Clear Sky Science · it
Decomposizione tensoriale senza rango tramite metric learning
Trovare schemi in un mare di dati
La scienza moderna è sommersa da dati complessi: pile di scansioni mediche, mappe di attività cerebrale, immagini astronomiche e simulazioni di materiali. Dare senso a questi dati spesso significa comprimerli in forme più semplici senza perdere ciò che conta davvero. Questo articolo introduce un nuovo modo per farlo. Invece di cercare di ricostruire fedelmente ogni pixel, il metodo si concentra sul catturare le vere relazioni tra i campioni – quale cervello assomiglia a quale, quale forma di galassia richiama un’altra – in modo che la mappa risultante dei dati rifletta il significato piuttosto che il dettaglio bruto.
Dal ricostruire immagini al misurare similarità
Gli strumenti tradizionali per semplificare dati multidimensionali, noti come decomposizioni tensoriali, funzionano un po’ come scomporre un accordo in note. Fattorizzano un “blocco” di dati in un piccolo numero di modelli di base più pesi. Per farlo, devono essere informati a priori su quante componenti – il “rango” – possono usare, e giudicano il successo da quanto bene i dati originali possono essere ricostruiti. Questo è ideale per compressione o denoising, ma non necessariamente per compiti come “questi due volti appartengono alla stessa persona?” o “questa scansione cerebrale appartiene a un soggetto autistico o tipico?”, dove raggruppare correttamente conta più di una ricostruzione perfetta.
Parallelamente, il deep learning ha reso popolare un’altra idea: invece di decomporre un tensore algebraicamente, imparare un codice numerico compatto, o embedding, tramite una rete neurale. I classici autoencoder si concentrano ancora sulla ricostruzione. Questo lavoro ribalta l’obiettivo. Propone un framework “senza rango” che non fissa un rango in anticipo e non si preoccupa della recuperabilità pixel-per-pixel. Invece, impara una misura di distanza in modo che punti che dovrebbero essere vicini (stessa persona, stessa diagnosi, stessa classe fisica) risultino vicini nello spazio di embedding, e punti che dovrebbero essere diversi vengano spinti lontano.
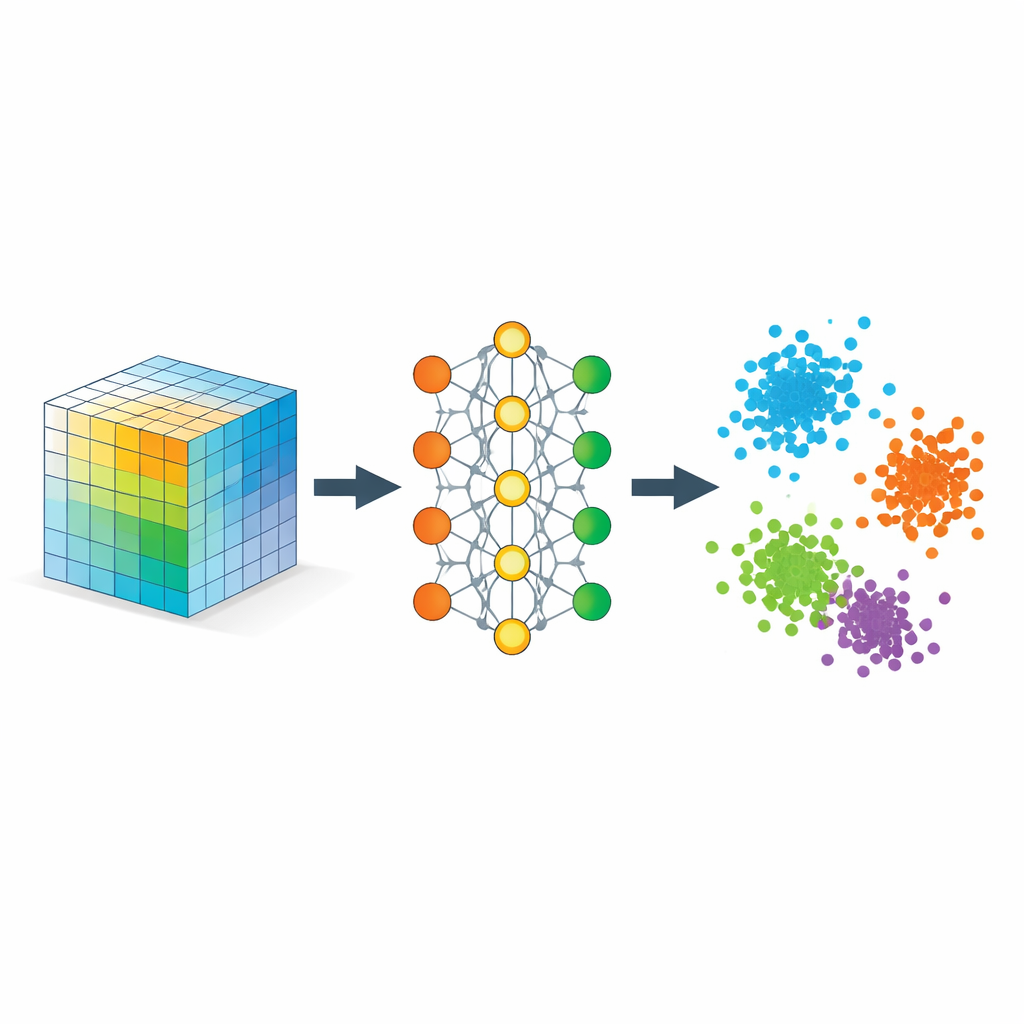
