Clear Sky Science · it
NeuroAction: un approccio neuroevolutivo all’apprendimento per rinforzo per veicoli autonomi
Perché contano stili di guida più intelligenti
La maggior parte di noi immagina le auto a guida autonoma come guidatori calmi e perfettamente razionali. Ma i sistemi odierni tendono a inseguire un unico mix di obiettivi — per esempio non incidentarsi pur arrivando rapidamente — e quel mix è deciso dagli ingegneri. NeuroAction, l’approccio descritto in questo articolo, mira a dare alle auto autonome qualcosa di più vicino alla flessibilità umana: la capacità di scegliere tra molti stili di guida sicuri, dal comportamento cauto “bambino a bordo” alla guida veloce in autostrada, senza dover riaddestrare l’auto ogni volta.
Da una soluzione unica a molte opzioni sicure
I sistemi attuali di deep reinforcement learning per la guida apprendono per tentativi ed errori: osservano la strada, eseguono azioni come sterzare e accelerare, e ricevono un unico premio numerico che fonde insieme diversi scopi come velocità, sicurezza e posizione di corsia. Per modificare il comportamento, gli ingegneri devono progettare quel singolo segnale di ricompensa con grande attenzione. Se danno troppo peso alla velocità, l’auto può guidare in modo aggressivo; se enfatizzano la sicurezza, può muoversi troppo lentamente. Cambiare le preferenze in seguito di solito significa tornare a riaddestrare una grande rete neurale da zero, cosa lenta, che richiede molta memoria e sensibile ai parametri tecnici.
Spezzare la guida in obiettivi semplici
NeuroAction affronta il problema suddividendo il compito di guida in diversi obiettivi chiari invece di uno solo. Nello studio, il conducente virtuale dell’auto viene valutato indipendentemente su tre aspetti: quanto velocemente viaggia entro un intervallo sicuro, quanto fedelmente rimane nella corsia più a destra (tipicamente più sicura) e quanto bene evita le collisioni. Invece di combinare questi aspetti in un unico punteggio, il metodo li tratta come indicatori separati. Dietro le quinte, ogni politica di guida possibile — la rete neurale che trasforma i dati dei sensori in decisioni di sterzata e velocità — viene valutata su tutti e tre gli assi contemporaneamente.
Lasciare che l’evoluzione cerchi guidatori migliori
Invece di ottimizzare i pesi della rete con la tecnica standard del backpropagation, NeuroAction usa idee prese dall’evoluzione biologica. Si crea una popolazione di politiche di guida diverse e le si testa in un ambiente di simulazione autostradale. Le politiche che trovano buoni compromessi tra velocità, disciplina di corsia e sicurezza vengono conservate e ricombinate, mentre le altre vengono scartate. Dopo molte generazioni, questo processo evolutivo scopre un’intera frontiera di soluzioni efficaci — nota come frontiera di Pareto — in cui nessuna politica può essere migliorata su un obiettivo senza compromettere almeno un altro.
Confrontare apprendimento evolutivo e basato sul gradiente
I ricercatori hanno applicato NeuroAction a un simulatore autostradale 2D largamente usato, impiegando un agente di guida standard basato su rete neurale. Hanno quindi ottimizzato i parametri dell’agente con diversi algoritmi evolutivi multi-obiettivo consolidati, confrontando quanto bene ciascuno coprisse la gamma di compromessi desiderabili. Una misura chiave delle prestazioni, l’“ipervolume” della frontiera scoperta, cattura sia quanto sono buone sia quanto sono diverse le soluzioni. Un algoritmo, NSGA-II, ha raggiunto la copertura complessiva migliore, mentre un suo parente stretto, NSGA-III, ha prodotto risultati particolarmente coerenti tra più esecuzioni.
