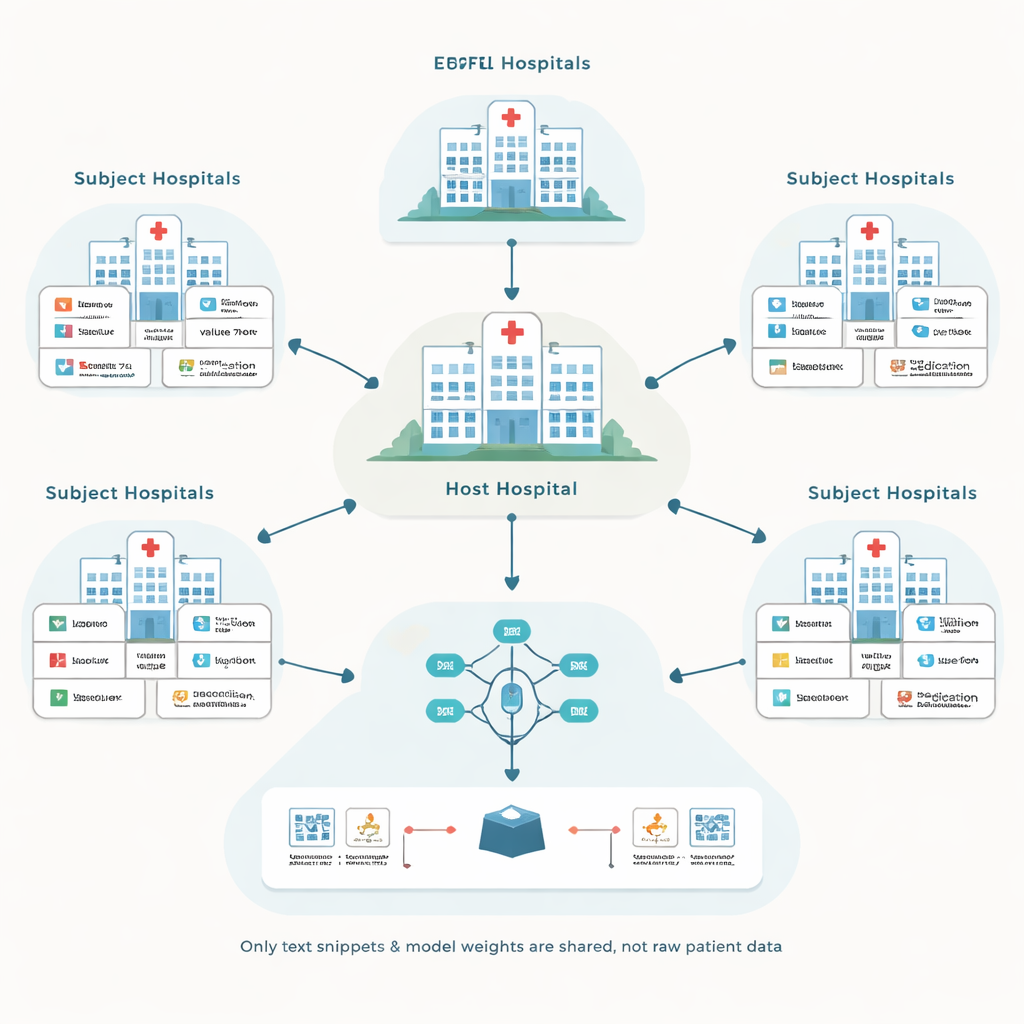
Trasformare record disomogenei in un linguaggio condiviso
I sistemi di cartelle cliniche elettroniche variano ampiamente nel modo in cui etichettano e codificano le informazioni. Un ospedale potrebbe memorizzare un esame del glucosio con un codice numerico, mentre un altro usa un codice diverso per lo stesso test. Le soluzioni tradizionali cercano di convertire tutto in un unico database standard progettato ad hoc, il che è costoso e richiede molte ore di lavoro di esperti. Invece, il framework proposto, chiamato EHRFL, converte ogni evento medico in un breve frammento di testo. Per esempio, una voce di laboratorio come una misurazione della glicemia diventa una frase come “evento di laboratorio glucosio valore 70 mg/dL.” Poiché ogni ospedale mantiene già dizionari che mappano i codici locali a nomi leggibili dall’uomo, questa conversione può essere automatizzata senza interventi manuali su misura.