Insegnare alla rete cosa significa “vicino”
L’ingrediente chiave è una strategia chiamata metric learning, qui implementata tramite triplette di esempi: un campione ancoraggio, un campione positivo dello stesso tipo e un campione negativo di tipo diverso. Durante l’addestramento, la rete è premiata quando l’ancora è più vicina al positivo che al negativo per una certa margine di sicurezza. Molte di queste triplette scuotono lo spazio di embedding in modo che le distanze rispecchino la similarità semantica piuttosto che la mera similarità di pixel. Regolarizzatori aggiuntivi incoraggiano la rete a distribuire l’informazione in modo uniforme tra le dimensioni, evitare il collasso su una retta e mantenere i vicinati locali grosso modo intatti, così che punti vicini nei dati originali rimangano vicini anche nell’embedding.
Matematicamente, gli autori mostrano che questo embedding si comporta come una decomposizione tensoriale flessibile, ma senza un rango prefissato. Le coordinate apprese possono essere interpretate come fattori in una decomposizione classica di un tensore di similarità i cui elementi misurano quanto fortemente diverse parti dei dati si allineano. Poiché il modello penalizza direzioni ridondanti, tende a utilizzare efficacemente tutte le dimensioni dell’embedding, lasciando che sia il dato stesso a determinare quante componenti significative servono. Allo stesso tempo, forniscono garanzie teoriche che le procedure di addestramento standard convergono e che la geometria risultante separa fedelmente le classi senza distorcere eccessivamente le relazioni locali significative.
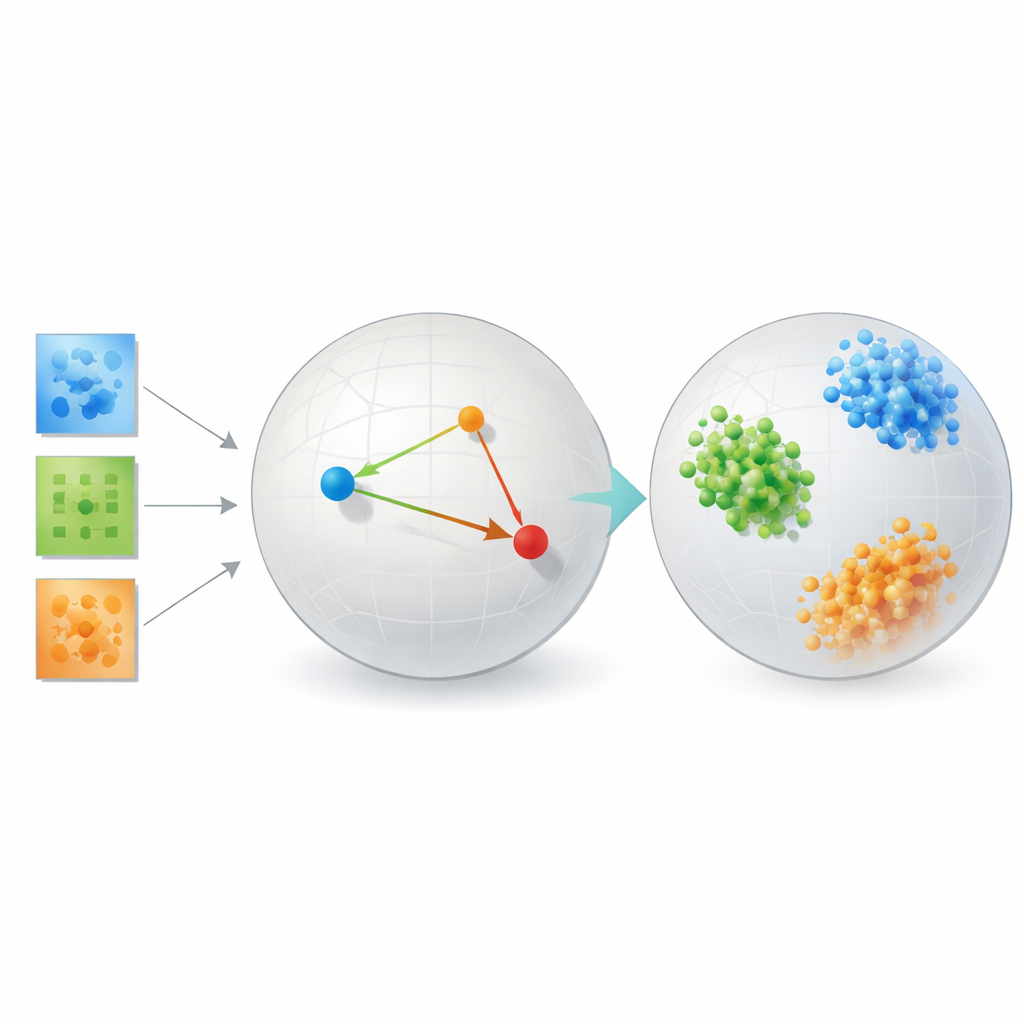
Mettere il metodo alla prova
Per dimostrare che l’approccio non è solo teoria elegante, l’autore lo testa su diversi problemi molto differenti. Nei benchmark di riconoscimento facciale, gli embedding appresi raggruppano immagini della stessa persona in cluster compatti e ben separati, superando nettamente metodi classici come le componenti principali, strumenti di visualizzazione popolari come t-SNE e UMAP, e decomposizioni tensoriali tradizionali che si basano su ranghi fissi. Su dati di connettività cerebrale di persone con e senza autismo, il metodo scopre uno spazio in cui i due gruppi sono separati più chiaramente rispetto agli strumenti tensoriali orientati alla ricostruzione o alle reti autoencoder, suggerendo che stia individuando pattern clinicamente rilevanti nelle interazioni tra regioni cerebrali.