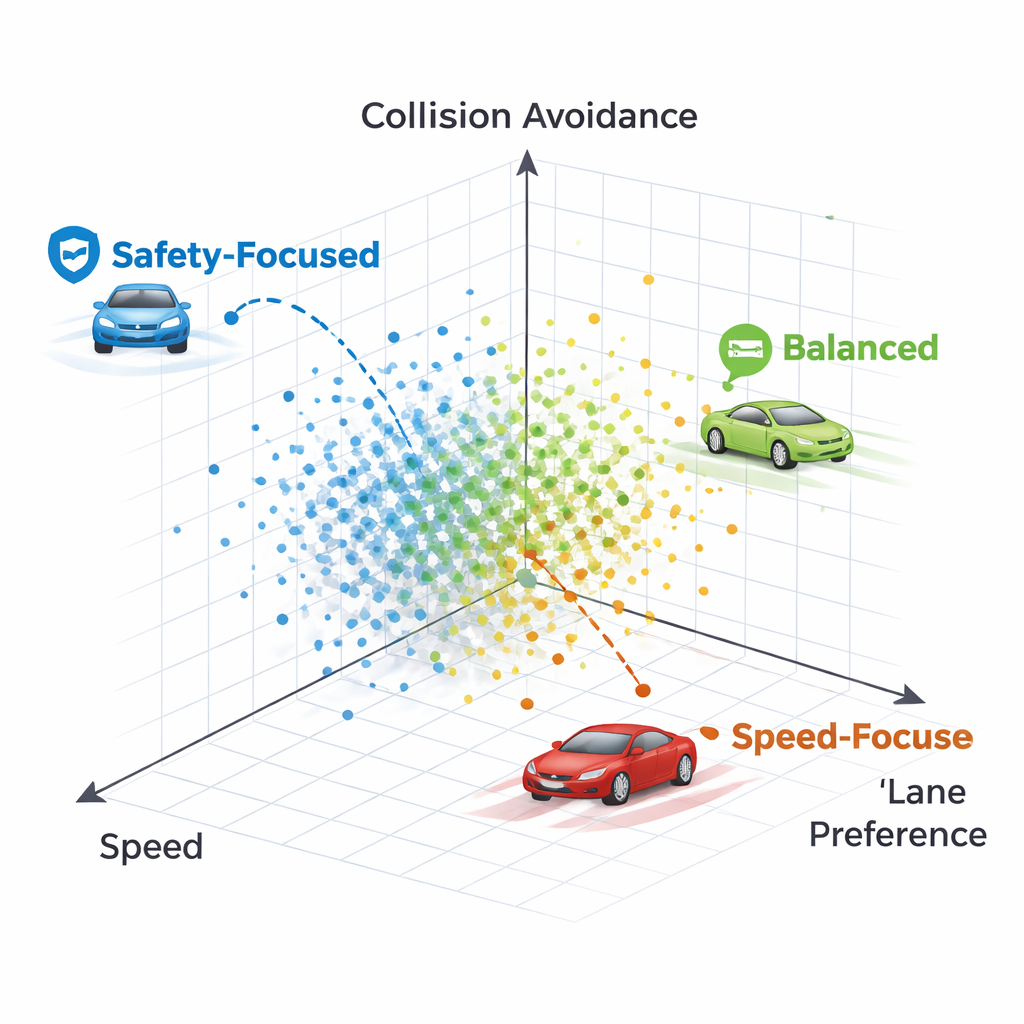
Come appaiono i diversi stili di guida
Ispezionando singole politiche sulla frontiera di Pareto, gli autori mostrano che ogni punto corrisponde a uno stile di guida riconoscibile. Una politica rimane saldamente nella corsia di destra quasi a tutti i costi, sacrificando la velocità e arrivando infine a collidere con un veicolo molto lento davanti — una strategia eccessivamente prudente che dà troppo peso alla preferenza di corsia. Un’altra politica cambia inizialmente corsia ma poi ritorna in una corsia destra libera, mantenendo una velocità più alta pur evitando incidenti. In generale, i metodi producono uno spettro di strategie che vanno da guidatori conservativi, attenti alla corsia, a guidatori più decisi ma comunque sicuri, tutti disponibili contemporaneamente senza riaddestramento.
Cosa significa per le auto a guida autonoma del futuro
Per un non-specialista, il messaggio centrale è che NeuroAction trasforma l’addestramento delle auto a guida autonoma in una ricerca di molte buone opzioni invece che in un comportamento fisso. Questo rende possibile selezionare una politica di guida in base alla situazione — lenta e ultra-sicura quando si trasportano bambini, più veloce quando si è di fretta — pur rispettando vincoli di sicurezza. Sebbene gli esperimenti attuali siano in simulazione e usino obiettivi semplificati, il quadro apre la strada a veicoli autonomi più adattabili e sensibili alle preferenze, in grado di offrire stili di guida personalizzati ma affidabili basati su solide basi matematiche.
Citazione: Aboyeji, E., Ajani, O.S., Fenyom, I. et al. NeuroAction: a neuroevolutionary approach to reinforcement learning for autonomous vehicles. Sci Rep 16, 7403 (2026). https://doi.org/10.1038/s41598-026-38269-1
Parole chiave: guida autonoma, apprendimento per rinforzo, algoritmi evolutivi, ottimizzazione multi-obiettivo, auto a guida autonoma