Costruire profili dei pazienti a partire dal testo
Una volta che gli eventi sono scritti come testo, EHRFL utilizza modelli moderni di elaborazione del linguaggio per trasformare ogni evento in un vettore numerico e quindi combina molti eventi in un’unica “embedding del paziente” — un riassunto compatto della storia medica di quella persona in una finestra temporale. Queste embedding alimentano uno strato di predizione che affronta più compiti clinici contemporaneamente, come prevedere il decesso in ospedale o il danno renale dopo un ricovero in terapia intensiva. Gli autori eseguono l’addestramento federato su cinque grandi dataset reali di terapia intensiva che coprono ospedali, periodi temporali e sistemi di registrazione diversi. Su una gamma di algoritmi, inclusi metodi federati comunemente usati, i modelli addestrati con questo approccio basato su testo sovraperformano costantemente i modelli addestrati su un singolo ospedale, nonostante la diversità dei formati di dati sottostanti.
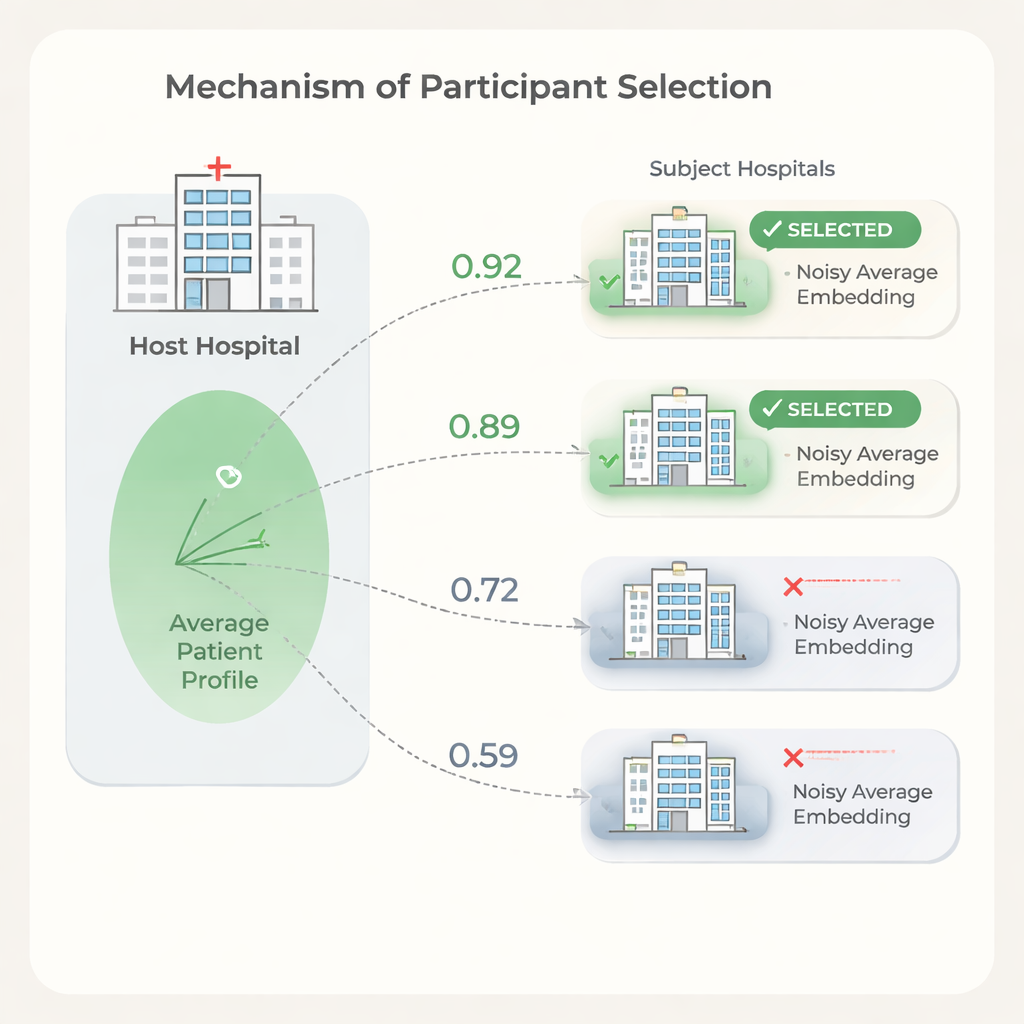
Scegliere i partner giusti proteggendo la privacy
Avere più ospedali partner non implica sempre risultati migliori. Alcune istituzioni hanno popolazioni di pazienti o pattern di registrazione così diversi dall’host che includerli può rallentare l’addestramento o peggiorare leggermente le prestazioni, pur aumentando i costi. Per affrontare questo problema, gli autori propongono un passaggio di selezione basato sulla somiglianza tra le embedding medie dei pazienti degli ospedali. L’host prima allena un modello sui propri dati, condivide i pesi del modello e ogni ospedale candidato li usa per calcolare le embedding dei pazienti. Per proteggere la privacy, ogni soggetto tronca i valori estremi delle proprie embedding, le media in un singolo vettore e poi aggiunge un rumore casuale calibrato prima di inviare soltanto questa media rumorosa all’host. L’host confronta la propria media con quella di ciascun soggetto usando semplici misure di similarità e sceglie solo gli ospedali più simili per partecipare alla sessione federata completa.
