Clear Sky Science · it
Metodo di classificazione automatica delle materie prime dei prodotti e‑commerce tramite l’introduzione di concetti self‑supervised e la costruzione di un’ontologia di dominio
Perché ha senso ordinare i prodotti online per ingredienti
Quando compri farina o snack online, di solito cerchi in base alla funzione del prodotto—miscela per torte, farina per pane, ingredienti per la cottura. Ma aziende, enti regolatori e persino consumatori attenti alla salute spesso si interessano di più a ciò di cui quei prodotti sono fatti. I siti di e‑commerce di oggi raramente organizzano i prodotti in base alle materie prime, e sistemare tutto manualmente vorrebbe dire controllare milioni di pagine prodotto una per una. Questo studio propone un metodo automatico per raggruppare i prodotti online in base agli ingredienti sottostanti, usando una combinazione di conoscenza di dominio e apprendimento automatico.
Il problema degli scaffali confusi
Le grandi piattaforme di e‑commerce elencano milioni di articoli e tipicamente li organizzano per funzione: “miscela per dolci” o “snack”, piuttosto che per frumento, grano saraceno o mais. Di conseguenza, due farine ottenute dallo stesso cereale possono finire in categorie diverse, mentre prodotti con ingredienti differenti possono essere raggruppati perché usati per scopi simili. Questo è comodo per chi acquista ma è un problema per commercianti e analisti che vogliono monitorare vendite o qualità per materia prima. I metodi automatici esistenti per lo più replicano le etichette della piattaforma e richiedono molti esempi annotati manualmente, il che è costoso e non risolve la visione basata sugli ingredienti di cui le aziende hanno bisogno.
Costruire una mappa intelligente degli ingredienti
I ricercatori hanno affrontato il problema chiedendo innanzitutto a esperti del settore di progettare una “mappa” strutturata del mondo delle farine, chiamata ontologia di dominio. In termini semplici, si tratta di un elenco accurato di tipi di farina—come frumento, integrale, mais, grano saraceno, riso e riso glutinoso—e delle caratteristiche chiave che li distinguono, tra cui il cereale di origine, la forza del glutine, il grado di qualità, la marca e il luogo di provenienza. Dai veri annunci prodotto su diverse piattaforme cinesi, il team ha quindi raccolto migliaia di frasi concrete che corrispondono a quelle caratteristiche, come nomi di marca o formulazioni tipiche per l’origine. Si sono basati su regole di pattern‑matching e su una misura di distanza tra stringhe per intercettare errori di battitura e sinonimi, ad esempio nomi leggermente diversi per lo stesso tipo di farina, e li hanno incorporati in un elenco di parole specifico per il dominio.
Lasciare che i dati si etichettino da soli
Successivamente, gli autori hanno adattato l’idea dell’apprendimento self‑supervised: invece di chiedere agli esseri umani di marcare ogni campione, hanno lasciato che i dati generassero molte delle proprie etichette. Usando l’ontologia e l’elenco di vocaboli, hanno scritto regole che definiscono come gli attributi degli ingredienti dovrebbero allinearsi a una categoria. Se i dettagli di un prodotto menzionano chiaramente il mais come cereale principale e altri tratti corrispondono al profilo della farina di mais, il sistema considera quell’inserzione un esempio “standard” di farina di mais e accetta automaticamente l’etichetta di categoria. Le inserzioni i cui attributi confliggono con le regole esperte, o sono troppo vaghe, vengono trattate come “non standard” e messe da parte come casi non etichettati. In questo modo il modello raccoglie migliaia di esempi di addestramento puliti direttamente dai dati di catalogo disordinati senza ispezione manuale.