Lo studio include anche simulazioni controllate di forme di galassie e strutture cristalline, dove le categorie “vere” sono note esattamente. Qui, il framework di metric learning clusterizza quasi perfettamente le galassie e i cristalli sintetici in base ai loro tipi fisici sottostanti. In tutti questi contesti, il metodo scambia costantemente un po’ di fedeltà alla disposizione originale dei pixel per una rappresentazione in cui similarità e differenza si allineano con il significato scientifico. È importante che lo faccia senza le enormi risorse di dati e calcolo spesso necessarie per addestrare modelli deep basati su transformer, che hanno faticato in questi dataset scientifici relativamente piccoli.
Perché questo conta per i dati scientifici futuri
Per gli scienziati in cerca di schemi in dati limitati e ad alta dimensionalità, questo lavoro offre un cambio di prospettiva interessante. Invece di indovinare un rango e ottimizzare per la ricostruzione, i ricercatori possono chiedere direttamente un embedding che rifletta le relazioni cui tengono: stessa diagnosi, stessa fase del materiale, stessa classe astrofisica. Il framework no-rank basato su metric learning proposto mostra che tali embedding possono essere sia interpretabili sia potenti, specialmente quando i dati scarseggiano. Come nota l’autore, restano sfide – tra cui gestire squilibri di classe e scalare a molte categorie – ma il messaggio è chiaro: in molti problemi scientifici, apprendere una buona nozione di similarità può essere più prezioso che ricostruire ogni dettaglio del segnale originale.
Citazione: Bagherian, M. No-rank tensor decomposition via metric learning. Sci Rep 16, 8326 (2026). https://doi.org/10.1038/s41598-026-38221-3
Parole chiave: metric learning, decomposizione tensoriale, apprendimento di rappresentazioni, riduzione della dimensionalità, analisi di dati scientifici