Risparmiare senza perdere accuratezza
Gli esperimenti mostrano che la similarità tra le embedding medie dei pazienti degli ospedali si allinea a quanto ciascun ospedale aiuta o danneggia le prestazioni predittive dell’host. Usando questo segnale per selezionare i partner, l’host può escludere gli ospedali a bassa similarità mantenendo o persino migliorando la qualità delle previsioni rispetto all’uso di tutti i siti disponibili. Gli autori delineano anche un modello di costo che mostra come, poiché le tariffe per l’uso dei dati e il tempo di addestramento crescono con il numero di ospedali partecipanti, anche riduzioni modeste nel numero di partner possano portare a risparmi sostanziali. Allo stesso tempo, il passaggio di selezione è leggero: il modello viene addestrato una sola volta e ogni ospedale esegue soltanto calcoli semplici su un unico vettore medio.
Cosa significa per l’IA sanitaria del futuro
Per i lettori non specialisti, il messaggio chiave è che potrebbe essere possibile per gli ospedali “imparare insieme” senza aggregare i record grezzi dei pazienti, e farlo in modo che rispetti sia la privacy sia i vincoli finanziari. Traducendo record eterogenei in una forma testuale condivisa e poi usando riassunti della popolazione dei pazienti che preservano la privacy per scegliere partner compatibili, EHRFL offre una ricetta pratica per costruire strumenti di previsione specifici per gli ospedali. Pur concentrandosi su dati di terapia intensiva, le stesse idee potrebbero estendersi a ambulatori, pronto soccorso e persino domini non medici dove organizzazioni vogliono collaborare per modelli migliori senza cedere il controllo dei propri dati.
Citazione: Kim, J., Kim, J., Hur, K. et al. Federated learning for heterogeneous electronic health record systems with cost effective participant selection. Sci Rep 16, 6876 (2026). https://doi.org/10.1038/s41598-026-38299-9
Parole chiave: apprendimento federato, cartelle cliniche elettroniche, privacy dei pazienti, predizione clinica, IA per la sanità