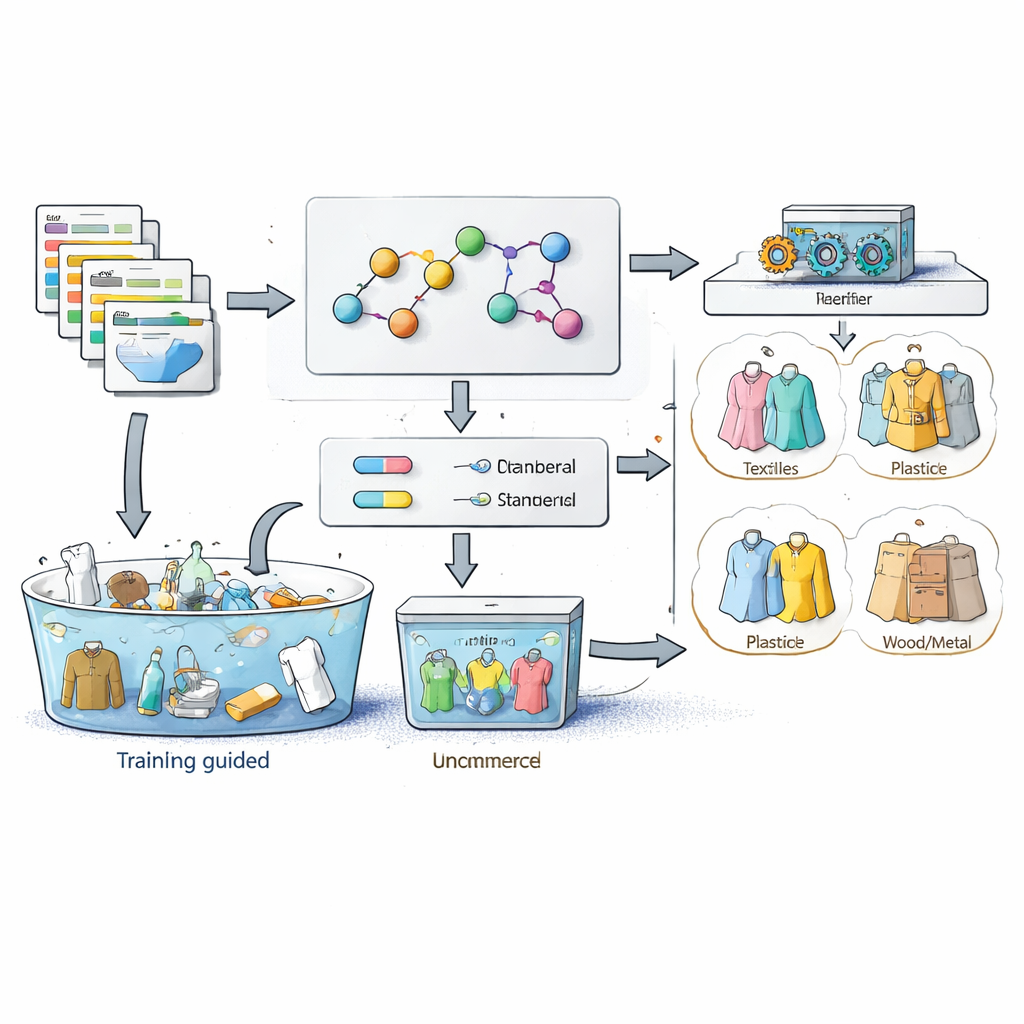
Insegnare al classificatore a riconoscere le materie prime
Con gli esempi standard a disposizione, il sistema converte il testo di ogni prodotto in caratteristiche leggibili dalla macchina. Utilizza un potente modello linguistico, sviluppato originariamente per il testo cinese, per estrarre entità importanti come marche, nomi degli ingredienti e luoghi di provenienza, e le aggiunge all’elenco di vocaboli del dominio. Un tokenizer poi spezza titoli e descrizioni dei prodotti in frammenti significativi, rimuove parole di riempimento comuni e costruisce un profilo numerico dell’importanza relativa di ciascun termine nell’insieme dei dati. Classificatori di machine learning classici vengono allenati su questi profili e sulle categorie di ingredienti assegnate automaticamente. Gli autori hanno testato diversi algoritmi su oltre 18.000 inserzioni di farina e hanno constatato che un modello di regressione logistica, metodo relativamente semplice, offriva il miglior equilibrio tra velocità e accuratezza.
Quanto funziona il sistema—e perché batte l’IA generica
Sui dati di farina raccolti dalle principali piattaforme cinesi, il classificatore basato sugli ingredienti ha raggiunto circa il 91 percento di accuratezza complessiva. Era particolarmente efficace nel riconoscere farine comuni, come la farina di frumento standard e la farina di riso glutinoso, e ha mostrato prestazioni tuttora buone su categorie più ostiche come il grano saraceno e il mais, dove i prodotti spesso mescolano cereali. L’aggiunta dell’elenco di vocaboli specifico per il dominio ha chiaramente migliorato i risultati rispetto all’uso esclusivo di feature testuali generiche. Il team ha inoltre confrontato il loro metodo con un grande modello linguistico generalista, incaricato di svolgere lo stesso compito senza un addestramento preventivo sul dataset. Quel modello zero‑shot è rimasto indietro, soprattutto sulle tipologie di farina più rare, sottolineando il vantaggio di combinare conoscenza esperta con apprendimento mirato invece di affidarsi solo a una comprensione linguistica ampia ma superficiale.
Cosa significa per lo shopping online e oltre
In termini pratici, lo studio mostra che le piattaforme e‑commerce possono automaticamente riorganizzare gli articoli in base a ciò di cui sono fatti, non solo a come vengono usati. Incapsulando la conoscenza esperta sugli ingredienti in una mappa riutilizzabile e lasciando che le pagine prodotto si etichettino da sole, l’approccio riduce drasticamente la necessità di etichettatura manuale mantenendo alta l’accuratezza. Per commercianti e analisti, questo apre la strada a statistiche di vendita più pulite, un migliore controllo qualità e risposte più precise a problemi come il tracciamento degli allergeni o le tendenze nutrizionali. Sebbene dimostrato sulla farina, la ricetta—ontologie costruite da esperti più regole di auto‑etichettatura e classificatori leggeri—potrebbe essere adattata a molte altre categorie di prodotto dove le materie prime contano davvero.
Citazione: Lei, B., Wang, J. & Shen, C. Automatic classification method of e-commerce commodity raw materials through the introduction of self-supervised concepts and the construction of domain ontology. Sci Rep 16, 8058 (2026). https://doi.org/10.1038/s41598-026-38214-2
Parole chiave: classificazione e‑commerce, ingredienti dei prodotti, apprendimento self‑supervised, ontologia di dominio, text mining